基于GPUStack搭建昇腾模型服务管理平台参考实践
发表于: 2025/12/10
1 非商用声明
本文档提供的内容为参考实践,仅供用户参考使用,用户可参考文档构建自己的软件,按需进行安全、可靠性加固,但不建议将相关Demo或镜像文件直接集成到商用产品中。
2 方案介绍
2.1 背景
随着大模型相关技术的发展,大模型部署成本逐渐降低,LLM、VLM等类型的模型被应用到千行百业中,推动行业效率和创新升级。由于大模型的私有化部署和运维还存在一定的门槛和成本,中小企业客户往往没有单独的部门组织专门承担模型部署和运维的工作,需要一个简单易上手的模型服务管理平台,帮助客户快速部署模型并提供模型服务给应用开发人员对接使用。
2.2 方案简介
GPUStack作为一款开源的可用于运行AI 模型的推理集群管理软件,具有广泛的推理硬件设备兼容性、广泛的模型支持,灵活的推理后端支持等特点,非常适合在中小企业作为模型服务管理平台的参考软件使用。
本文档基于GPUStack开源版本结合昇腾推理解决方案,给出典型配置和部署方案,提供基于昇腾NPU卡的模型管理、模型部署、服务调用等的使用参考实践,降低学习成本,另外GPUStack也提供企业版,用户可按需选择或者基于开源版本进行加固和产品化。支持的关键特性如下:
1. 支持推理硬件:支持Atlas 800I A2、Atlas 300I A2、Atlas 300I Duo等,支持一个集群异构管理不同的昇腾推理设备;
2. 支持推理引擎:支持MindIE、vLLM、SGLang等推理后端;
3. 支持模型范围:支持DeepSeek R1/V3、Qwen等大语言模型(LLM),支持Qwen2.5-VL等多模态语言模型(VLM),支持Qwen3-Embedding等嵌入类模型,支持bge-m3-reranker等重排序模型,具体请以MindIE和vLLM Ascend的模型支持列表为准。
4. 支持部署场景:支持单卡、多卡、多机推理部署等部署场景,支持量化、PrefixCache等特性。
2.3 应用场景
本参考实践主要应用于模型快速部署上线和运维的场景,使用GPUStack开源软件搭配昇腾推理解决方案,作为构建模型服务管理平台的参考。
2.4 部署方案
2.4.1 典型硬件配置
节点类型 | 服务器配置 | 数量 | 部署内容/作用 |
|---|---|---|---|
数据库节点 | 推荐使用容器部署,数据库节点的部署配置推荐如下: | 2 | 部署PostgreSQL\MySQL集群。 |
管理节点 | 推荐使用容器部署。 ● 混合部署场景,推荐Server节点独立容器部署,部署到其中一台推理服务器上,推荐配置为4C8G。 ● 分离部署场景,推荐Server节点独立容器部署,部署到独立的通算服务器上,推荐配置8C16G。 存储配置以实际业务需求为准(如果无外接分布式存储,建议预留充足的本地磁盘存储空间,用于存放模型权重,模型兼容性评估时使用)。 | 1 | 部署GPUStack Server,用于模型管理、调度、提供web界面等功能。 |
推理节点 | 集群管理的所有的推理服务器。推理服务器可选如下设备: ● Atlas 800 3000推理服务器(搭载Atlas 300I Duo标卡); ● Atlas 800I A2推理服务器; ● 或其他满足昇腾硬件兼容性要求的整机设备(搭载昇腾Atlas 300I A2/Atlas 300I Duo等标卡)。 推理服务器上需要部署2个关键组件: 1. GPUStack Worker:建议采用容器部署,部署配置推荐如下: | ≥1(以实际业务需求为准) | 推理节点上有2个主要角色: |
2.4.2 软件版本
本参考实践使用的软件配套版本如下,用户可以参考GPUStack的要求验证自己需要的软件版本:
软件 | 版本 | 说明 |
|---|---|---|
GPUStack | 2.0.1 | |
PostgreSQL | 16.10 | 要求:PostgreSQL 13.0+或MySQL 8.0+ |
MindIE | 2.1.RC2、2.1.RC1 | 昇腾推理引擎,runner镜像中已包含 |
vLLM、vLLM Ascend | 0.11.0 | 推理服务化框架,runner镜像中已包含 |
SGLang | 0.5.2 | 推理服务化框架,runner镜像中已包含 |
Ascend Extension for PyTorch | 2.7.1 | 昇腾torch_npu插件,runner镜像中已包含 |
CANN | 8.2.RC2、8.3.RC1 | 昇腾异构计算架构,runner镜像中已包含 |
Ascend HDK | 25.0.RC1.1 | NPU驱动固件,要求能配套CANN版本使用,物理机上安装 |
Docker | 18.09.0 | 物理机上安装 |
OS | openEuler release 22.03 (LTS-SP4) | 物理机OS |
说明:
运行GPUStack 2.0的要求参考链接:https://docs.gpustack.ai/2.0/installation/requirements/。
2.4.3 部署方案
根据部署的推理集群规模,提供以下两种推荐部署方案,其中AI推理服务器的组网请参考昇腾推理解决方案组网。
2.4.3.1 混合部署
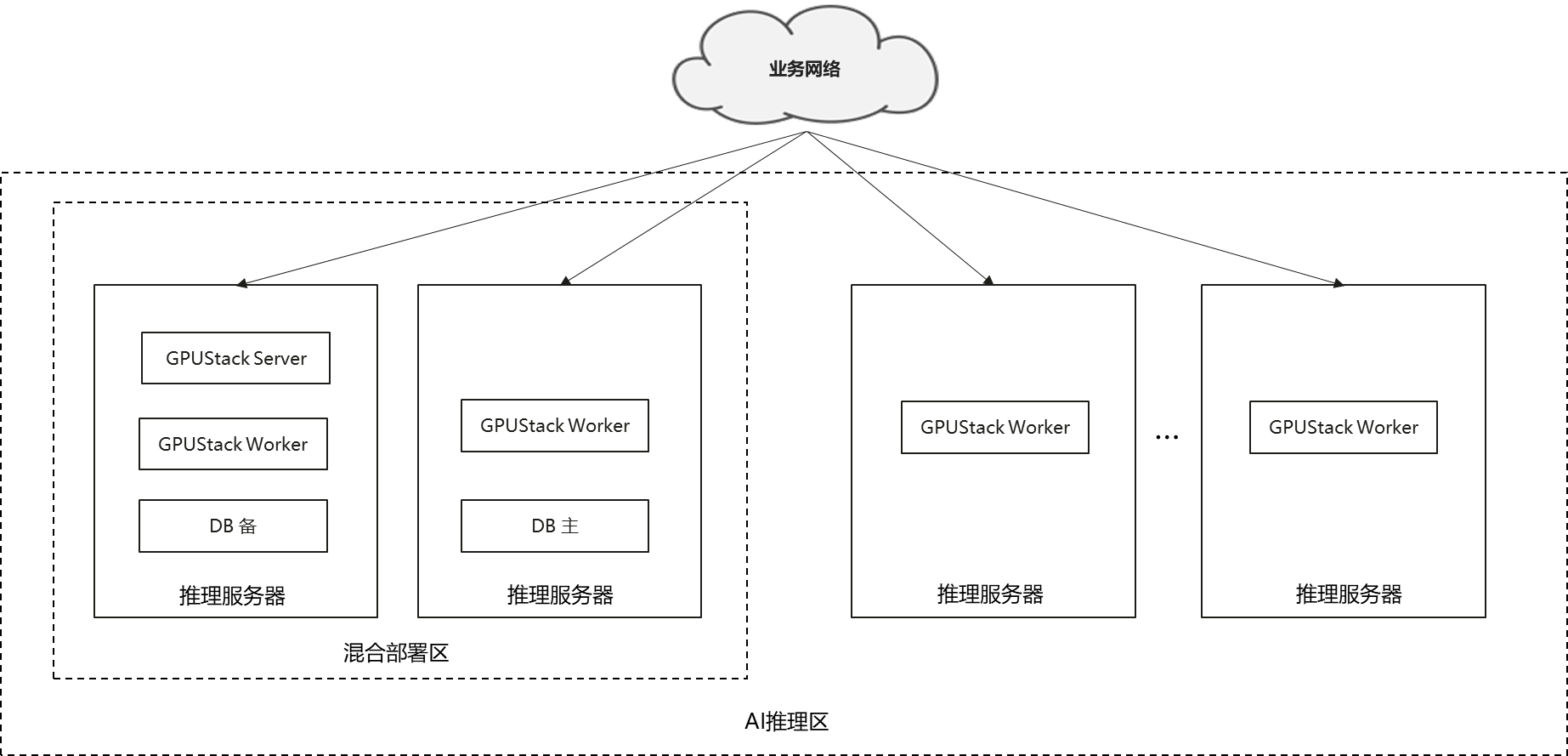
当集群规模小于8台推理服务器时,建议采用混合部署方案。混合部署,是指GPUStack Server、DB、GPUStack Worker共用推理服务器节点,从而达到节省部署成本的目的。各个组件均推荐采用容器部署,不同节点上部署的容器如下图,其中DB、Server和Worker容器可按照硬件典型配置中的最低配置部署(4C8G)。
图1 混合部署方案图
2.4.3.2 分离部署
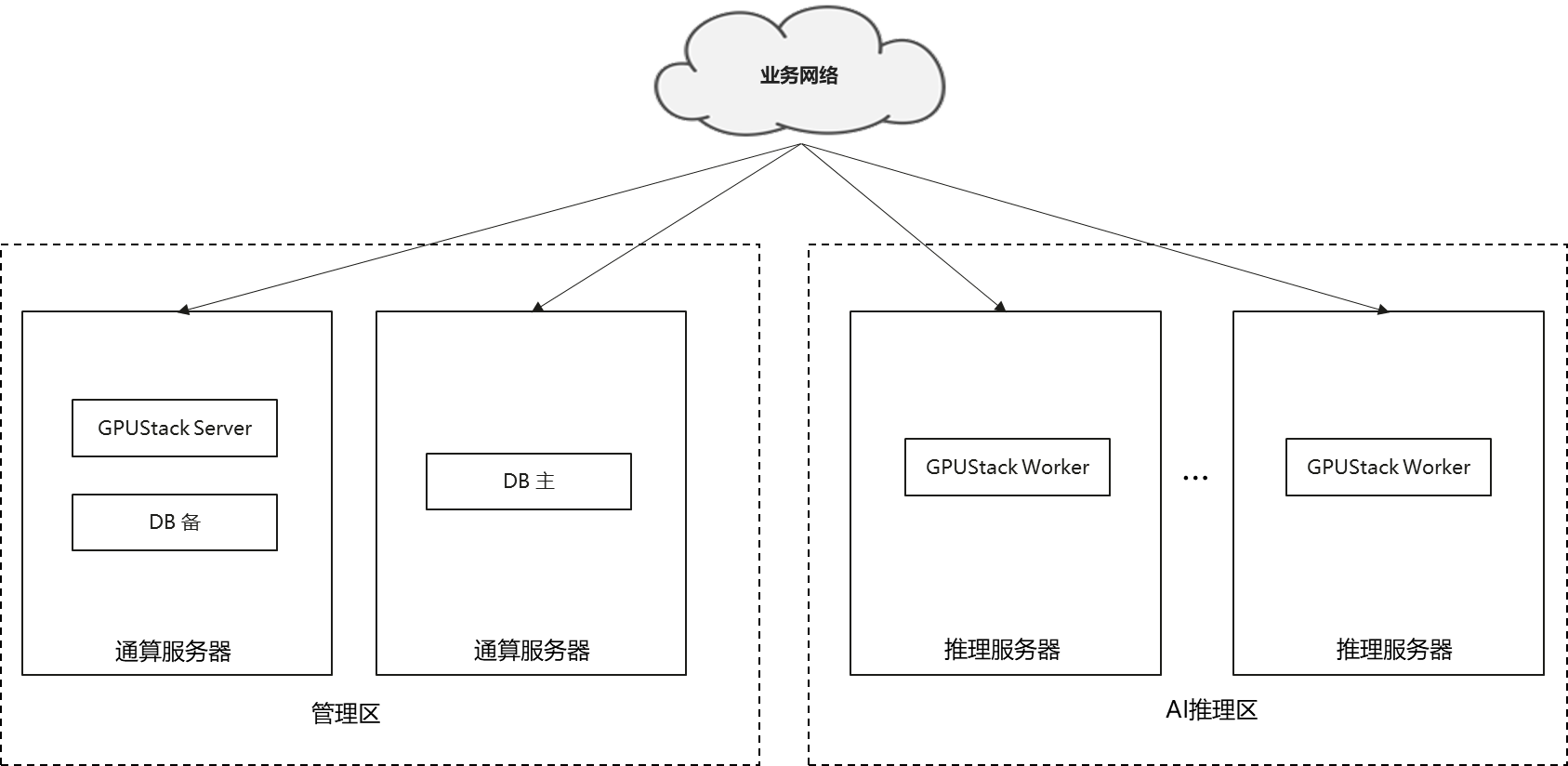
当集群规模为8~16台推理服务器时,建议采用分离部署方案。分离部署,是指GPUStack Server、DB单独采用通算物理机资源,从而达到管理区和AI推理区隔离的效果,提升方案安全性和可靠性。该方案下,各个组件均推荐采用容器部署,不同节点上部署的容器如下图,GPUStack Server建议配置为8C16G,DB、GPUStack Worker建议配置为4C8G。
图2 分离部署方案图
说明:
开源版本GPUStack Server暂无高可用部署方案,如对GPUStack Server有高可用需求,建议自行进行加固或者使用GPUStack企业版。
3 部署指导
3.1 前置条件
1. 已完成OS、Docker安装;
2. 参考对应昇腾版本和设备的《昇腾软件安装指南》,推理服务器完成昇腾驱动和固件安装,参考链接;
3. 参考《MindCluster产品文档》,推理服务器完成Ascend Docker Runtime安装,参考链接;
4. 参考GPUStack文档,确保机器间的网络连接符合要求,机器上预留需要使用的端口,参考链接。
3.2 获取GPUStack的镜像包
# 获取GPUStack2.0.1版本镜像
docker pull gpustack/gpustack:v2.0.1
docker pull gpustack/runtime:pause
docker pull gpustack/runtime:health
# 查看GPUStack的镜像列表
docker run --rm --entrypoint "" gpustack/gpustack:v2.0.1 gpustack list-images
# 按需下载需要的推理后端镜像, 版本号以实际为准,可以通过gpustack list-images命令获取具体的镜像tag
docker pull gpustack/runner:cann{cann_version}-{soc_version}-vllm{version}
docker pull gpustack/runner:cann{cann_version}-{soc_version}-mindie{version}
docker pull gpustack/runner:cann{cann_version}-{soc_version}-sglang{version}
...说明:
1、如果机器上导入runtime/runner镜像后镜像名称与gpustack list-images命令回显的不一致,请通过docker tag修改到与gpustack list-images一致,否则部署模型时会联网下载镜像。
2、如果从Docker Hub下载镜像缓慢,可以使用镜像网站quay.io。
3.3 数据库安装
当前GPUStack支持的数据库包括PostgreSQL 13.0+和MySQL 8.0+,镜像中默认内置PostgreSQL,但从高可靠性上考虑,建议使用高可靠部署的DB,比如主备部署的PostgreSQL等,具体安装方法请以PostgreSQL和MySQL官方文档为准。
3.4 安装Server节点
开源版本的GPUstack Server节点不支持主备部署等高可用方案,只能部署单机GPUStack Server。为保证数据持久化的高可靠性,推荐GPUStack Server对接外部高可用部署的数据库实例。GPUStack Server在混合部署场景下推荐配置为4C8G,在分离部署场景下推荐配置为8C16G。参考启动命令如下:
# 拉起GPUStack Server示例,请按需修改你的启动命令
# 如果想使用嵌入式的PostgreSQL,不指定database-url参数,默认拉起Server时拉起单机PostgreSQL进程
# GPUStack进程目录按实际情况配置,这里以/data/gpustack-data-2.0为例
# 模型权重路径按实际情况设置,这里以/path/to/model_files为例,用于Server节点做模型兼容性评估
docker run -d --name gpustack-server \
--cpus=4 \
-m 8g \
--restart=unless-stopped \
-p 80:80 \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume /data/gpustack-data-2.0:/var/lib/gpustack \
--volume /path/to/model_files:/path/to/model_files:ro \
gpustack/gpustack:v2.0.1 \
--database-url postgresql://user:password@host:port/db_name参数说明详见链接。
可以通过docker logs -f gpustack-server命令查看日志,当日志提示“GPUStack Server is ready.”时表示GPUStack Server启动完成。
通过如下命令获取admin默认密码,使用admin账号登录http://gpustack_server_ip:port/访问GPUStack控制台页面,首次登录后需要修改密码。
docker exec -it gpustack-server cat /var/lib/gpustack/initial_admin_password说明:
如果你的GPUStack Server容器拉起失败,查看日志发现提示"[INFO] gateway exited with code 1, shutting down all services...",可以在启动容器时通过指定--debug开启debug日志打印,当发现DEBUG日志中存在信息“DEBUG - Waiting for ports 80 to be healthy (attempt 2) due to: Port 80 is not healthy or not listen...”,重试次数达到30次时,可以参考如下方式规避:
1. 执行命令进入容器
docker exec -it gpustack-server bash2. 修改超时时间和重试次数
sed -i 's; 60; 1800;g' /etc/s6-overlay/s6-rc.d/gateway/run
sed -i 's;tenacity.stop_after_attempt(30);tenacity.stop_after_attempt(300);g' /usr/local/lib/python3.11/dist-packages/gpustack/server/server.py3. 重启容器
docker restart gpustack-server4. 耐心等待出现GPUStack Server is ready的日志,即表示启动成功。
该问题预计在2.0.2版本会有优化,详细信息参考issue:https://github.com/gpustack/gpustack/issues/3779#issuecomment-3632481575
3.5 添加worker节点
添加worker节点的步骤如下:
1. 使用管理员账号登录GPUStack控制台页面。
2. 进入“集群管理”->“集群”页面,点击“添加集群”,基本配置选择“自建环境”->“Docker”,点击“下一步”,输入集群名称,点击“保存”,点击“暂且跳过”跳过节点添加。
3. 进入“资源”->“节点”页面,点击“添加节点”按钮,选择集群为步骤2中创建的集群,选择GPU厂商为“昇腾”,按照指引进行环境检查,确保环境检查都为“OK”,在“指定Worker IP”中填写Worker节点IP地址,并添加需要额外挂载的磁盘路径,点击“下一步”。
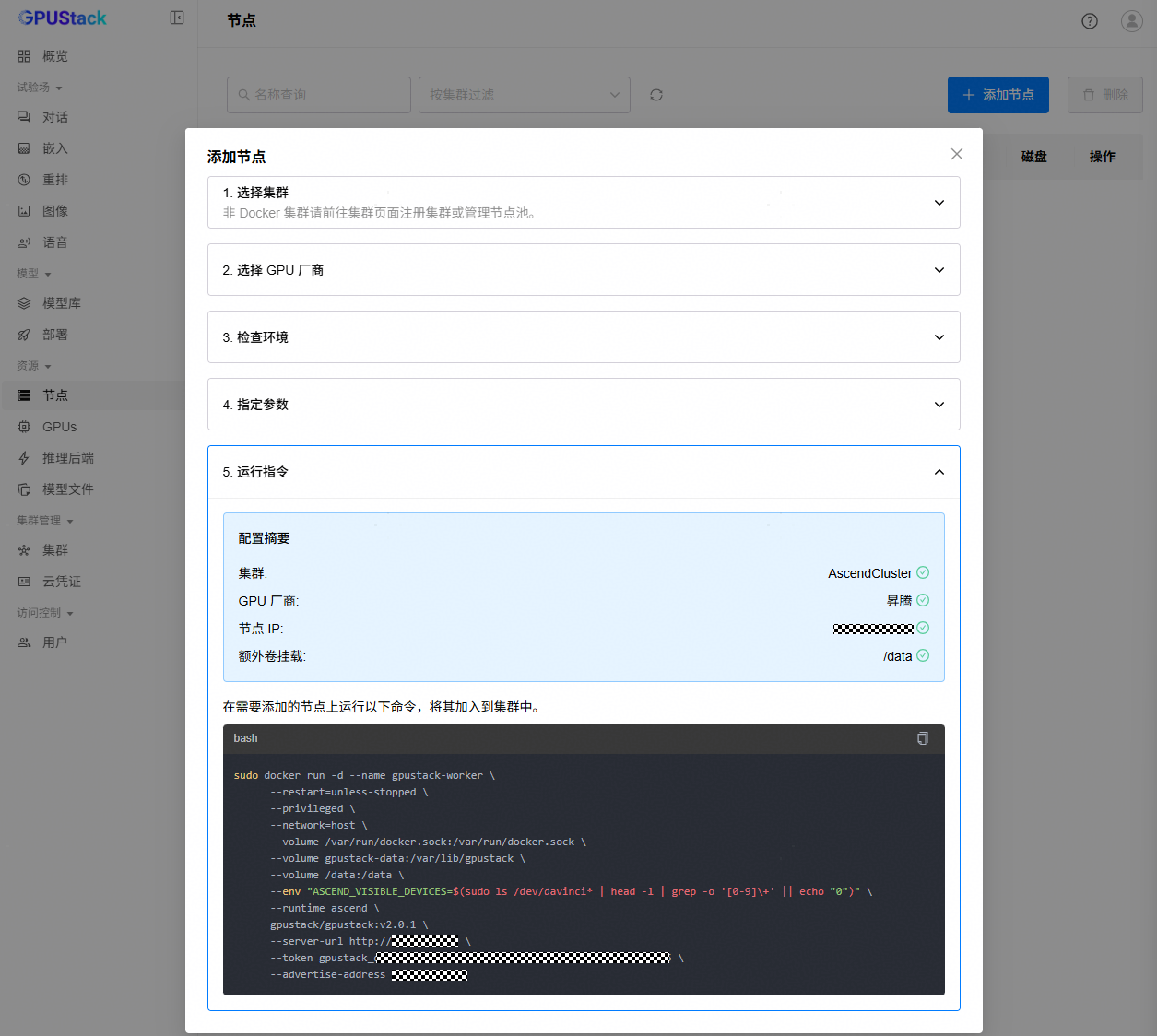
4. 复制页面提示的命令,按实际情况修改进程目录,到指定的Worker节点执行命令启动Worker容器,将Worker节点加入集群。拉起Worker容器后,可以通过docker logs查看日志,观察是否有报错信息,确保worker节点添加成功。
5. 等待容器拉起完成,登录GPUStack控制台页面,进入“资源”->“节点”,点击节点列表的刷新按钮,即可看到新的worker,状态为Ready表示Worker节点正常。

6. 按照上述步骤将其他推理节点逐个加入集群。
说明:
1、混合部署场景下,为确保Server与Worker进程间的文件隔离,建议为它们分别新建独立的目录,在创建容器的docker命令中通过--volume将对应的绝对路径挂载至容器的 /var/lib/gpustack 目录下,避免文件冲突。如下为示例:
--volume /data/gpustack-data-2.0-worker:/var/lib/gpustack \
2、GPUStack也支持通过Docker Compose方式部署,该方式拉起Server时默认会同时拉起Prometheus和Grafana,支持将采集的指标信息上报到Prometheus并在Grafana仪表板上可视化展示。使用方法参考官方文档https://docs.gpustack.ai/2.0/installation/installation/。
4 平台使用指导和参考实践
4.1 用户管理
当前仅支持两种角色的用户:管理员和普通用户,管理员具有Web界面全部功能,普通用户仅有“试验场”和查看模型列表的功能。管理员可以进入“访问控制”->“用户”,点击“添加用户”按钮新建用户,指定初始密码。新用户可以使用密码登录Web页面,首次登录需要修改密码。
4.2 模型管理
模型管理支持以下两种方式:
1. 使用模型库
如果GPUStack server所在机器已联网,可使用模型库中的模型直接进行部署,在线模型库默认提供了针对模型的优化参数配置,进入“模型”->“模型库”页面后选择需要的模型,会进行模型评估,评估通过后,选择保存模型,GPUStack将自动从HuggingFace或者ModelScope下载模型文件并进行部署。
离线环境也可以使用模型库,需要通过YAML文件定制模型库,配置模型的本地路径,详细方法请查阅GPUStack产品文档,点击链接可前往查看。
2. 将本地路径的模型文件添加到 UI 中统一管理
进入“资源”->“模型文件”页面,点击“添加模型文件”,选择“本地路径”,填写模型权重路径,选择节点,点击保存即可。请保证worker节点和server节点在相同路径下都有权重文件,以确保GPUStack Server调度策略的正确性,如有条件,可以将Server和Worker对接到高性能分布式存储。

本文档将会以本地路径方式,提供模型部署流程的指导。
4.3 模型部署
本章将会以离线环境下已经异构管理多种昇腾推理设备(Atlas800I A2、Atlas300I Duo等)的推理集群作为示例,模型文件使用本地路径的方式,通过不同模型的部署过程,来展示不同推理后端、不同类型模型的部署流程。本章中展示的例子仅作为开箱使用参考,如果用户对模型的输入输出长度、性能、模型部署的调度等等有自定义的需求,可以按照产品文档增加和修改配置参数,各个推理引擎后端支持的参数和详细说明具体可参考GPUStack产品文档,点击链接前往查看。
说明:
通过本地文件部署模型,默认在节点选择器中会使用worker-name字段指定特定节点来保证调度准确性。如果希望模型实例能在节点间发生故障转移,请确保集群中的所有节点的同个路径下均存在模型文件,并在部署时将worker-name标签从节点选择器中删除。
4.3.1 使用MindIE在Atlas 300I Duo上单芯片部署Qwen2.5-Coder-14B-Instruct(BF16)
4.3.1.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.1.2 操作步骤
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮;

2. 填写实例名称,选择部署集群,选择后端为“MindIE”,按需配置调度策略,这里可以手动选择要部署的芯片,或者根据模型评估的显存占用需求,默认也会自动调度使用其中1张芯片(48GB)进行部署。高级设置中选择模型类别为“LLM“,等待模型兼容性检查通过,点击“保存”按钮。如Server节点上不存在模型文件,会提示告警信息,可能会影响调度的准确性。
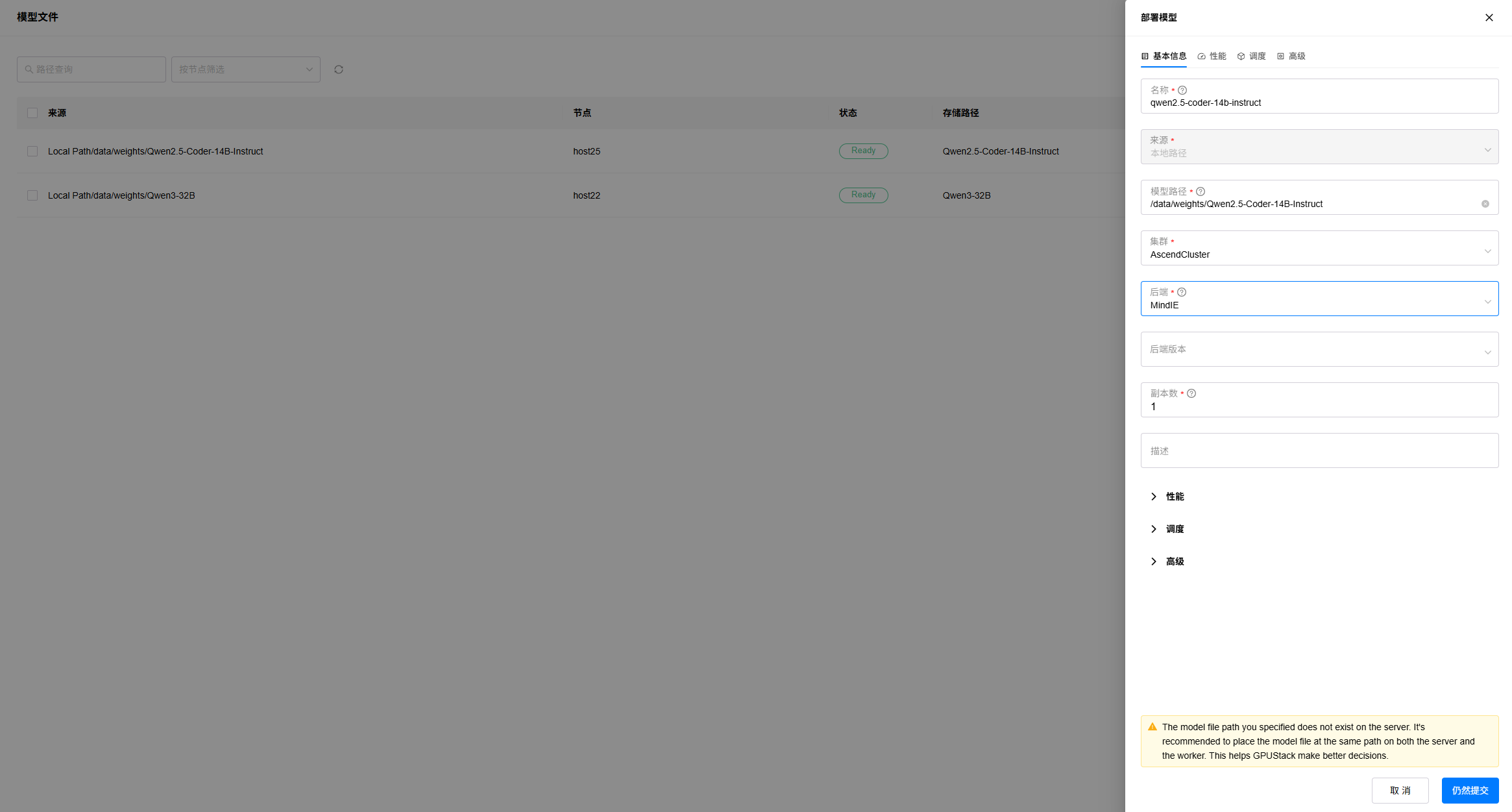
3. 进入“模型”->“部署”页面,查看模型部署状态,状态变为Running时表示部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。

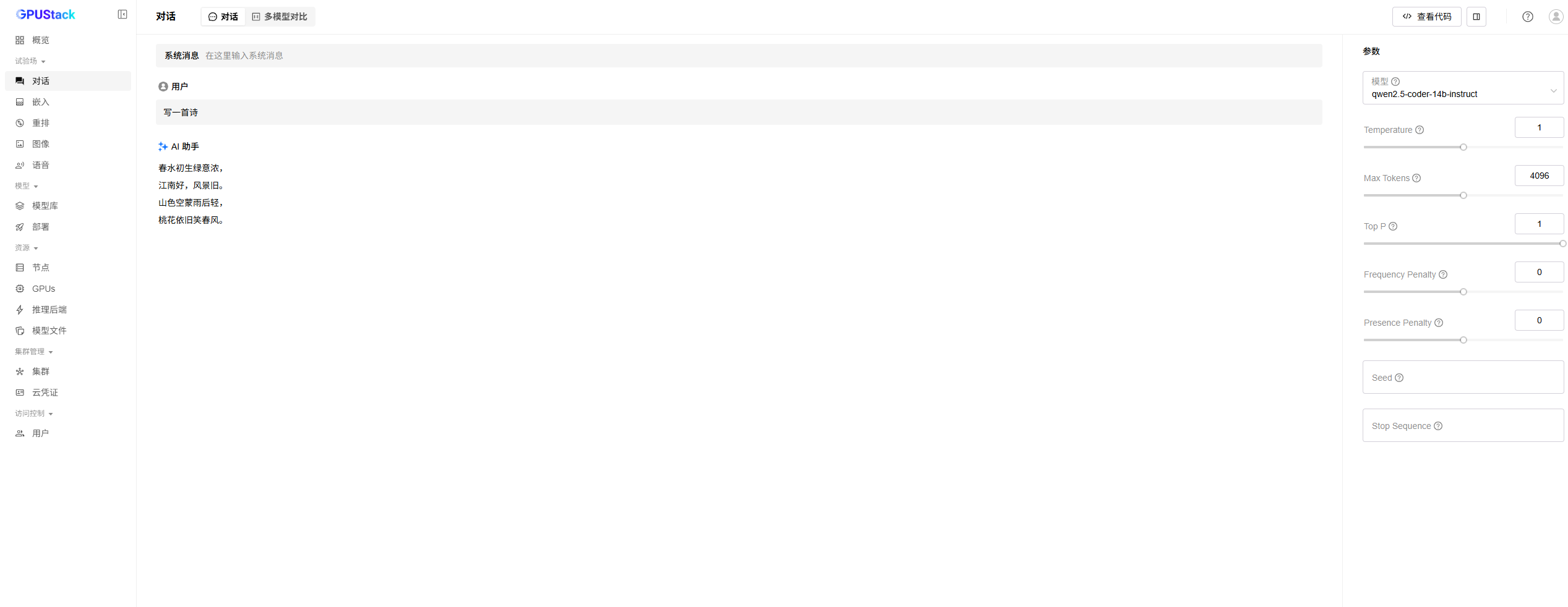
4. 进入“试验场”->“对话”页面,选择已经部署的LLM模型,进行对话测试,验证模型部署成功,效果如下:
4.3.2 使用MindIE在Atlas 300I Duo上单芯片部署Qwen2.5-VL-7B-Instruct(BF16)
4.3.2.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.2.2 操作步骤
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮;

2. 填写实例名称,选择部署集群,选择后端为“MindIE”,按需配置调度策略,可以手动选择要部署的芯片,或者根据模型评估的显存占用需求,默认也会自动调度使用其中1张芯片(48GB)进行部署。等待兼容性检查通过,点击“保存”按钮开始部署模型。
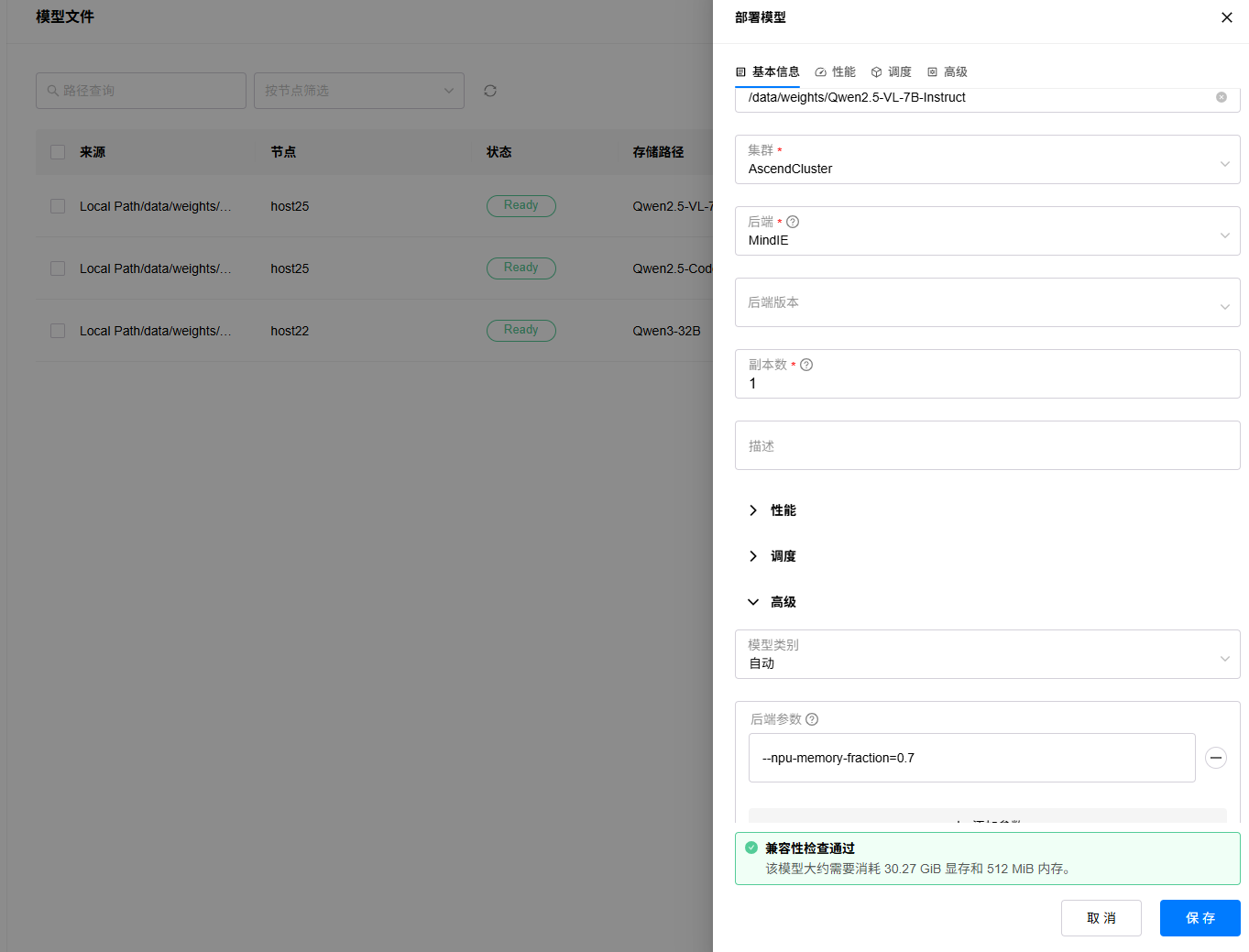
3. 进入“模型”->“部署”页面,查看模型部署状态,状态变为Running时表示部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
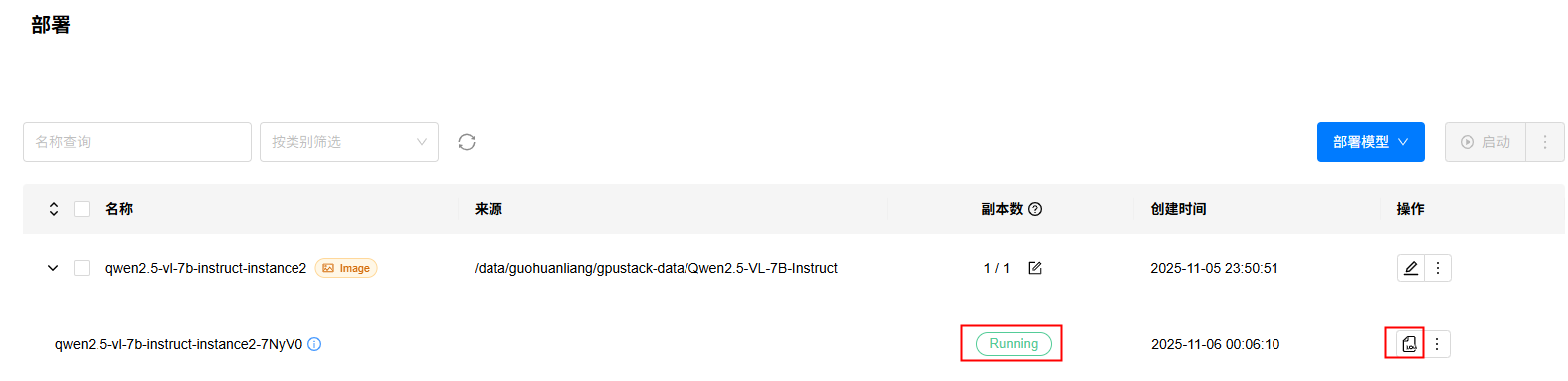
查看部署实例,可以看到模型实例部署的机器、卡号、服务端口等信息:

4. 进入“试验场”->“对话”页面,选择已经部署的VLM模型,点击上传图片按钮上传图片,并输入文本进行对话测试,验证模型部署成功,效果如下:
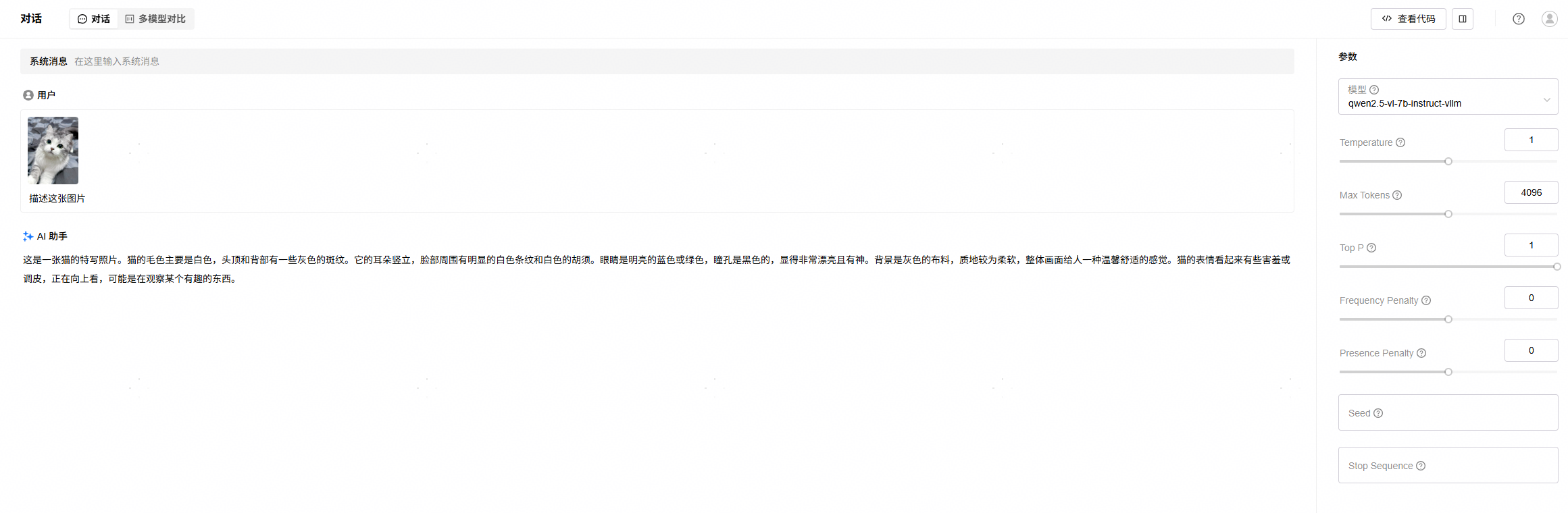
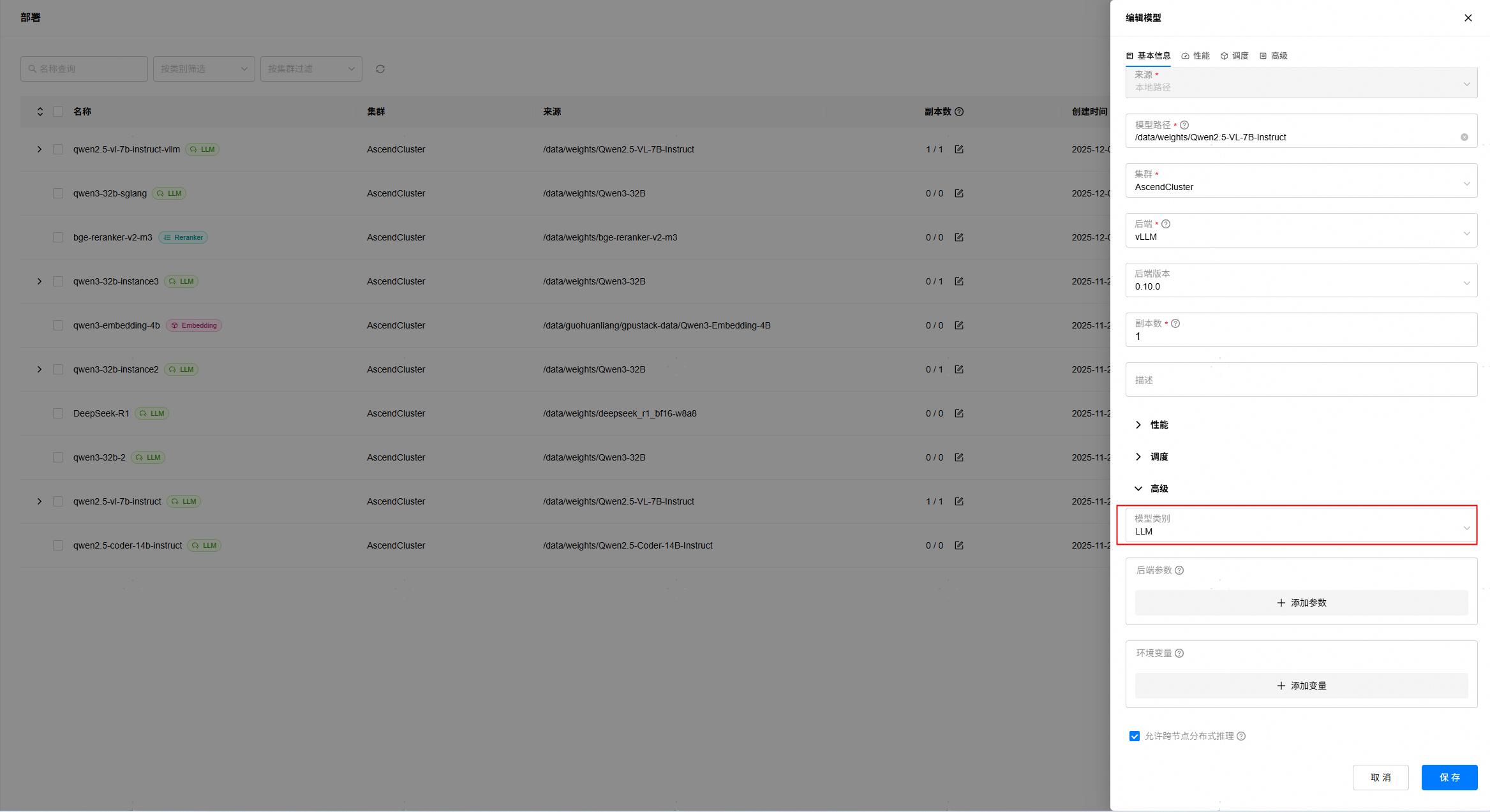
如果在“对话”页面无法选择已经部署的VLM模型,请前往模型部署页面,修改模型类别为LLM,如下:
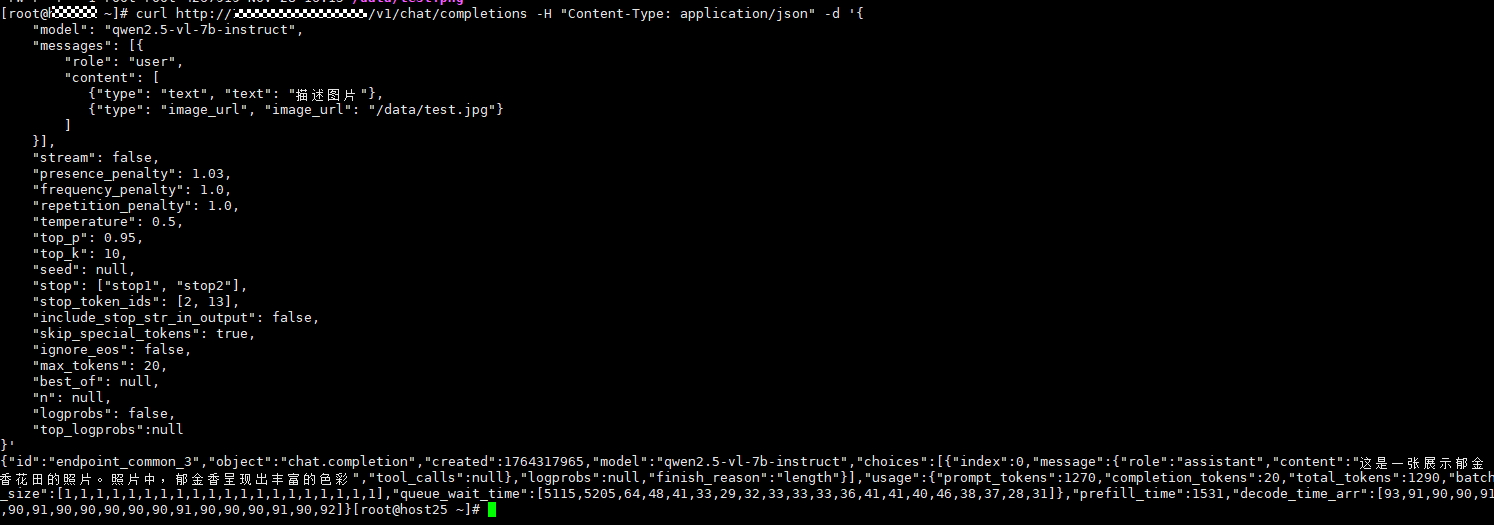
5. 也可以通过curl命令等方式调用验证模型部署成功,这里可以使用模型部署实例页面获取到的ip和端口:
# 参考命令,按需修改
curl http://{ip}:{port}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "qwen2.5-vl-7b-instruct",
"messages": [
{"role": "user",
"content": [{"type": "text", "text": "描述图片"},{"type": "image_url","image_url": "/xx/test.png"}]
}],
"stream": false,
"presence_penalty": 1.03,
"frequency_penalty": 1.0,
"repetition_penalty": 1.0,
"temperature": 0.5,"top_p": 0.95,
"top_k": 10,
"seed": null,
"stop": ["stop1", "stop2"],
"stop_token_ids": [2, 13],
"include_stop_str_in_output": false,
"skip_special_tokens": true,
"ignore_eos": false,
"max_tokens": 20,
"best_of": null,
"n": null,
"logprobs": false,
"top_logprobs":null}'查看返回结果确认模型实例可正常使用:
4.3.3 使用MindIE在Atlas 800I A2上双卡部署Qwen3 32B(BF16)
4.3.3.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.3.2 操作步骤
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮;

2. 填写实例名称,选择部署集群,选择后端为“MindIE”,配置调度策略,可以手动选择要部署的两张卡,或者根据模型评估的显存占用需求,默认也会调度使用2张卡(64GB*2)部署,可自定义设置后端高级参数,比如开启prefix cache功能等。
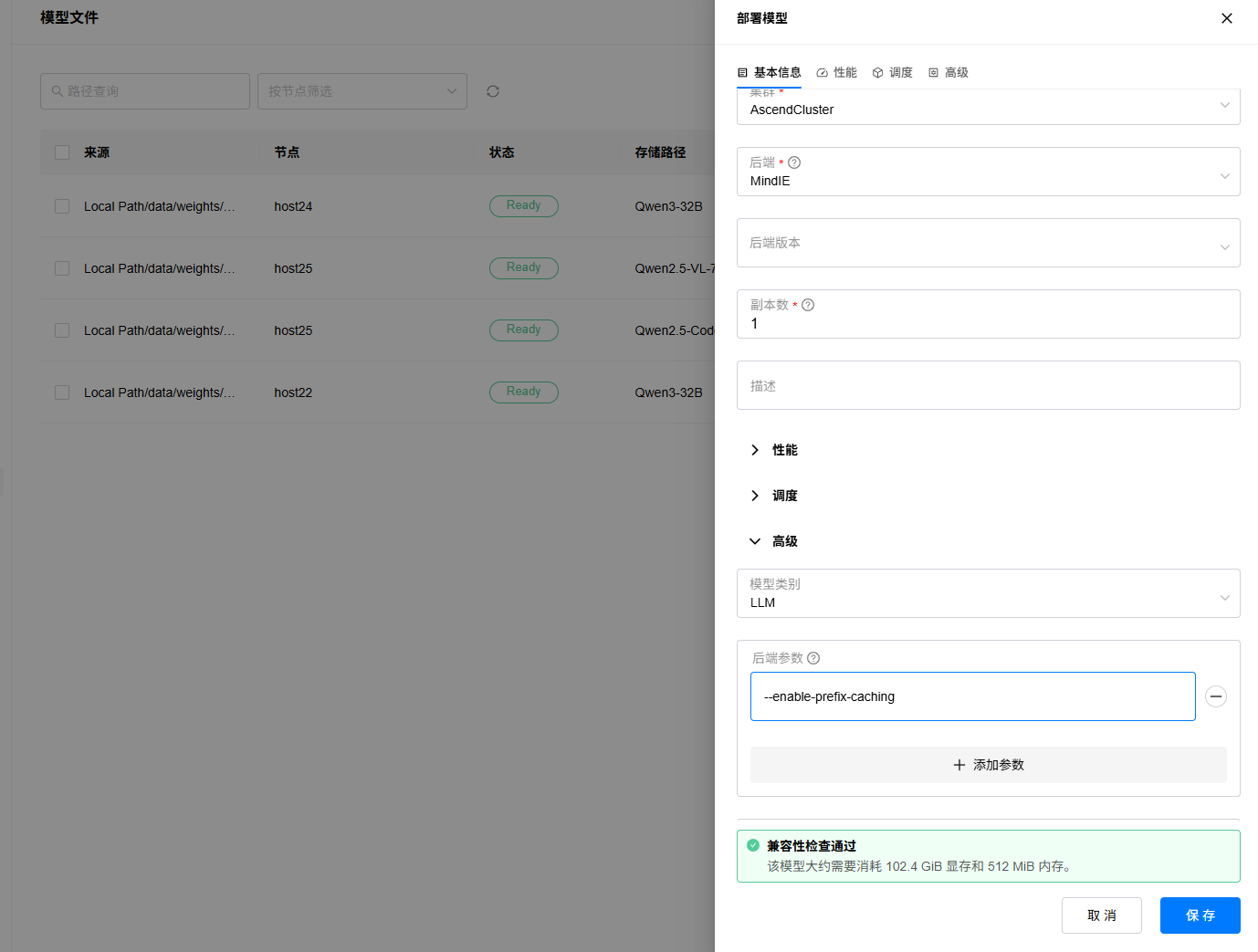
3. 进入“模型”->“部署”页面,查看模型部署状态,状态变为Running时表示部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
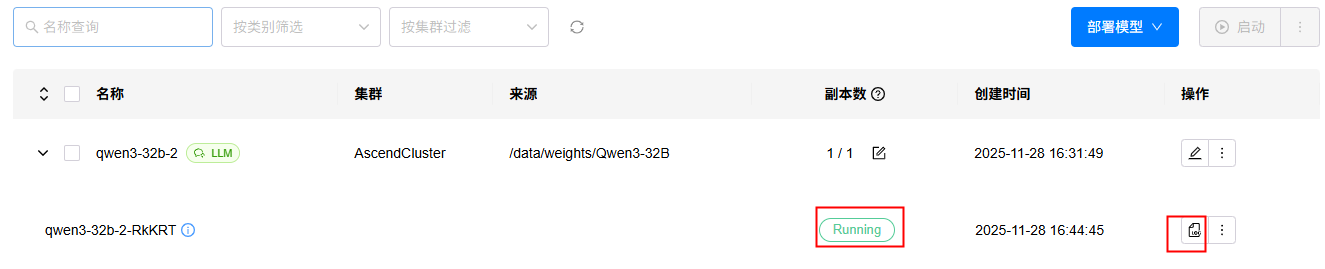
4. 进入“试验场”->“对话”页面,选择已经部署的LLM模型,进行对话测试,效果如下:
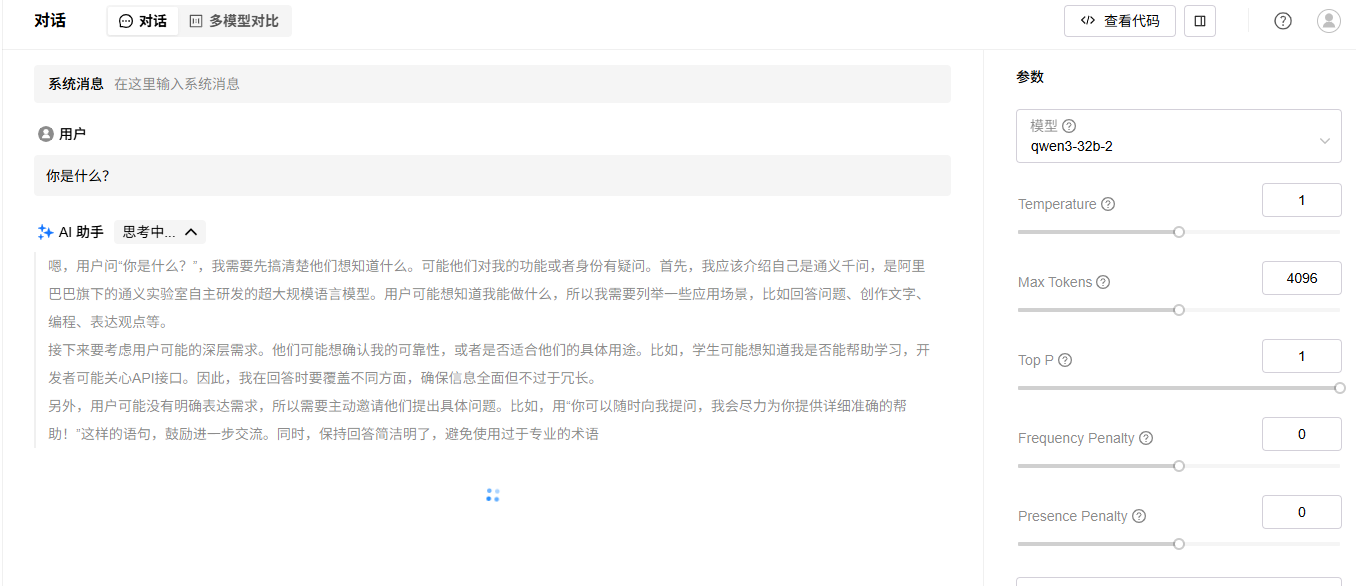
4.3.4 使用MindIE在Atlas 800I A2上双机部署DeepSeek R1满血版(W8A8)
4.3.4.1 前置条件
1. 按照昇腾多机推理组网要求完成组网配置,参考链接。
2. 已下载模型文件上传到昇腾推理服务器上,模型权重可从Hugging Face等社区下载后按照昇腾msmodelslim工具要求,完成权重转换为BF16,并进行W8A8量化,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.4.2 操作步骤
1. 进入“部署”页面,点击“部署模型”按钮,选择本地文件:
2. 填写实例名称和模型路径,选择部署集群,后端选择“MindIE”,副本数为“1”,调度方式选择“手动”,勾选要部署的两台Atlas800I A2(64GB)机器,并在后端参数中添加如下参数,等待模型兼容性检查通过,点击“保存”按钮:
# 如下参数为双机部署DeepSeek R1 W8A8满血版的推荐参数
--trust-remote-code
--tensor-parallel-size=8
--data-parallel-size=2
--moe-tensor-parallel-size=4
--moe-expert-parallel-size=4
--npu-memory-fraction=0.9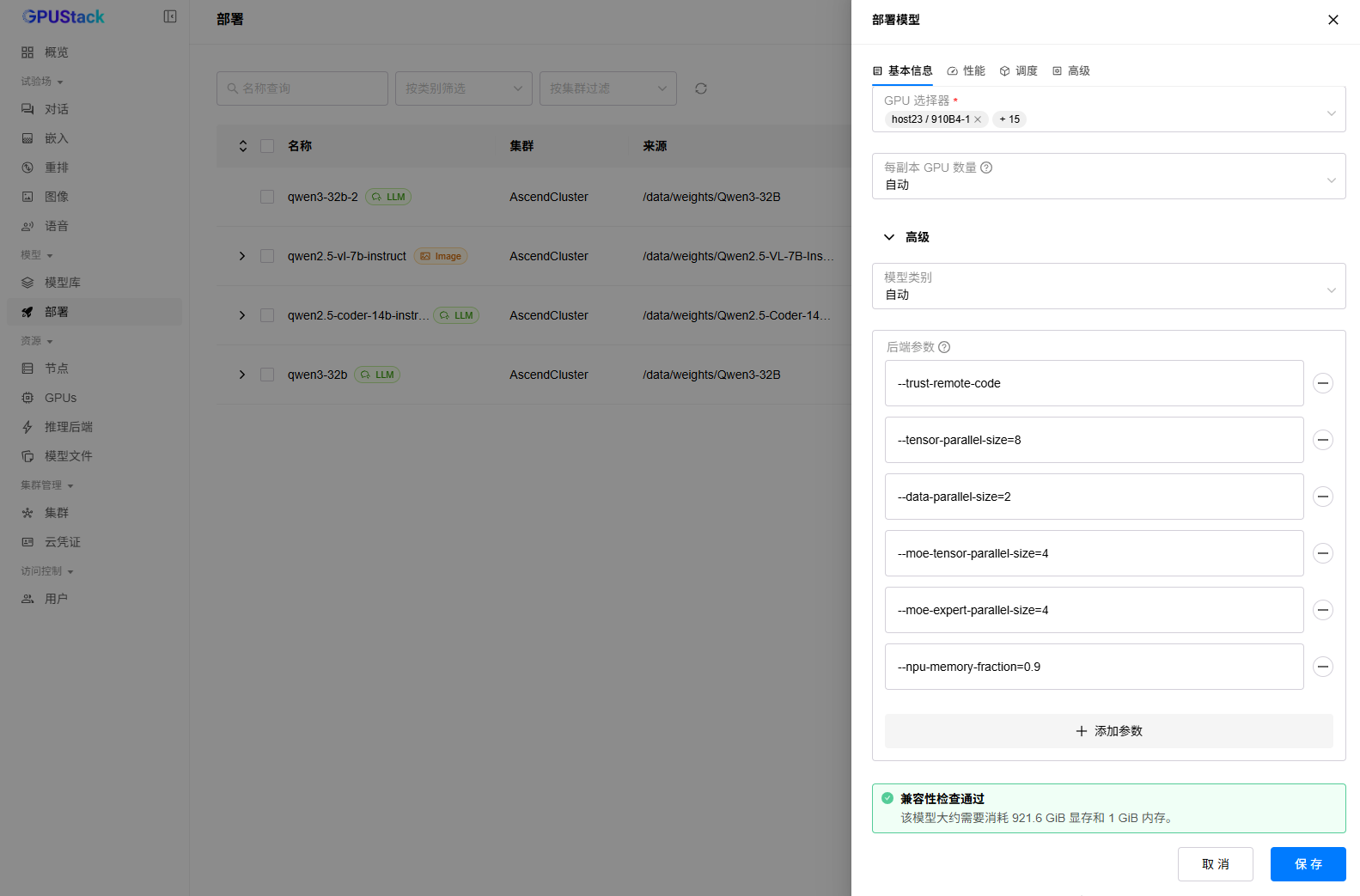
3. 等待模型部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
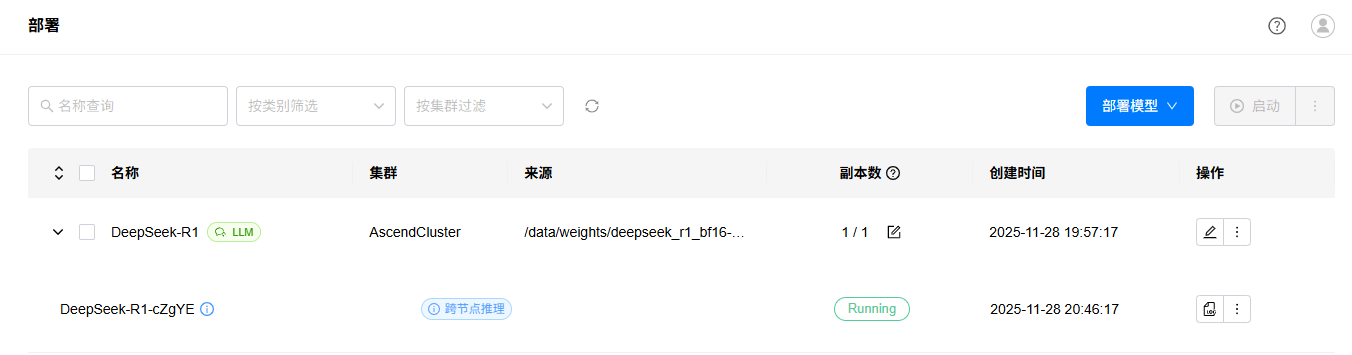
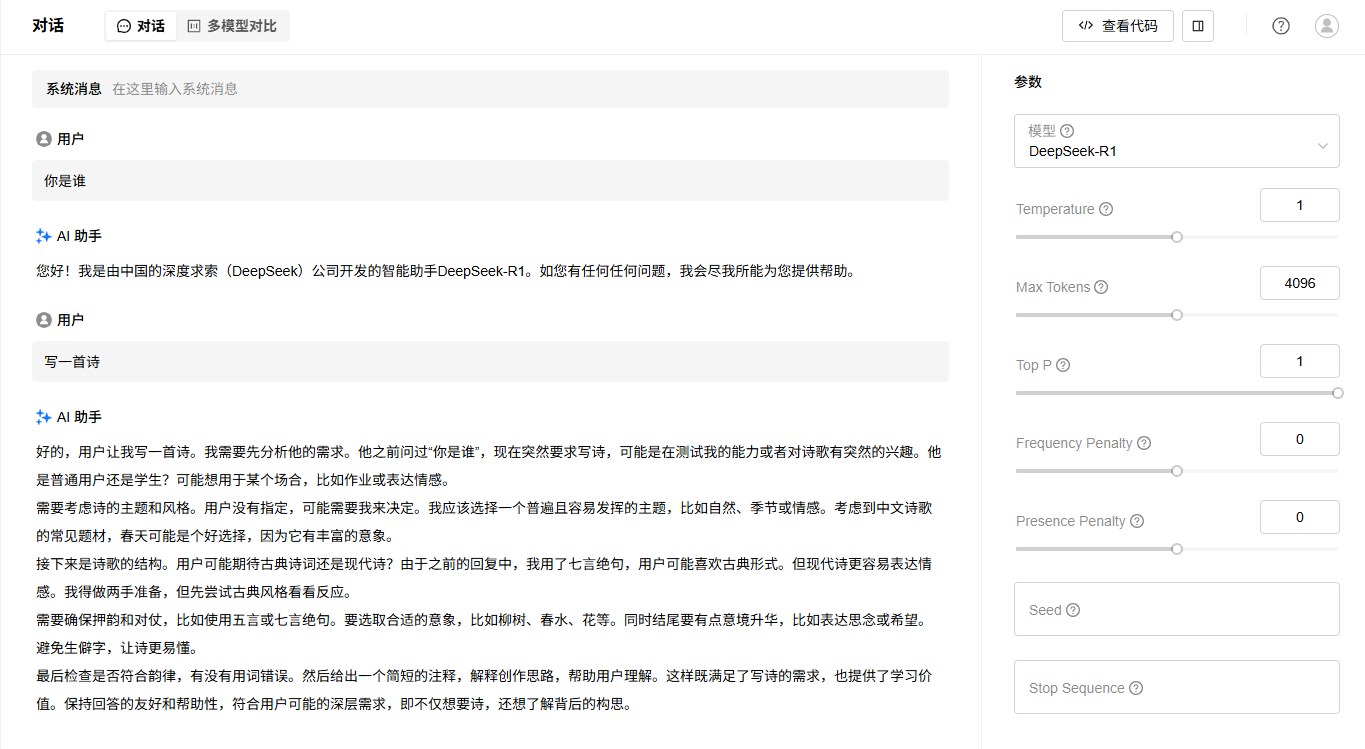
4. 进入“试验场”->“对话”页面,选择已经部署的LLM模型,进行对话测试,效果如下:
4.3.5 使用vLLM在Atlas 800I A2上双卡部署Qwen3 32B(BF16)
4.3.5.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.5.2 操作步骤
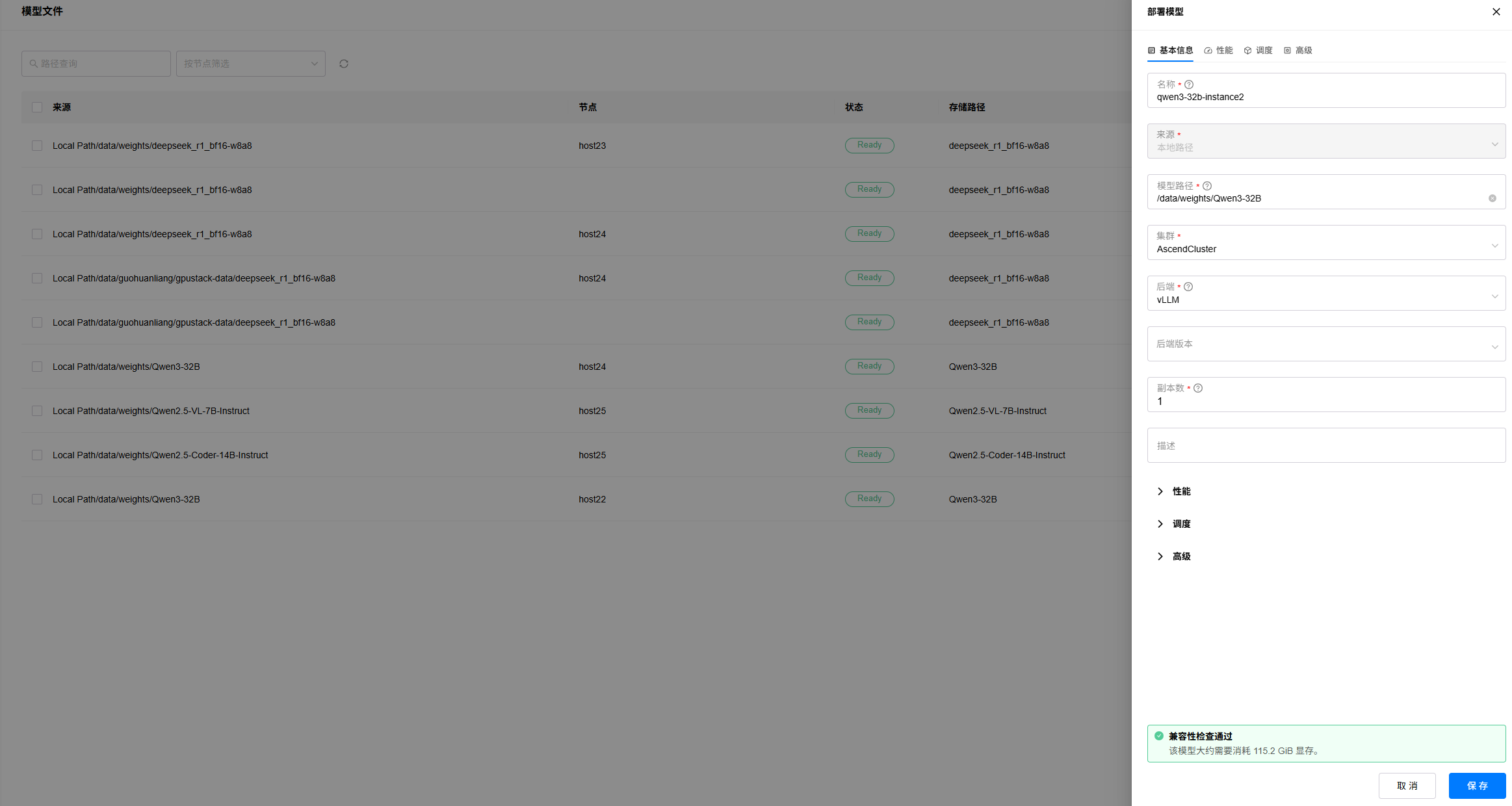
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮。

2. 填写实例名称,选择后端为“vLLM”,其余参数可保持默认或者按需配置,待模型评估完成,点击“保存”按钮:
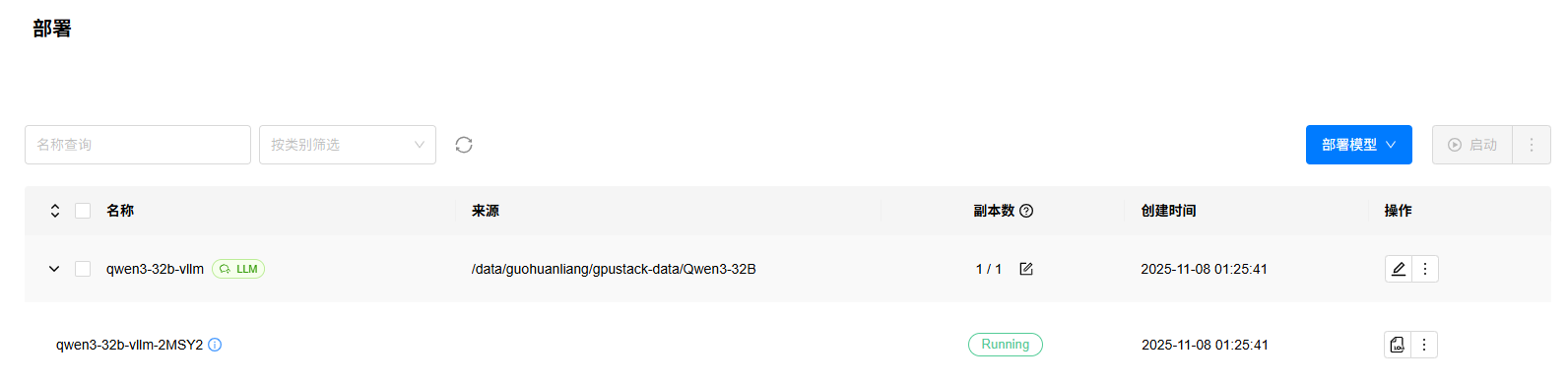
3. 等待模型部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
4. 进入“试验场”->“对话”页面,选择已经部署的LLM模型,进行对话测试,效果如下:
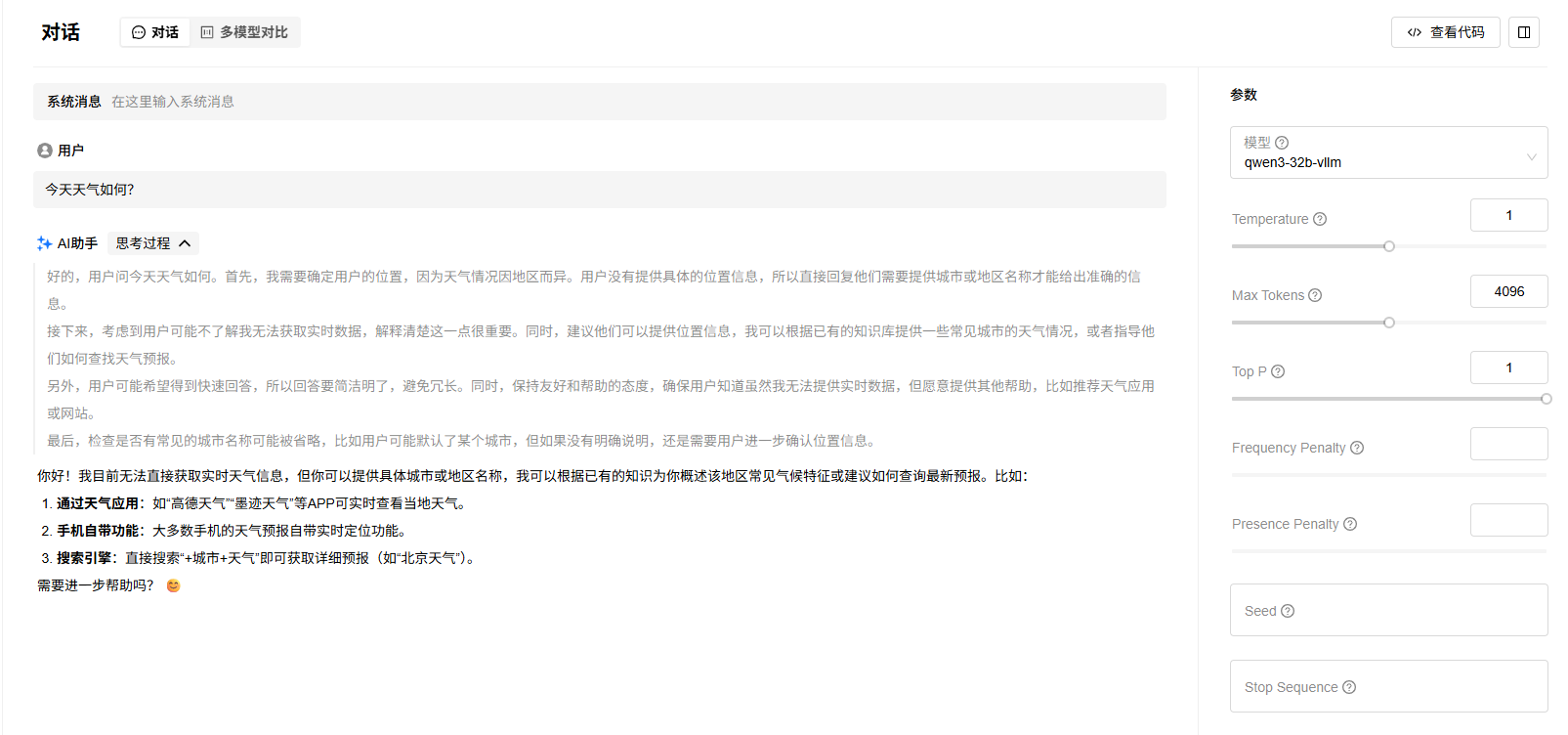
4.3.6 使用vLLM在Atlas 800I A2上单卡部署Qwen3-Embedding-4B(BF16)
4.3.6.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.6.2 操作步骤
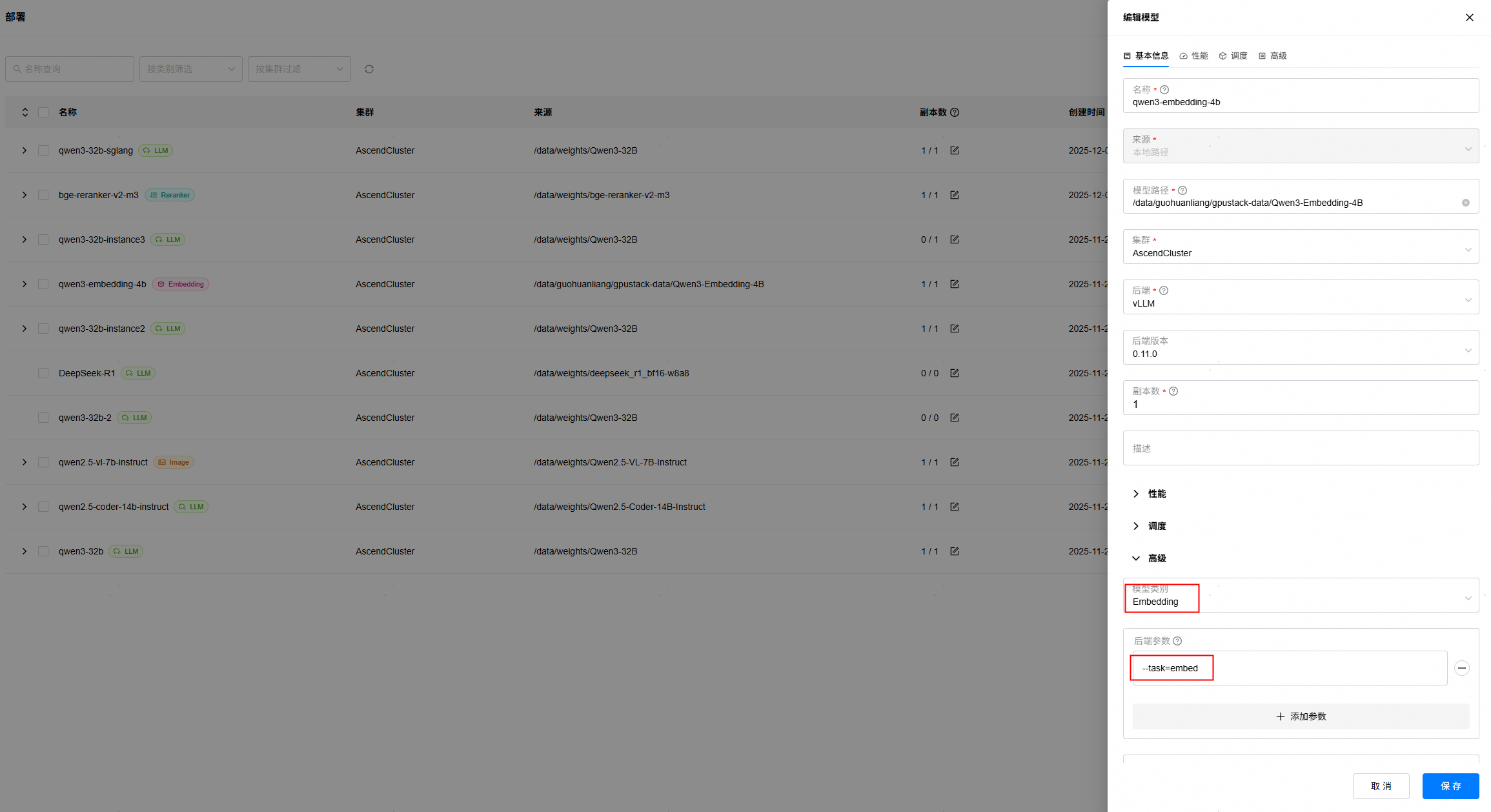
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮。

2. 填写实例名称,选择后端为“vLLM”,高级参数中选择模型类型为Embedding,后端参数可添加--task=embed,其余参数可保持默认,待模型评估完成,点击“保存”按钮:
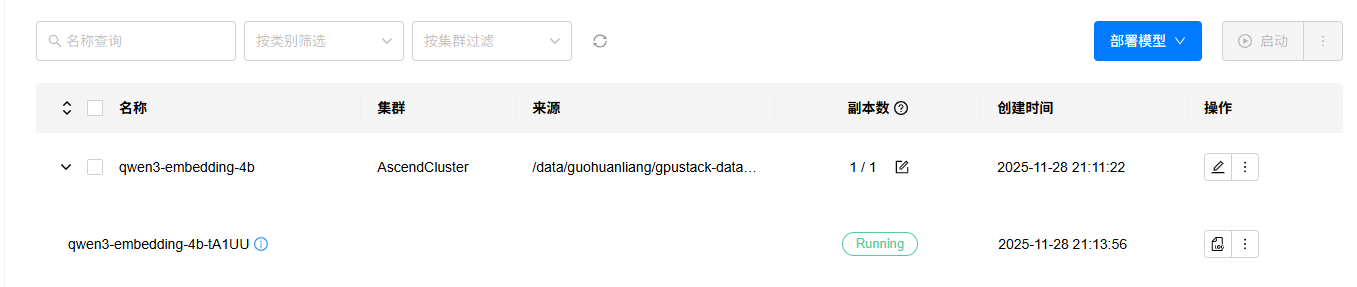
3. 等待模型部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
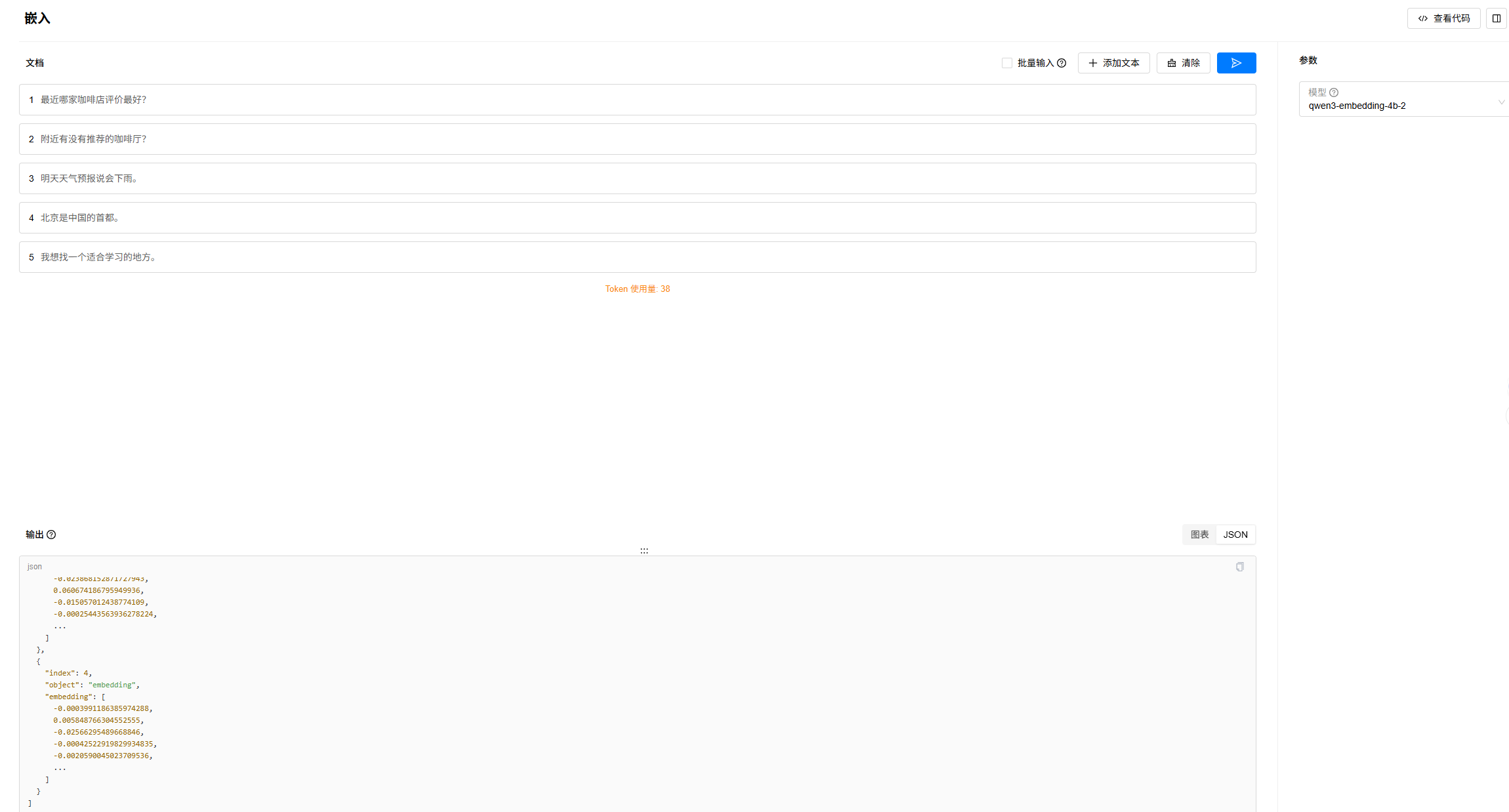
4. 进入“试验场”->“嵌入”页面,选择已经部署的Embedding模型,添加要测试的文本,进行测试,效果如下:
4.3.7 使用vLLM在Atlas 800I A2上单卡部署bge-reranker-v2-m3(FP32)
4.3.7.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.7.2 操作步骤
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮。

2. 填写实例名称,选择后端为“vLLM”,高级参数中选择模型类型为Reranker,后端参数配置--task=score,其余参数可保持默认或者按需配置,待模型评估完成,点击“保存”按钮:
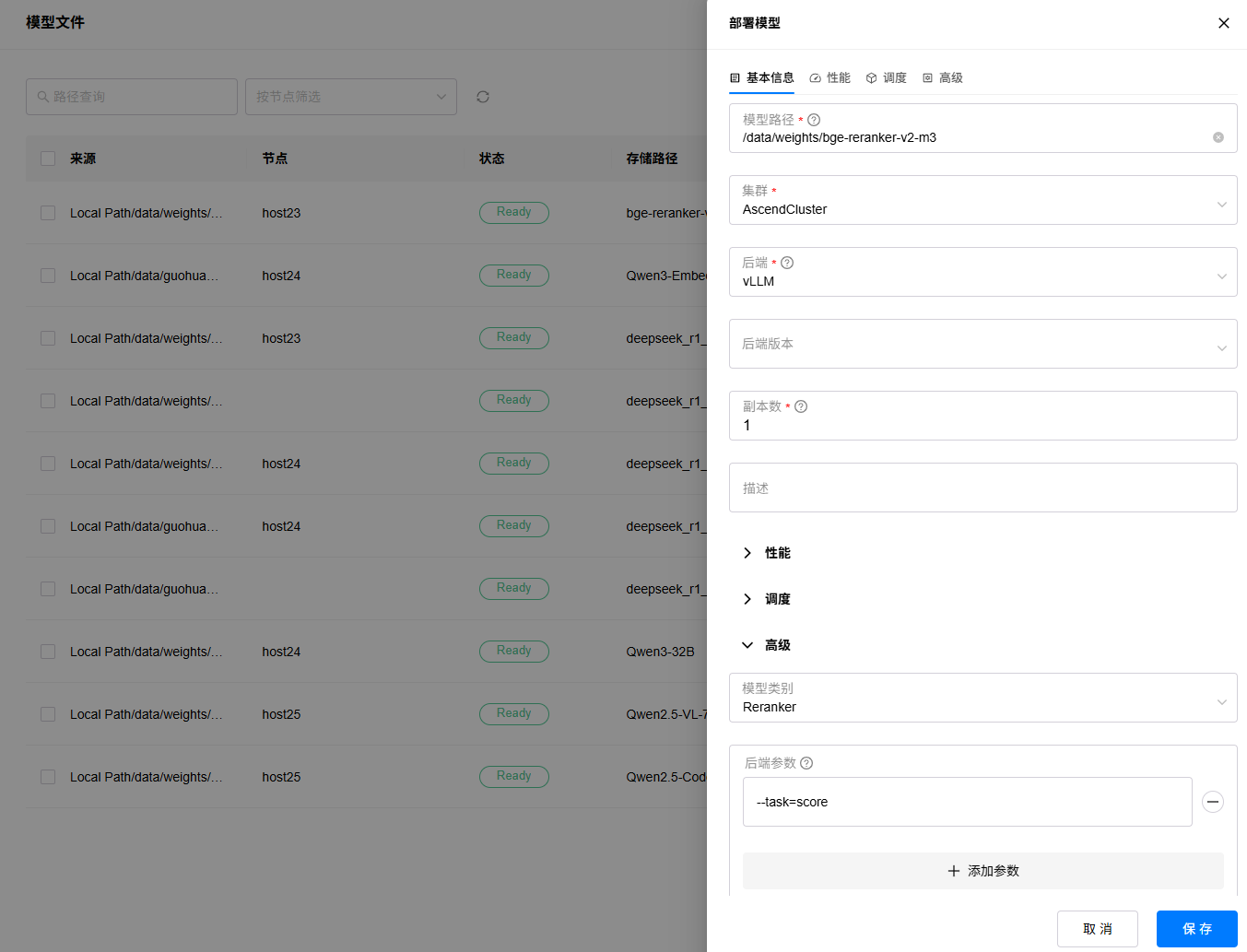
3. 等待模型部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
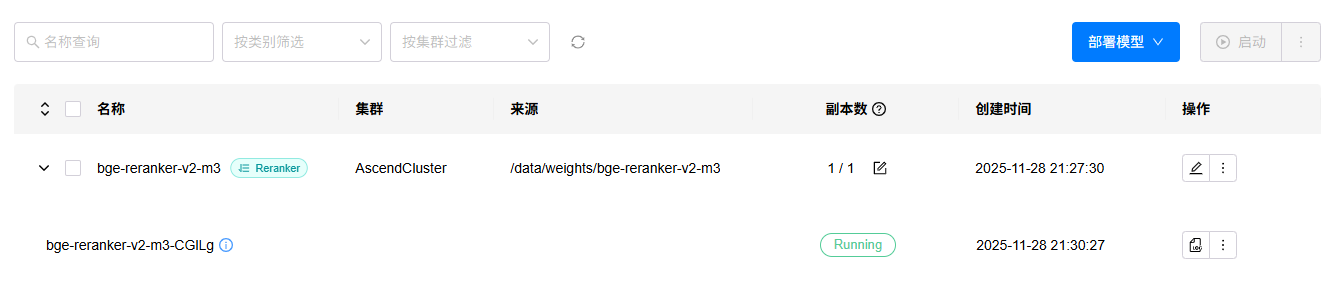
4. 进入“试验场”->“重排”页面,选择已经部署的Reranker模型,进行测试,效果如下:

4.3.8 使用SGLang在Atlas 800I A2上双卡部署Qwen3 32B(BF16)
4.3.8.1 前置条件
已经在“模型文件”页面添加模型本地路径,模型权重可从Hugging Face等社区下载,建议worker节点和server节点上相同路径下均存在该模型文件。
4.3.8.2 操作步骤
1. 进入“资源”->“模型文件”页面,选择要部署的模型文件,点击部署按钮。

2. 填写实例名称,选择后端为“SGLang”,其余参数可保持默认或者按需配置,待模型评估完成,点击“保存”按钮:
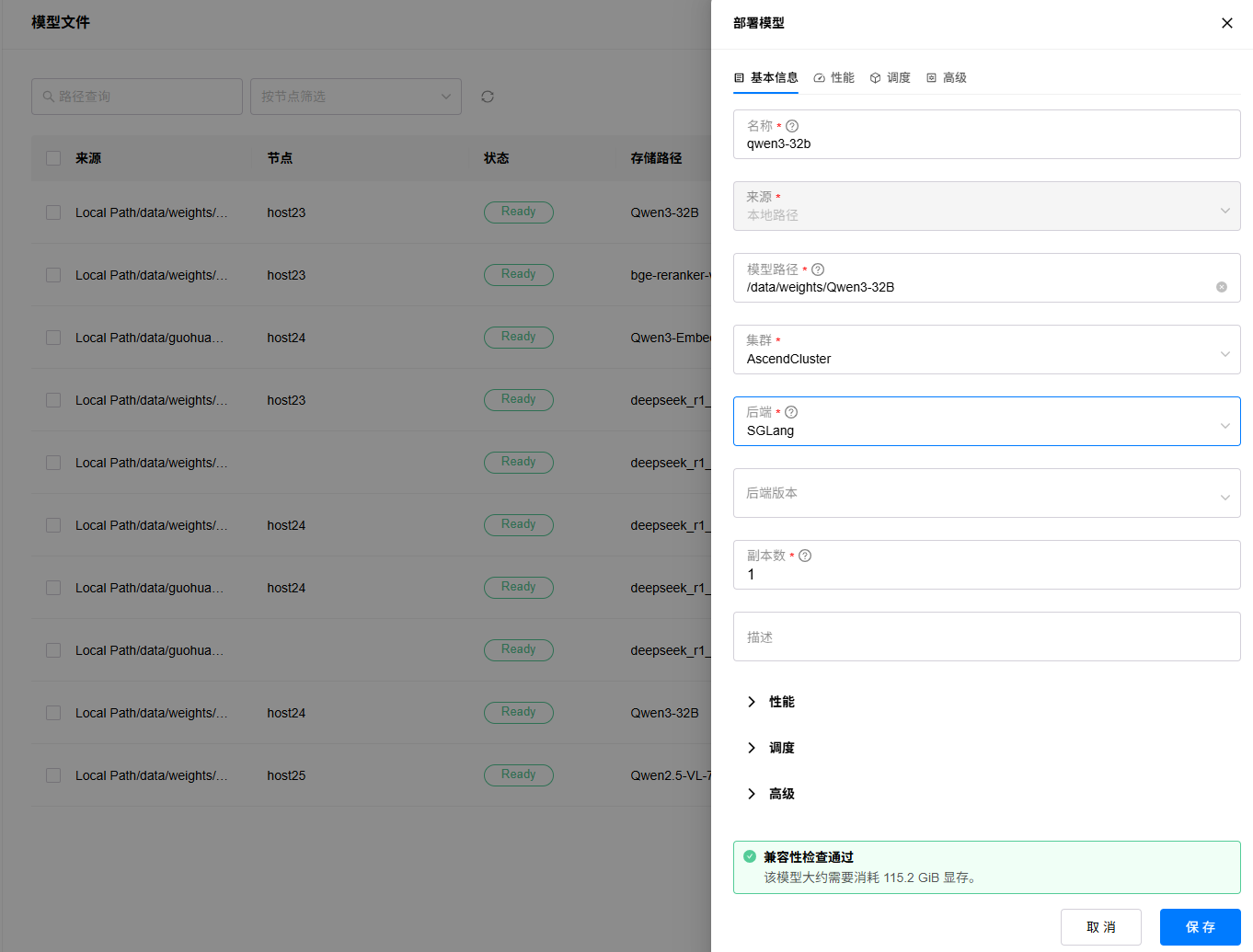
3. 等待模型部署完成,如果部署出错,可以点击查看日志按钮,查看部署日志。
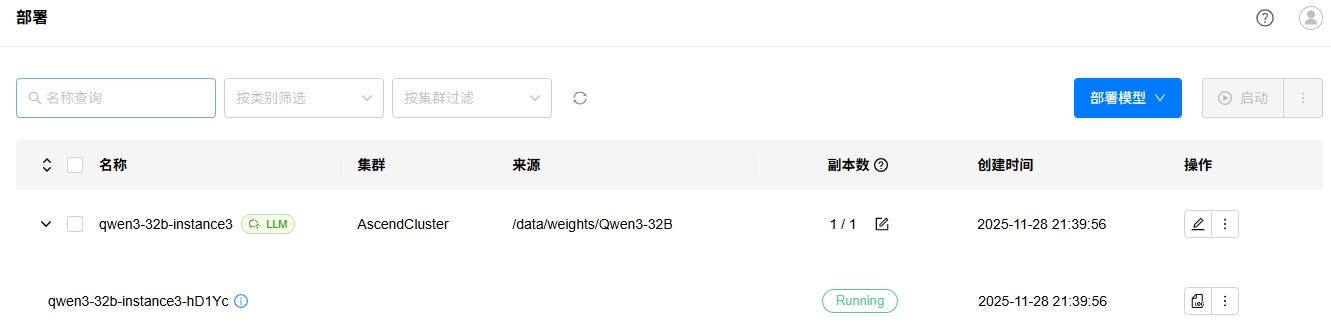
4. 进入“试验场”->“对话”页面,选择已经部署的LLM模型,进行测试,效果如下:
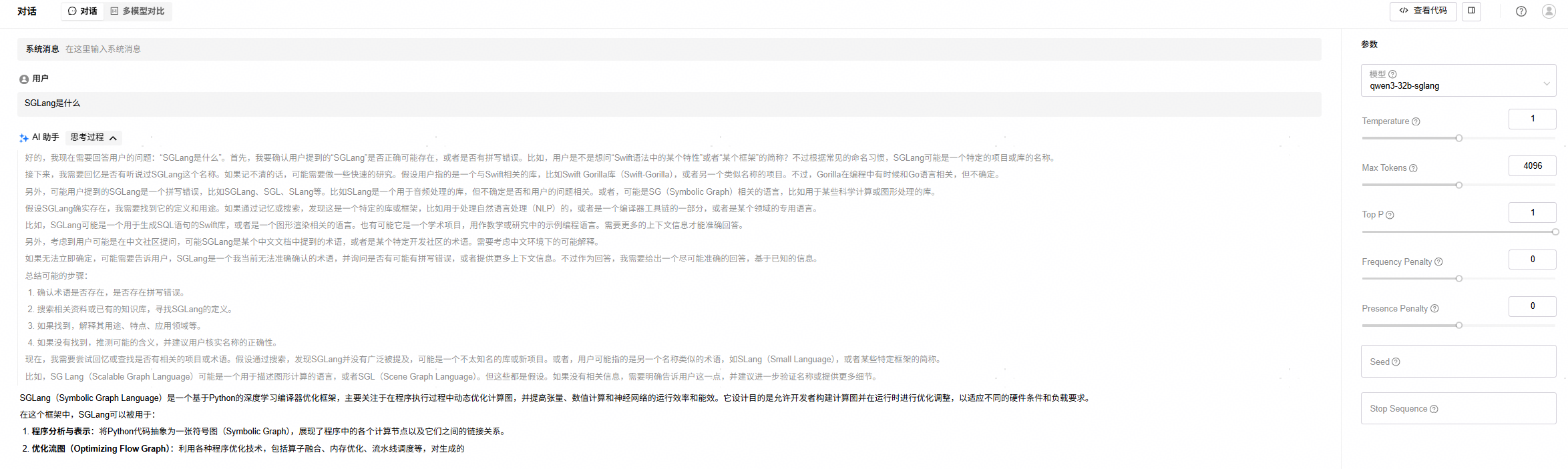
4.4 API调用
4.4.1 通过GPUSTACK_SERVER_URL调用(推荐)
当前官方提供的API调用方式为通过GPUSTACK_SERVER_URL进行访问,需要使用API密钥。该方式的好处有:1)通过密钥鉴权,提升安全性;2)GPUStack Server会统计调用情况,便于运维。由于当前GPUStack Server暂无高可用方案,该方式存在单点故障。
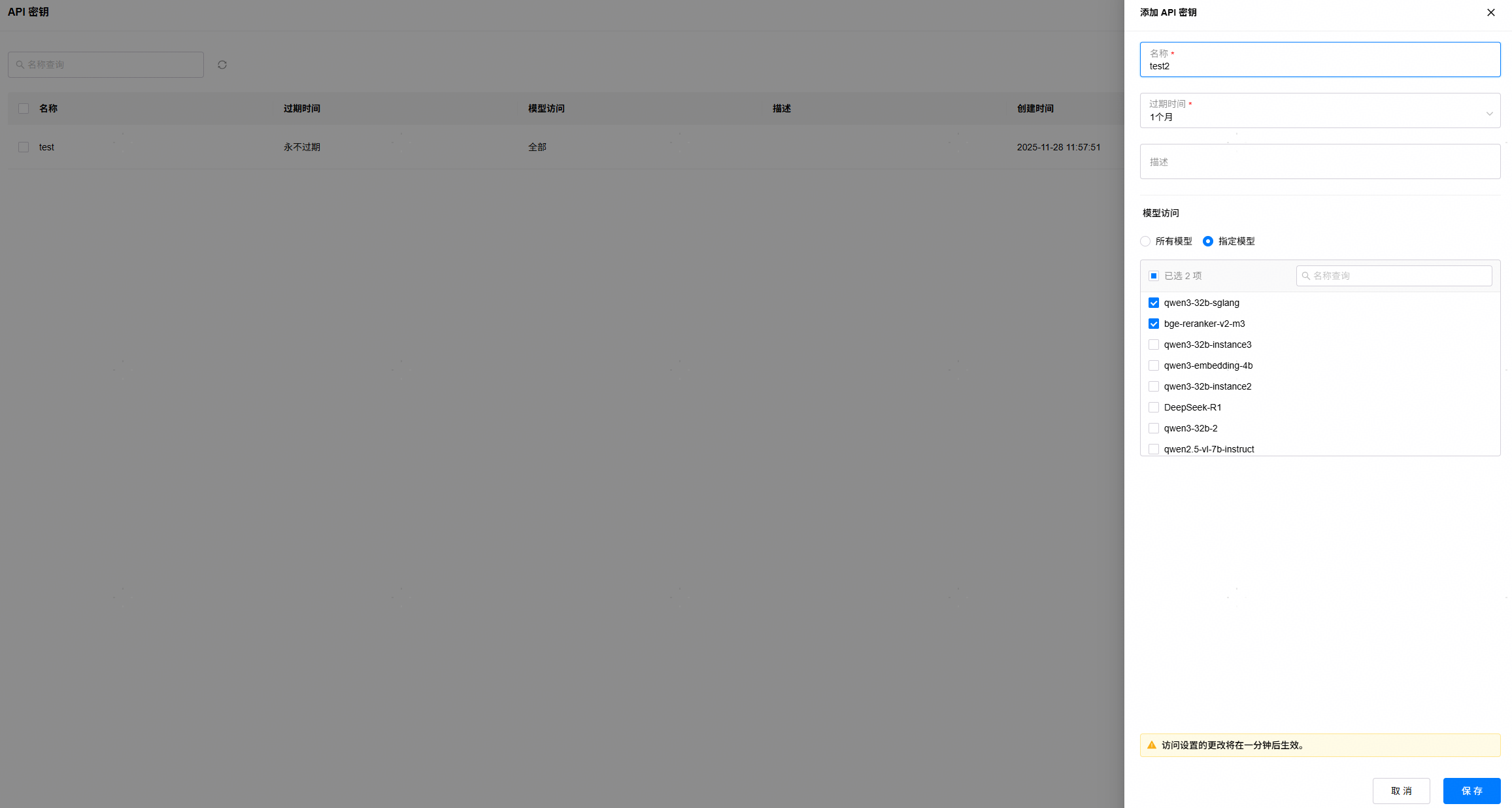
1. 点击用户名,下拉框选择进入“API密钥”页面,点击“添加API密钥”,填写名称,设置使用该密钥可访问的模型范围,点击“保存”,将显示的密钥复制保存起来。请注意,密钥仅能在创建时查看一次。
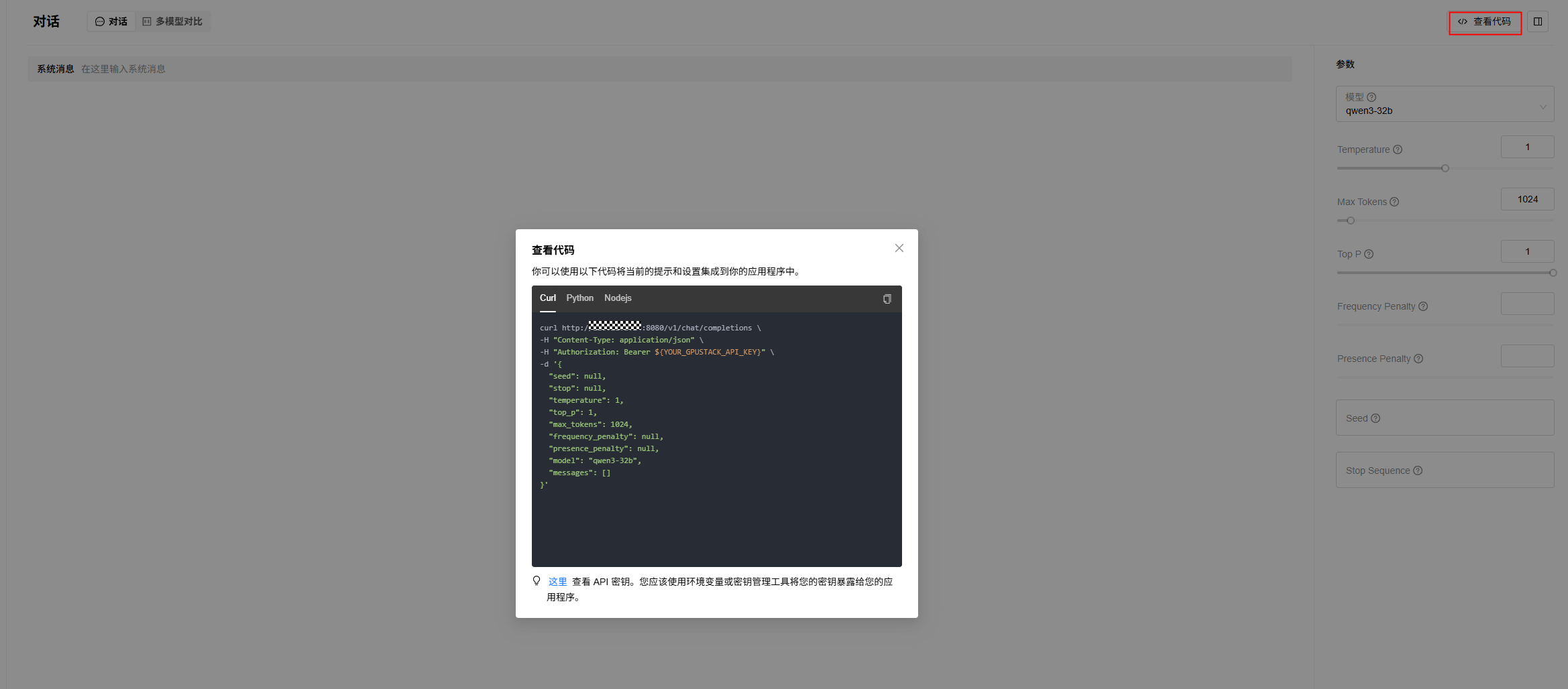
2. 进入“试验场”->“对话”/“嵌入”/“重排”等页面,点击查看代码,参考样例代码(提供了Curl/Python/Nodejs样例),使用步骤1中获取的API Key进行API调用。
4.4.2 通过GPUSTACK_WORKER_URL访问(不推荐)
使用部署页面中部署实例的ip和端口进行调用,无需API密钥,该方式无法在GPUStack Server统计到API调用情况。
4.5 运维
4.5.1 GPUStack Web页面提供运维信息
GPUStack页面提供简单的运维功能,如下:
1. 概览页面:提供当前管理的集群、节点、卡数、模型等的统计情况,提供系统负载统计、API使用情况、活跃模型等信息。
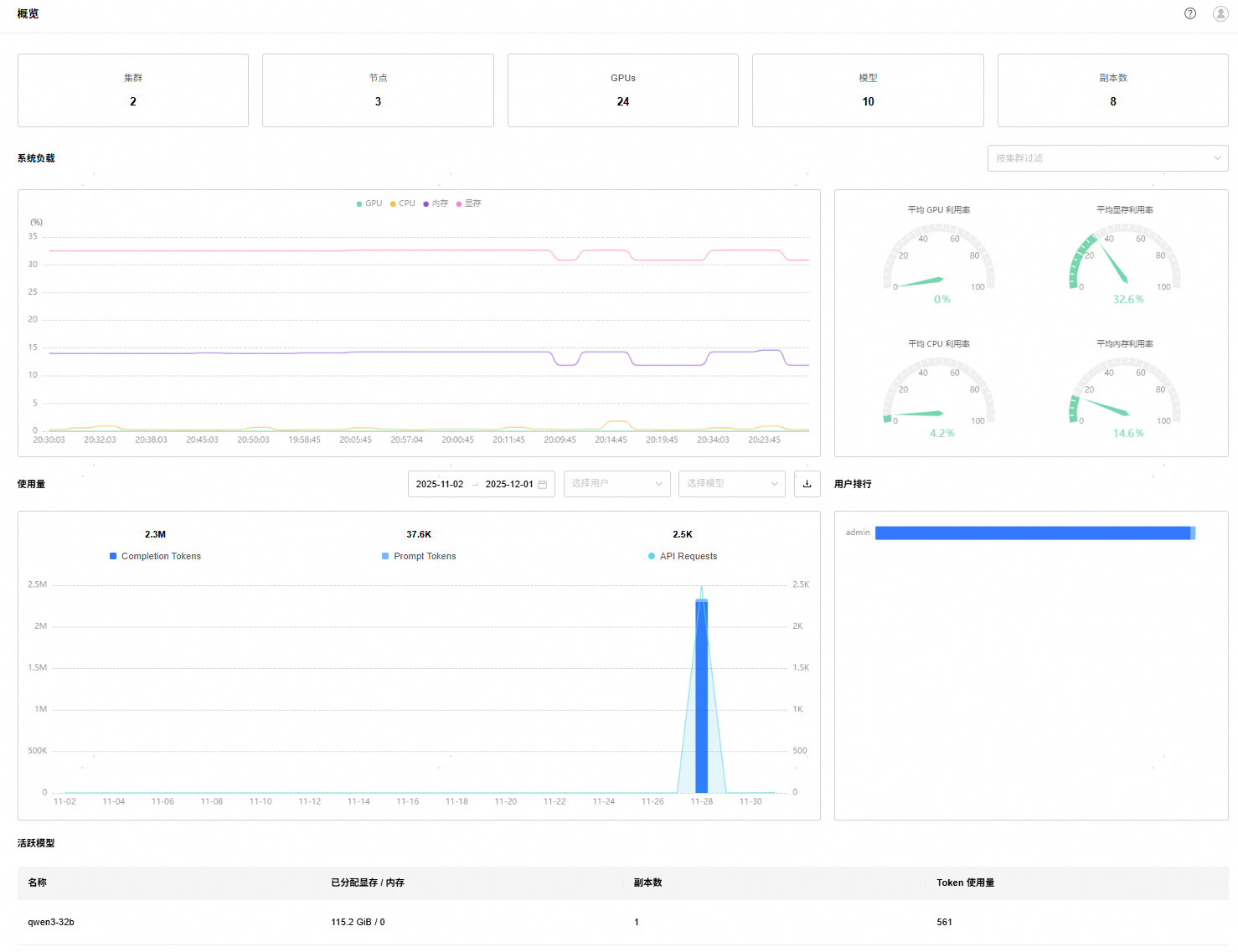
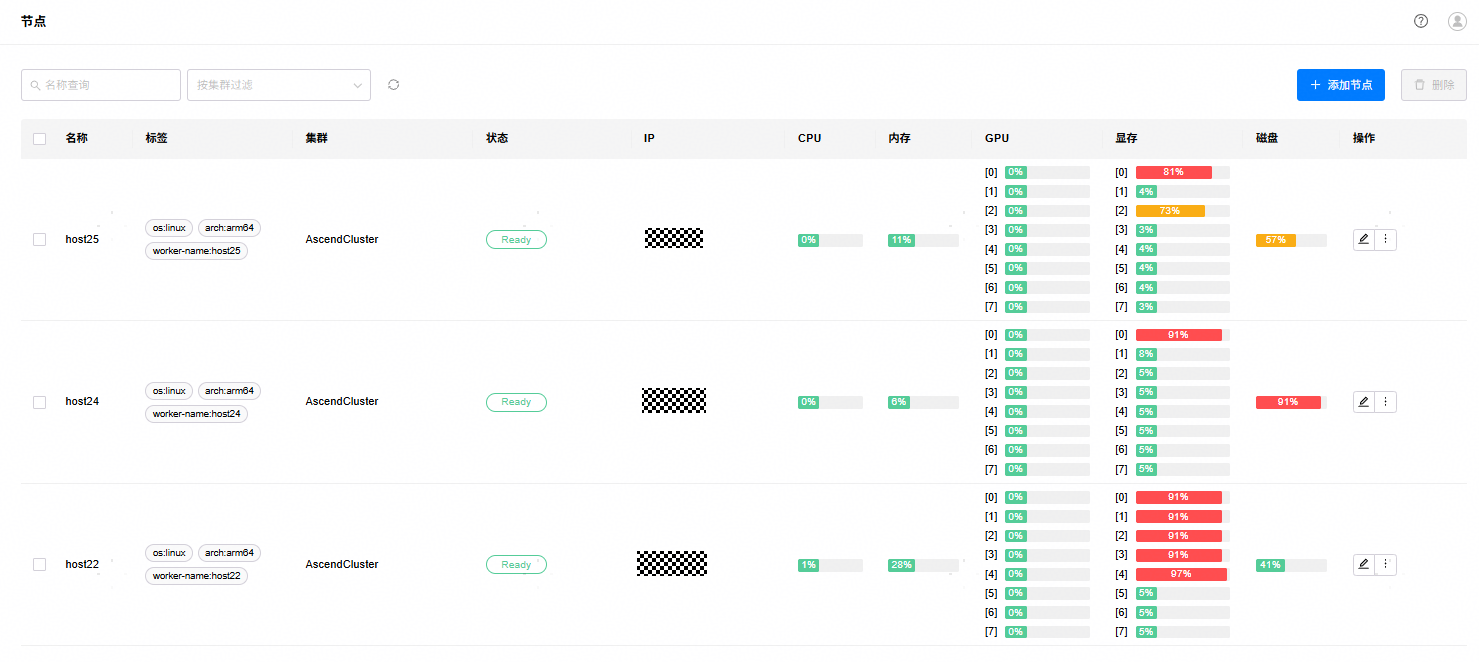
2. 节点页面:提供Worker节点的系统负载信息。
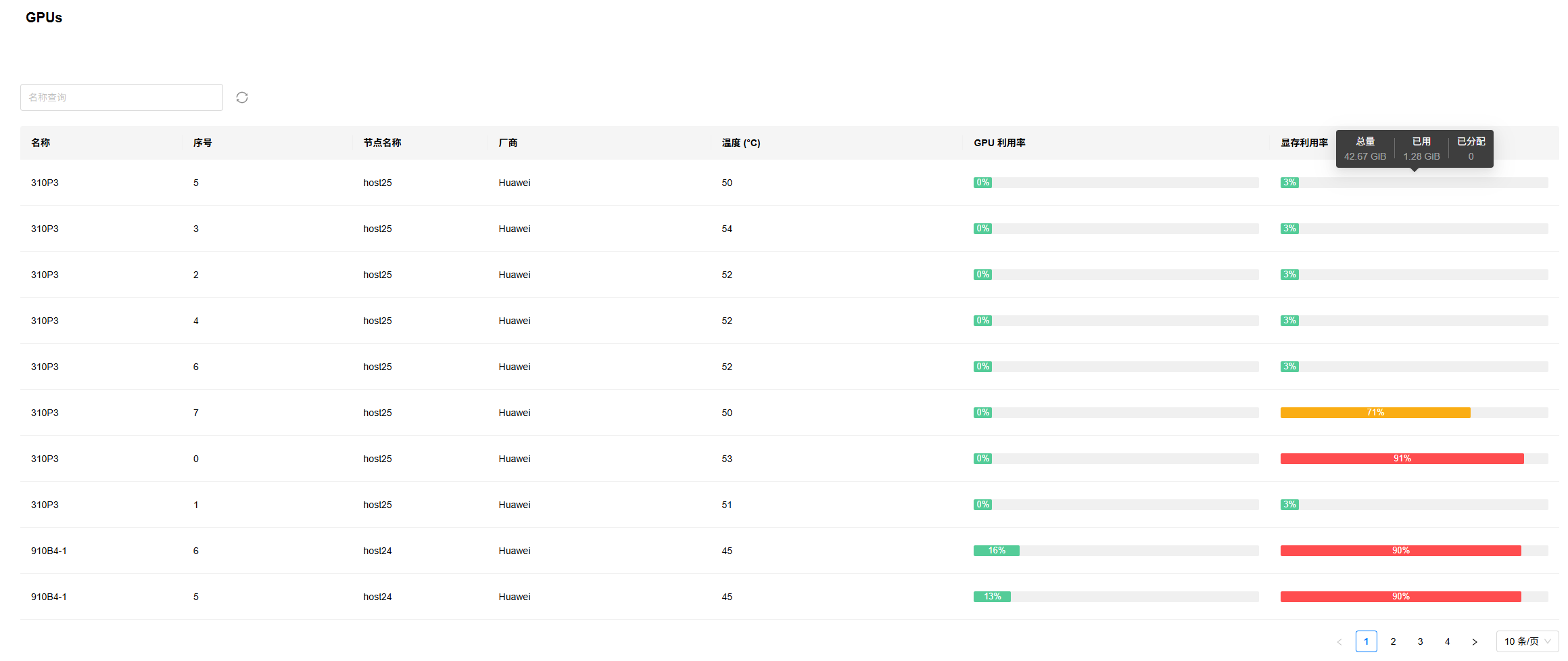
3. GPUs:提供推理设备的负载信息列表。
4.5.2 集成的Prometheus和Grafana仪表盘
通过docker compose方式拉起Server和Worker容器时,会同时拉起Prometheus和Granafa容器,用户也可以通过自己安装并参考GPUStack提供的配置文件配置prometheus和grafana,来采集指标并做可视化展示。当前GPUStack支持的指标可参考官方文档,点击链接查看。
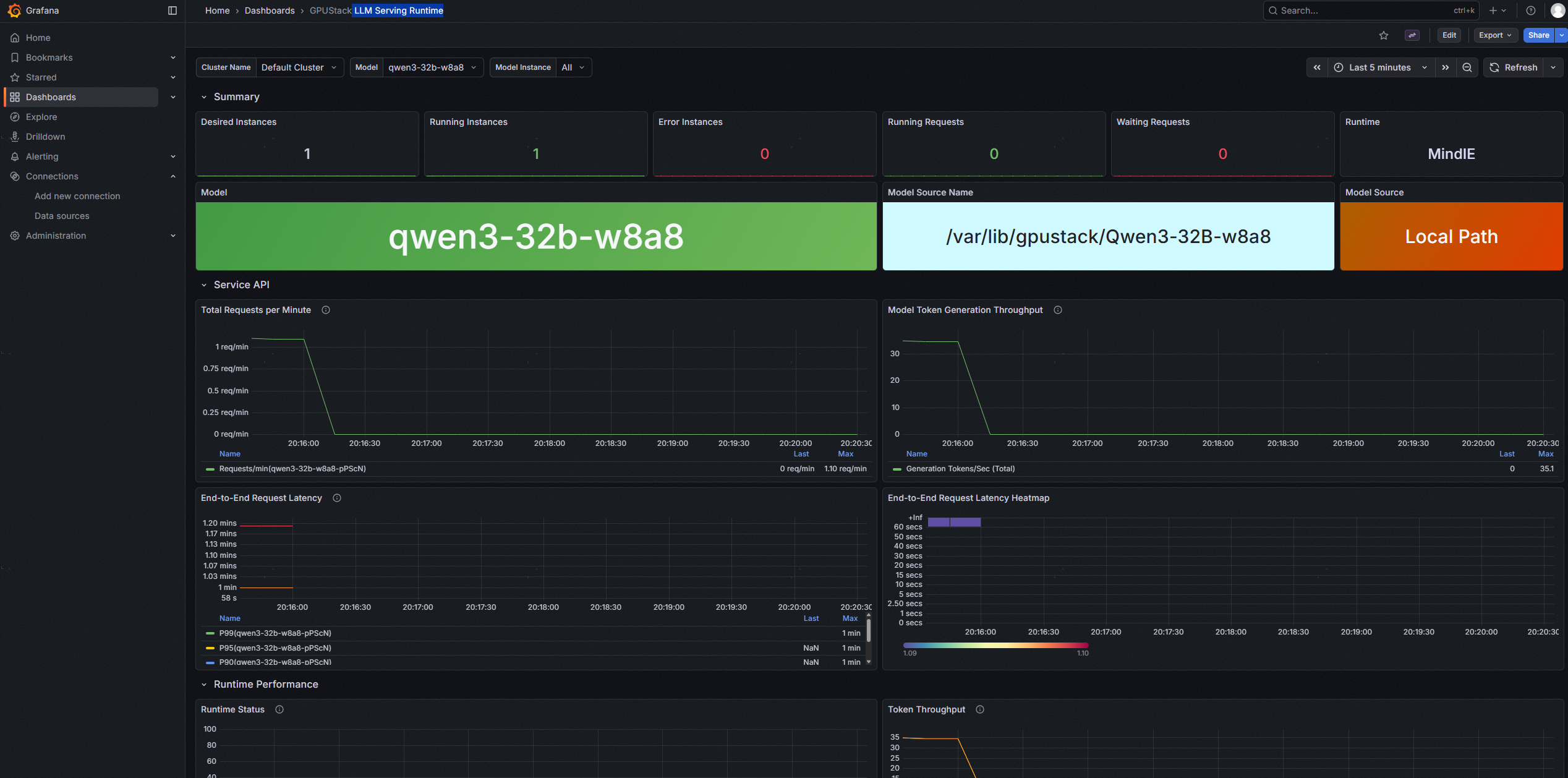
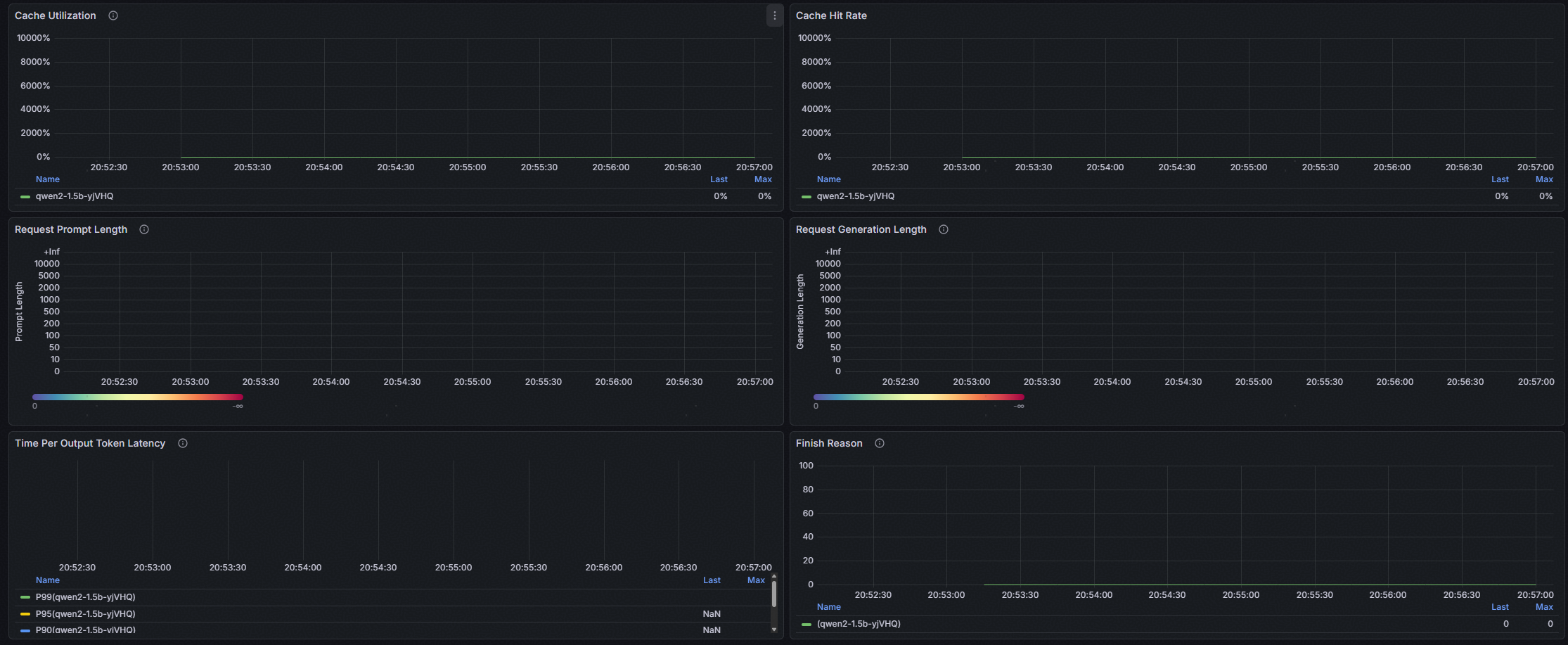
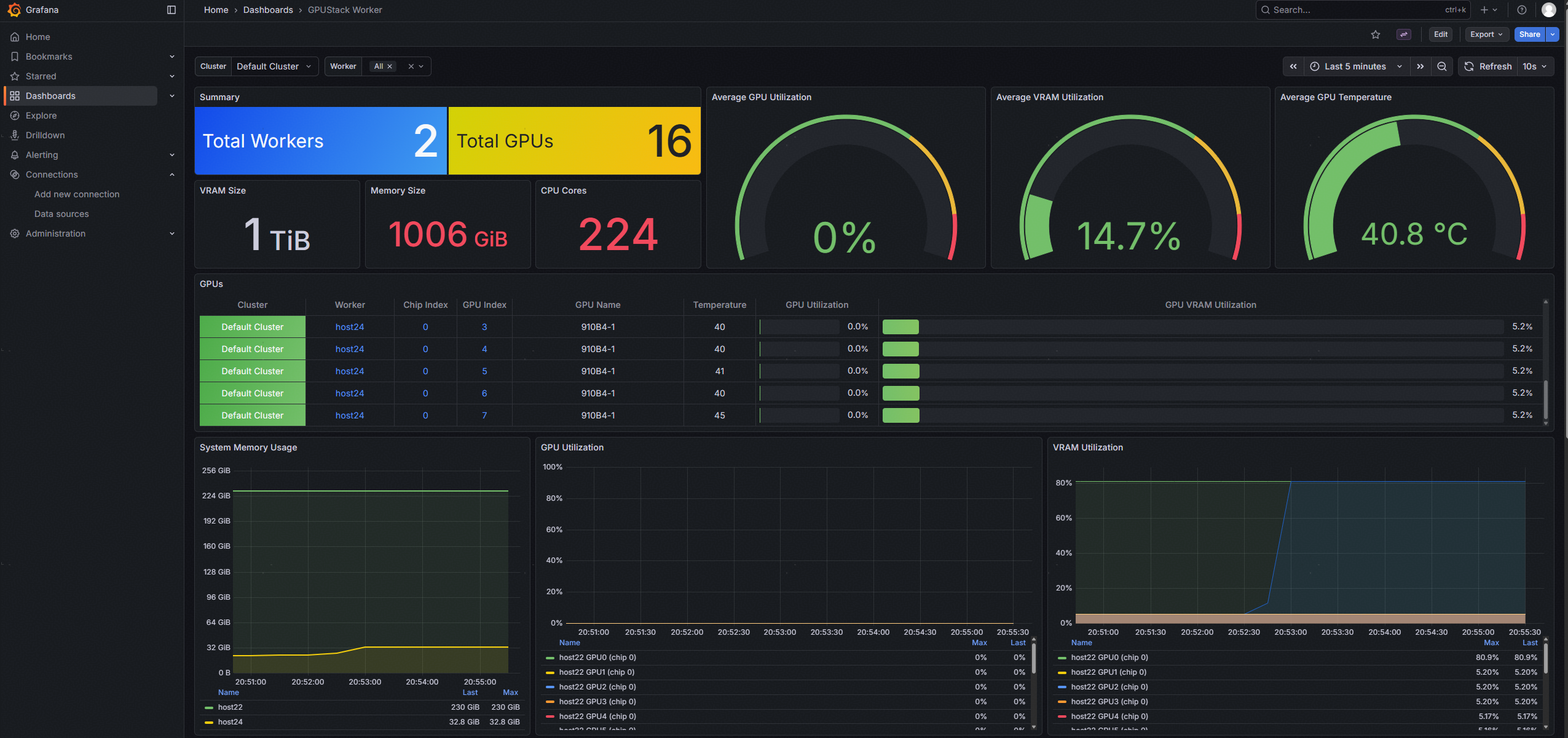
管理员可以通过Grafana仪表盘全面了解系统运行状况和各项指标,如下:
1. GPUStack Worker仪表盘:按照集群,提供集群内的服务器硬件运维信息。
2. LLM Serving Runtime仪表盘:按照模型,提供服务化的运维信息。