



昇腾超节点百TB级内存语义池化应用实践
发表于: 2025/12/03
当前,生成式人工智能浪潮正深刻改变着全球的计算格局,随着模型规模不断扩大、数据复杂性持续上升,AI工作负载对内存系统提出了前所未有的挑战,传统分散的、孤立的、静态的内存架构已难以支撑AI大规模并行计算对效率、弹性和资源协同的严苛要求。在这一背景下,AI超节点内存池化技术应运而生,成为打破“内存墙”的关键路径。然而,在AI超节点上软件使能内存池化并非易事,如何屏蔽硬件差异实现跨节点异构设备之间的直接访问?如何理清复杂的底层软件设计出完整健全的解决方案?如何提供灵活、简洁、适用性强的编程接口?这些问题都亟待解决。近来,通过MindCluster的 MemCache(以下简称MemCache)组件成功突破上述技术屏障,创新性地使用内存语义统一编址的方式,支持跨机跨介质数据直接访问,在昇腾超节点实现百TB级的混合内存池化。
分布式内存池化
MemCache是亲和昇腾/鲲鹏硬件的开源软件,提供分布式内存池化和对象缓存能力,可应用于KVCache缓存池等多种场景,其架构层次如图1所示。
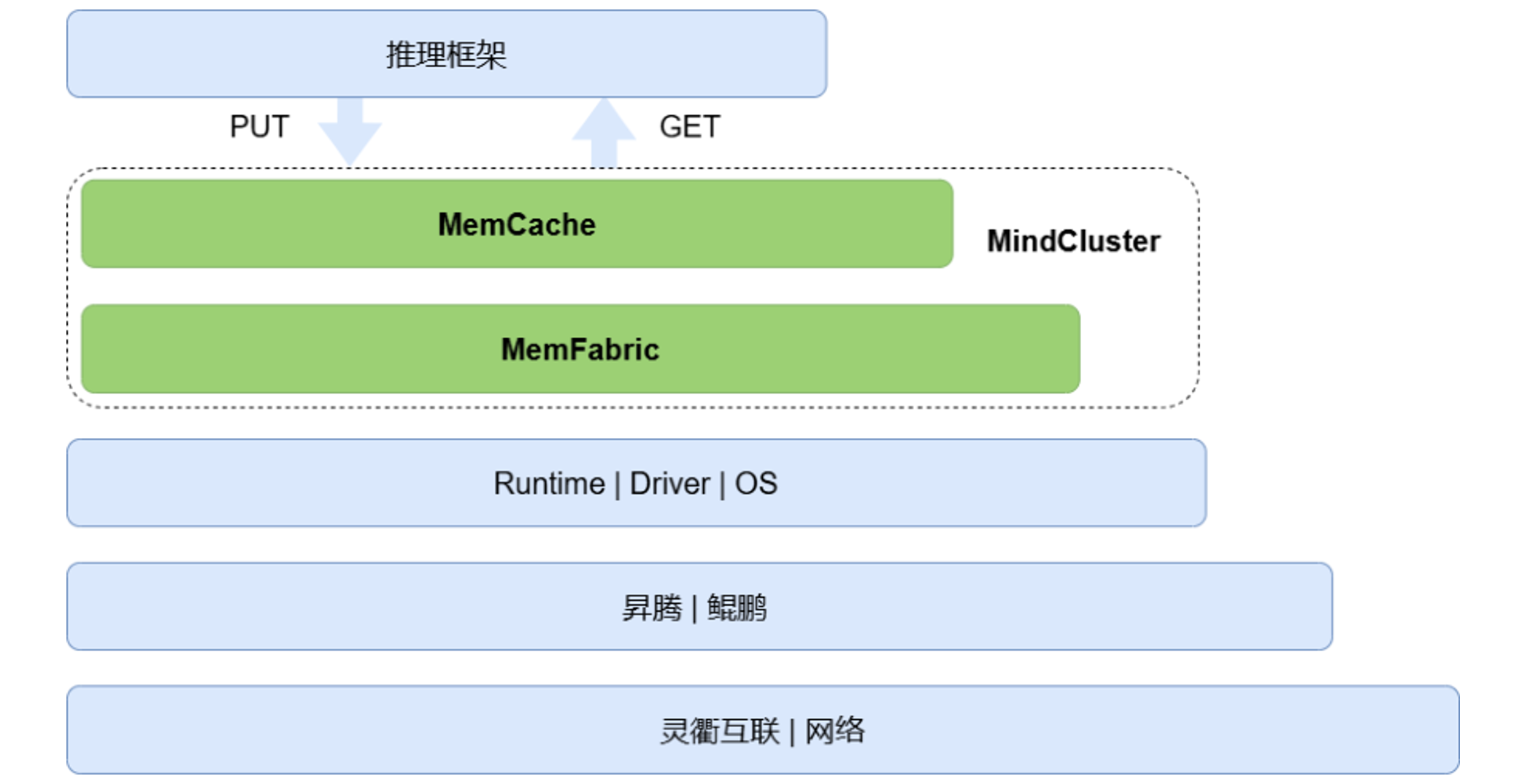 图1. 架构层次
图1. 架构层次
内存池化基于分层解耦的设计思想,在不同的层次提供不同的语义及对应的接口,其中,MemCache提供对象的Put/Get语义,属于池化技术的应用层语义;MemFabric提供统一编址的内存语义,属于池化技术的基础能力。本文重点介绍MemFabric,包含当前的挑战、设计思想、关键技术、性能表现、场景应用结果。
基于昇腾/鲲鹏等多种硬件实现内存池化及高效内存访问,面临如下多个方面的挑战:
1.底层互联的多样化
随着业务对性能要求的不断攀升,Device与Device间、Host与Host间的互联技术与搬运引擎也在不断的演进与加强,如从Device RoCE到灵衢互联、从MTE/SDMA到MTE/UDMA等等。上层应用如何使用这多样化的硬件,如何发挥出各种硬件的极致性能,都是极大的挑战。
2.如何实现跨节点跨介质的异构内存直接访问
灵衢总线将NPU与CPU在物理层以对等的方式连接,为异构内存间直接访问提供了物理基础,但如何在软件上端到端打通、如何实现高性能,仍然存在较大的挑战。
3.如何提供简洁的软件抽象与接口
实现DRAM与显存的池化,在不同的层次都存在异构,如介质、互联、搬运引擎、发起者等等,如何从软件角度进行抽象、如何为上层应用提供统一的、简化的接口,也是一个挑战。
MemFabric正是为解决上述挑战而设计,其核心思想为以下三点:
- 异构设备的统一池化:将多节点的异构设备内存(CPU内存 | NPU显存等)池化,提供高性能的全局内存“直接访问“的能力
- 简单的北向接口:内存语义访问接口,即xcopy with global virtual address,向传统的memcpy概念靠近
- 南向高可扩展:通过插件的方式支持多种DMA引擎和LD/ST及多种网络/灵衢互联 (Device UB、Device RoCE、Host UB、Host RoCE等)
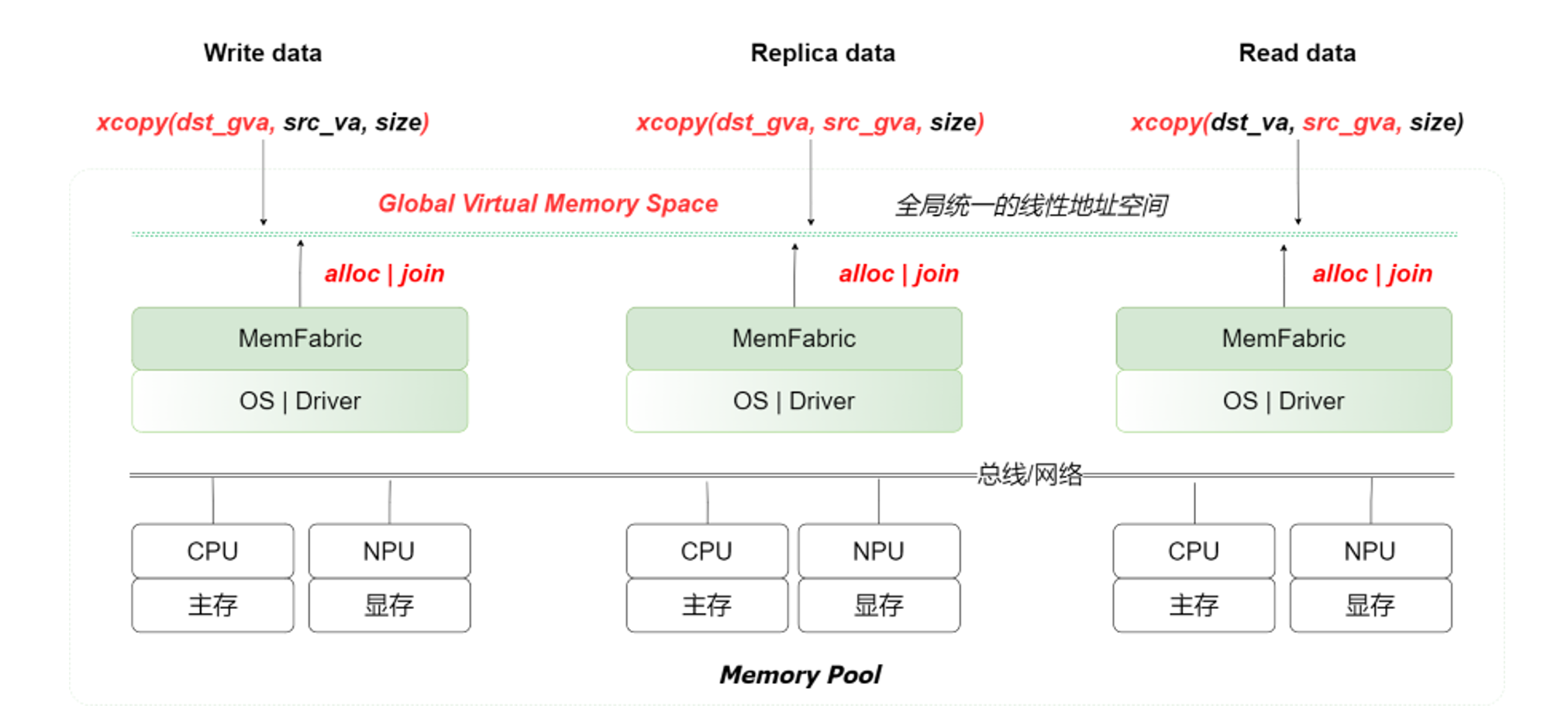 图2. MemFabric理念与系统架构
图2. MemFabric理念与系统架构
如图2所示,MemFabric通过构建逻辑上的全局内存语义统一编址,对分布在不同层级、不同节点的内存单元进行统一管理与使用,使系统能够像管理单一物理资源一样,对跨 CPU、NPU的内存资源进行统一寻址和透明访问,核心目的是实现内存资源的整合与统一调度,从而显著提升硬件的算力释放效率。
内存语义统一编址有什么好处?
为什么要进行统一编址?当前的内存系统普遍面临如下痛点:
1) 内存池访问通常需要开发者手动管理内存具体信息,比如内存位于那个节点?内存是CPU内存还是NPU显存?这类操作实现繁琐,不仅增加了代码复杂度,还容易引发数据一致性等问题,显著增加系统出错概率。
2) 在CPU内存与NPU显存之间进行数据交互,特别是涉及跨节点交互时,往往需要数据中转传输,这不仅需要复杂的控制面参与搬运,还会导致延迟放大、带宽浪费、进而造成性能下降。使用NPU高带宽网络搬运数据的典型方式如下图3所示。
图3中列举了典型搬运路径D2RH(本机NPU显存到跨机CPU内存)、RH2D(跨机CPU内存到本机NPU显存)、RH2H(跨机CPU内存到本机CPU内存)。
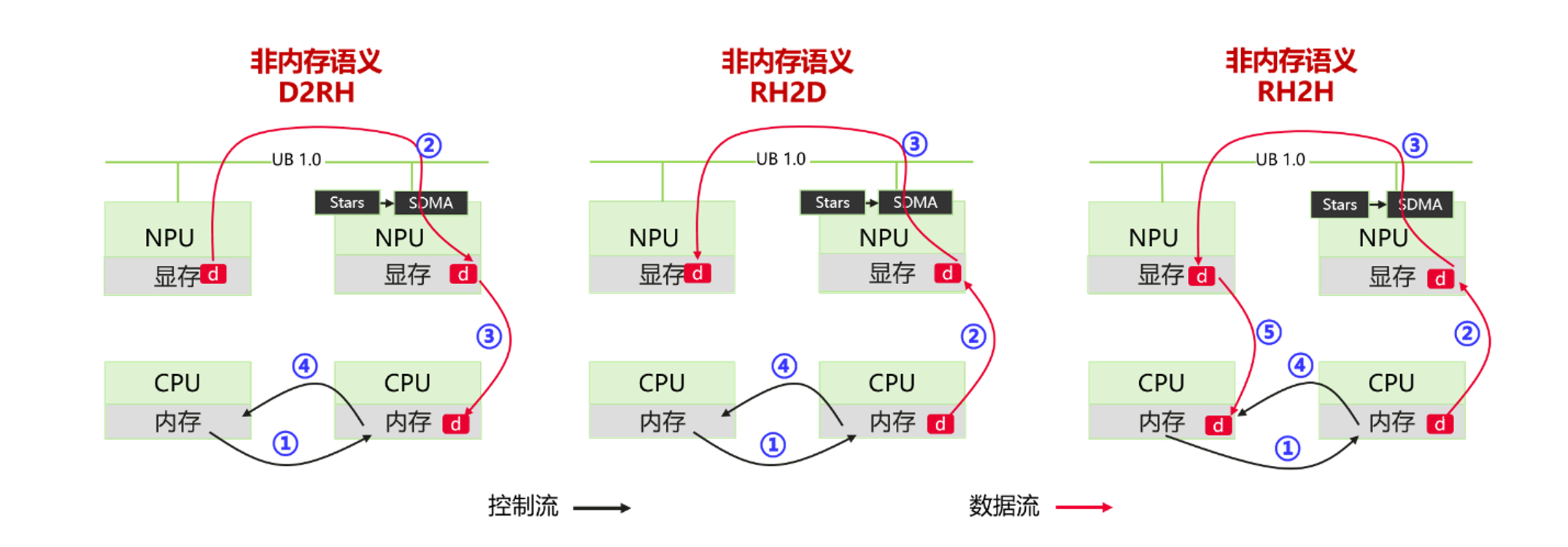 图3. 非内存语义跨机异构内存数据流和控制流
图3. 非内存语义跨机异构内存数据流和控制流
而通过内存语义统一编址的方式,可以有力地解决上述痛点:
1) 对所有的进程,其池化地址空间相同,进程像管理单机资源一样管理全局资源;无需开发者手动管理数据传输路径和方向,避免管理数据地址和类型,降低代码复杂度。
2) 内存语义统一编址叠加MemFabric池化底层技术,支持在跨节点的异构内存介质间直接访问数据,减少控制面搬运的复杂性与开销,避免不必要的数据中转。
MemFabric以动态库的形式支持应用进程加载,为集群中的所有进程提供全对称的统一编址的虚拟地址空间(Global virtual address,GVA),在这片空间中,GVA具有如下的特点:
- 它是一个简单的uint64
- 所有进程的GVA的起始地址一致
- 所有进程的GVA按线性排布且一致
如下图4所示,集群中有两个进程,进程1和进程2,每个进程均申请16GB NPU显存+128GB CPU内存作为内存池的一部分。两个进程具有完全相同的虚拟地址空间段:0x280000000000UL~0x280000000000UL+32GB为NPU显存空间,0x280000000000UL+32GB~0x280000000000UL+288GB为CPU内存空间。在这段地址空间中,业务进程通过类似memcpy(void* dest, const void* src, size_t n)的接口调用方式即可完成①~⑥所在区间数据之间的相互拷贝,无需关注src、dest地址属于哪个节点,属于什么介质。
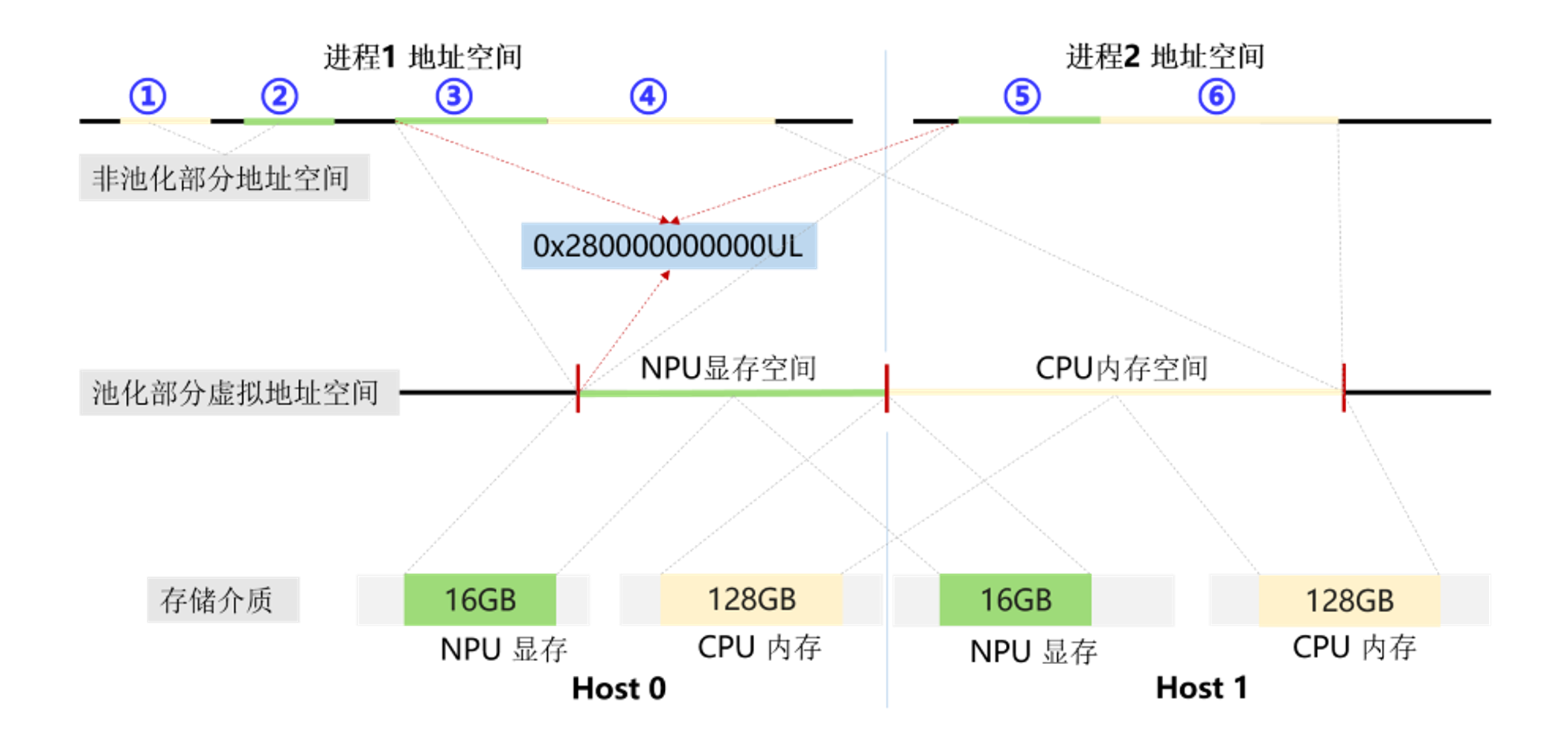 图4. MemFabric将跨机的多层级内存介质映射为统一地址空间
图4. MemFabric将跨机的多层级内存介质映射为统一地址空间
昇腾超节点上百TB级内存池化应用实践
Atlas 900 A3 SuperPoD超节点(后续简称昇腾A3超节点)与其他主流AI服务器相比,在网络传输方面有一些特点和优势,主要表现在:
1) 昇腾的高带宽网络在NPU卡侧不在Host侧,业界基于Host侧网络构建的池化软件不能充分利用硬件资源。
2) 昇腾硬件支持通过NPU卡侧网络实现RH2D、D2RH、RH2H等数据操作的“零拷贝”操作(无中转,无控制面消息,一次完成)。
如何充分利用和释放昇腾硬件的性能,这便是MemFabric要解决的核心问题。如下图5所示,MemFabric开发了一系列配套的昇腾底层技术将NPU显存和CPU内存映射到UB 1.0灵衢互联上,完成了介质在物理地址上的全局编址,打通了跨节点跨介质数据报文的物理链路。
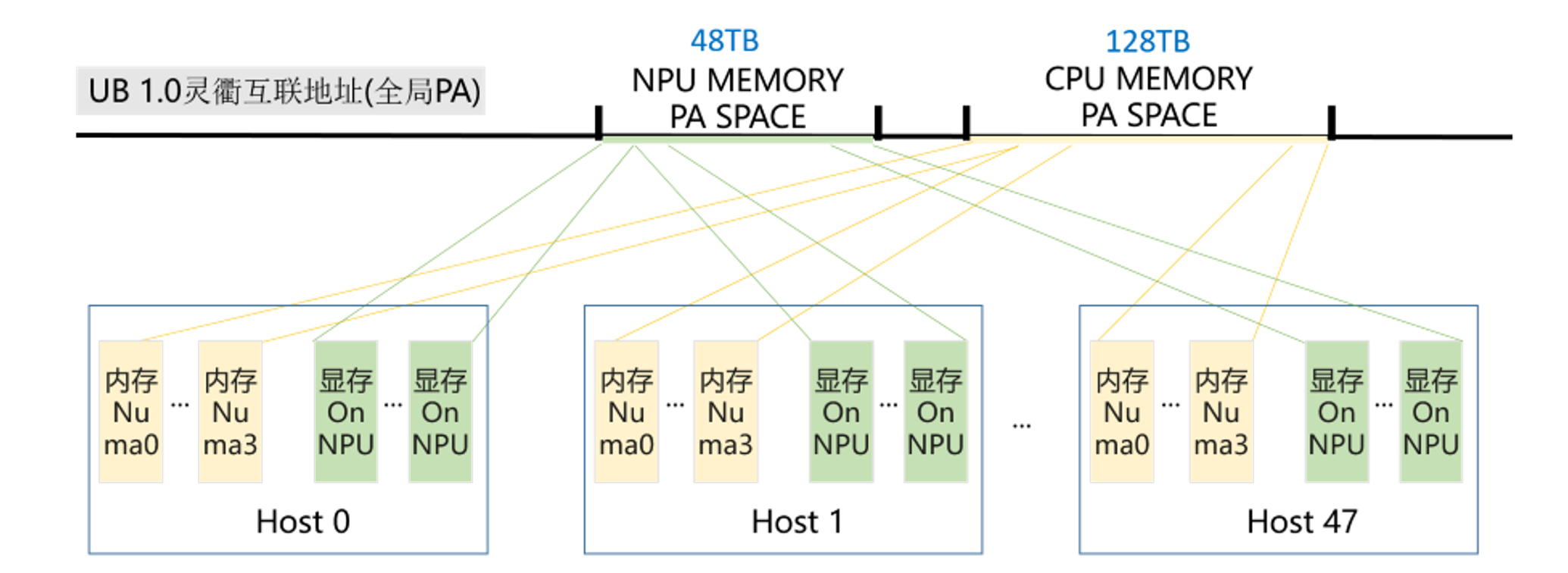 图5. 超节点内跨机异构内存映射到UB 1.0灵衢互联
图5. 超节点内跨机异构内存映射到UB 1.0灵衢互联
基于上述打通的数据物理通路,最终MemFabric在昇腾A3超节点上成功实现支持跨节点跨介质的内存语义直接访问、最大支持128TB CPU内存+48TB NPU显存的混合内存池。基于前述内存池,内存语义访问数据流和控制流如下图6所示,对比图3的非内存语义方式,显著减少了控制面复杂度和数据冗余中转拷贝。
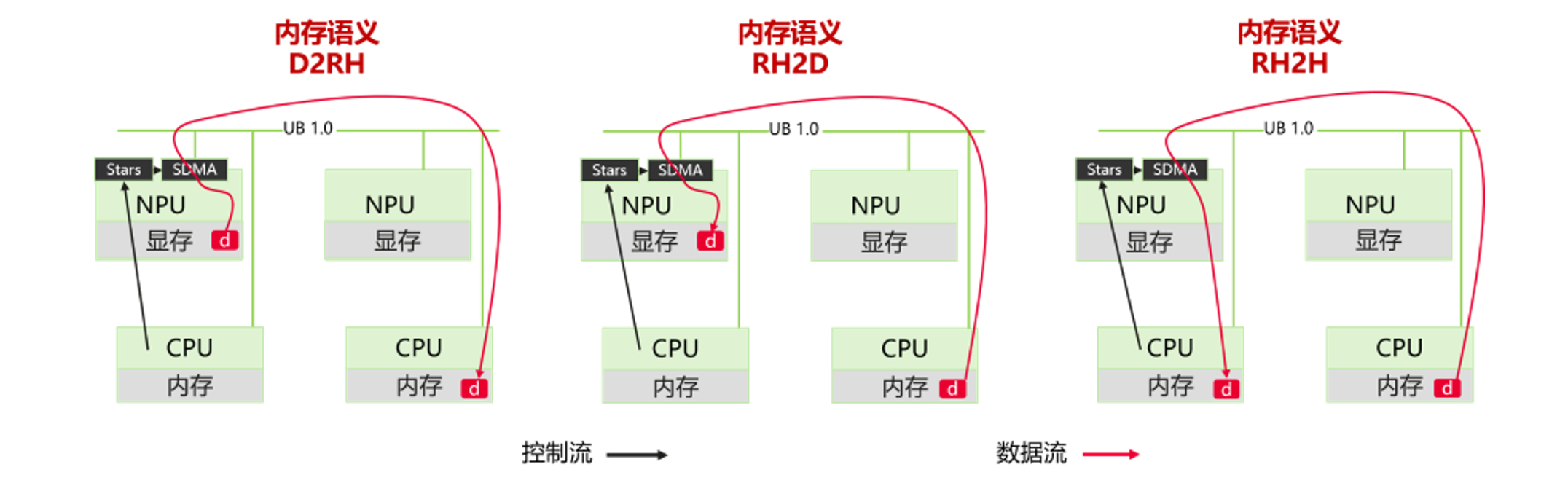 图6. 内存语义跨机异构内存数据流和控制流
图6. 内存语义跨机异构内存数据流和控制流
为充分证明上述方案的竞争力和价值,针对上述内存池设计了一系列相关的性能验证测试。
一、时延测试
读写时延是衡量内存池性能的重要指标,为对比测试内存语义和非内存语义,我们将MemFabric对接到MoonCake TE(MoonCake是业界开源的一款分布式缓存软件)进行如下的测试:
- 测试环境:昇腾A3超节点中2个节点,节点1每个die对应一个写进程,节点2每个die对应一个读进程,共32个进程
- 测试步骤:
1) 构造block模拟DeepSeek-R1模型KV大小,即:61*128K + 61*16K = 8784KB ≈ 8.57MB,共122个离散地址。
2) 节点1所有进程调用put接口每次写入指定个数(8、16、32)的block,每个进程共写512次,统计写总耗时。
3) 节点2所有进程调用get接口读取所有写入的block,每个进程共计读取512次,统计读总耗时。
分别对内存语义(Memory标识,下同)和非内存语义(Message标识,下同)统计测试结果,绘制曲线对比如图7,测试数据反映MemFabric在该场景相比非内存语义方案,时延变化线性,性能优势较明显。
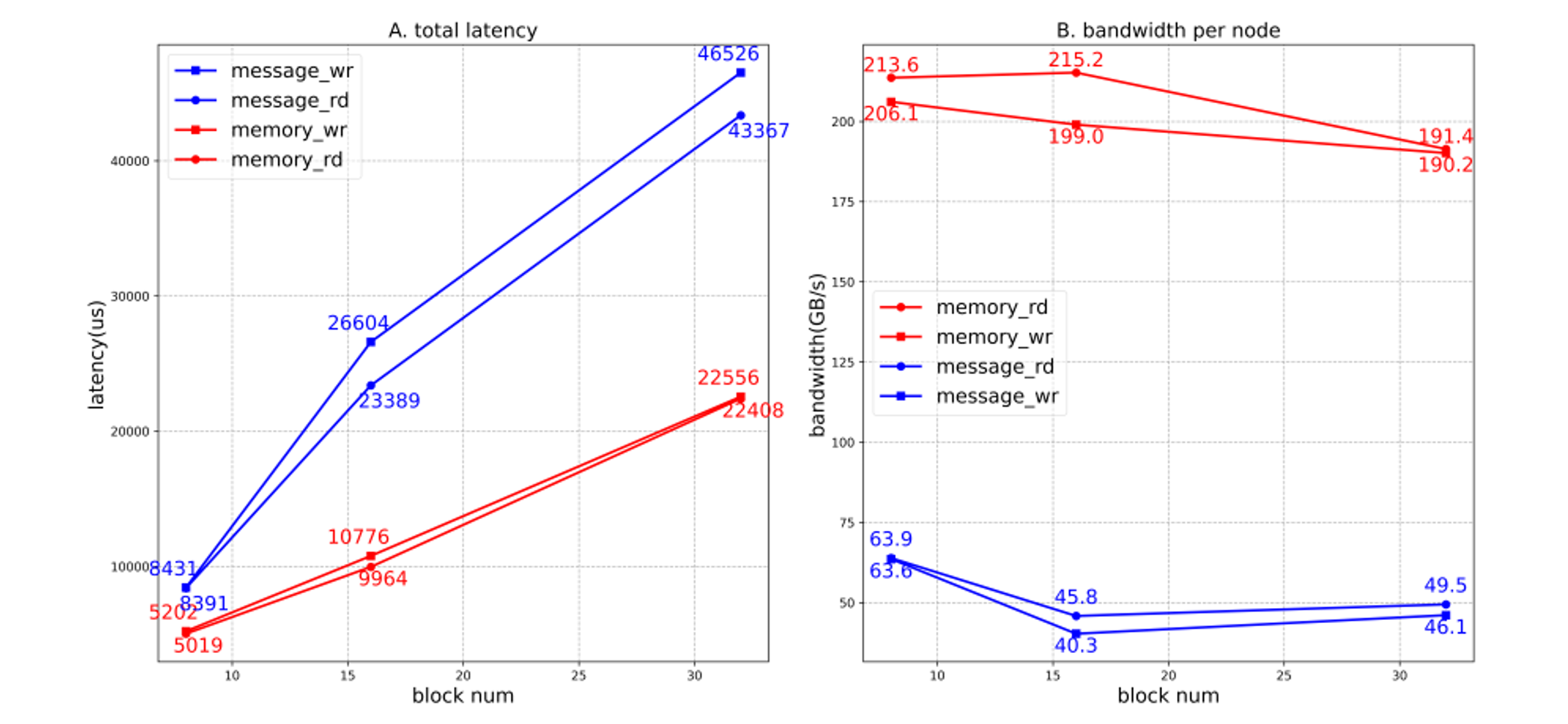 图7. 带宽时延测试对比(内存语义 vs 非内存语义)
图7. 带宽时延测试对比(内存语义 vs 非内存语义)
二、单DIE带宽测试
单die跨机传输带宽是衡量传输性能的重要指标,反映了对硬件资源的利用能力,为此,针对MemFabric做如下测试。
- 测试环境:昇腾A3超节点中2个节点
- 测试步骤:
1) 构造单次拷贝数据大小1GB/2GB,连续内存
2) 进行RH2LD测试,循环调用RH2LD拷贝1000次,取时延平均值
3) 进行LD2RH测试,循环调用LD2RH拷贝1000次,取时延平均值
4) 进行LD2RD测试,循环调用LD2RD拷贝1000次,取时延平均值
5) 进行RD2LD测试,循环调用RD2LD拷贝1000次,取时延平均值
录取测试结果如表1所示,测试结果反映,MemFabric能比较充分的发挥出单die带宽的硬件能力。
表1. 单die跨机带宽测试
数据传输方向 | 单次数据量/GB | 耗时/ms | 估算带宽/GB/s |
|---|---|---|---|
跨机RH2LD | 1 | 9.741 | 102.66 |
2 | 19.49 | 102.62 | |
跨机LD2RH | 1 | 14.405 | 69.42 |
2 | 28.81 | 69.42 | |
跨机LD2RD | 1 | 7.78 | 128.53 |
2 | 15.56 | 128.53 | |
跨机RD2LD | 1 | 6.45 | 155.04 |
2 | 12.9 | 155.04 |
三、 PrefixCache吞吐测试
在大模型推理中,尤其是需要长上下文或高并发处理请求时,KVCache的高效复用与调度成为关键,此类缓存需要在NPU显存、CPU内存乃至 SSD之间频繁迁移,若无良好的池化支持,将导致显存拥堵和请求阻塞,因此,此场景是内存池化软件重要的应用场景。MemCache联合国内某头部互联网AI部门,基于vLLM推理框架在昇腾A3超节点进行Prefill吞吐QPS测试,测试系统示意图如下图8所示:
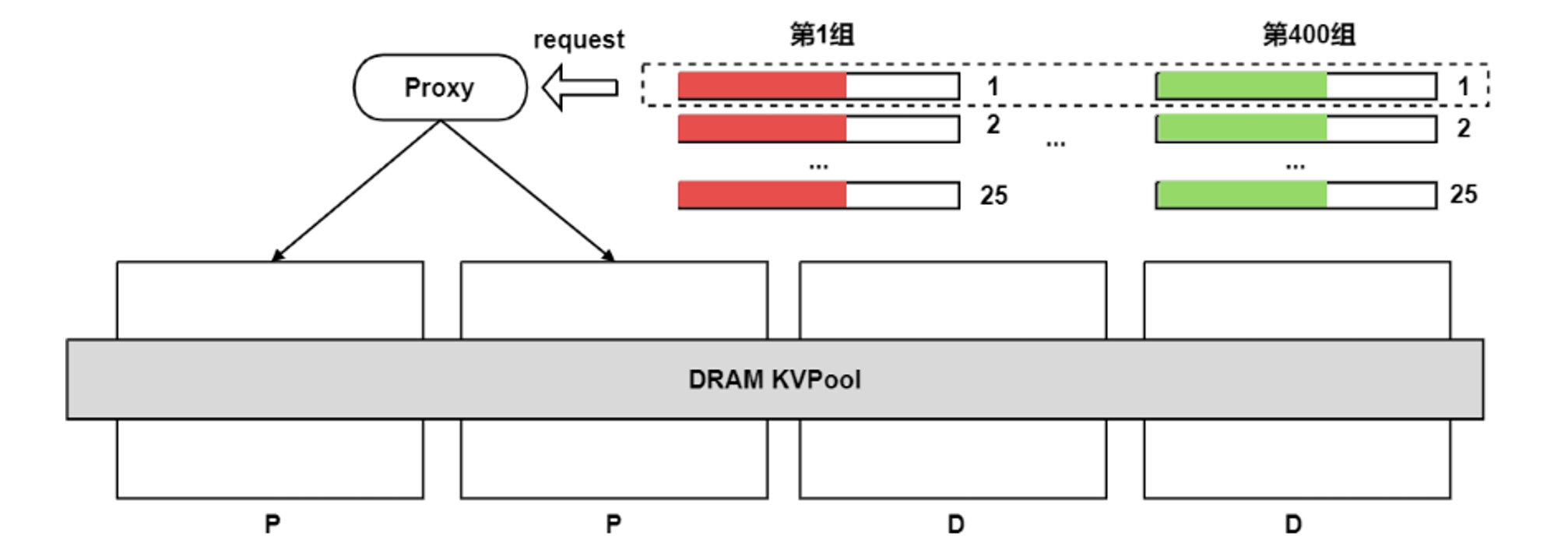 图8. Prefill QPS吞吐测试系统
图8. Prefill QPS吞吐测试系统
- 性能评估指标:昇腾A3超节点的4个节点组成2P1D(D是2机),观察P节点归一化QPS的提升,测试模型为DeepSeek-R1
- PrefixCache KVPool配置:每台机器贡献40GB*16die共640GB的CPU内存,组成4机共2.5TB的KVPool,存储最高水位85%,超过最高水位后淘汰5%
- benchmark 配置:请求输入token长度为4K,输出token为1;一共400组不同的前缀,每组发送25个请求,共约1w条请求;
- 命中率构造:每组请求通过相同前缀长度来构造命中率,在发送请求时,先发送每组的第一个请求(400个),再发送每组的第二个请求(400个)以此类推;在发送每组第二个请求时,保障了其第一个请求不会被换出。
- 分别对无KVPool(Baseline标识),内存语义KVPool(Memory标识)和非内存语义KVPool(Message标识)进行测试,绘制QPS吞吐对比曲线如图9,测试数据反映MemCache在此场景能够带来较大性能收益,相比非内存语义方案,吞吐提升较明显。
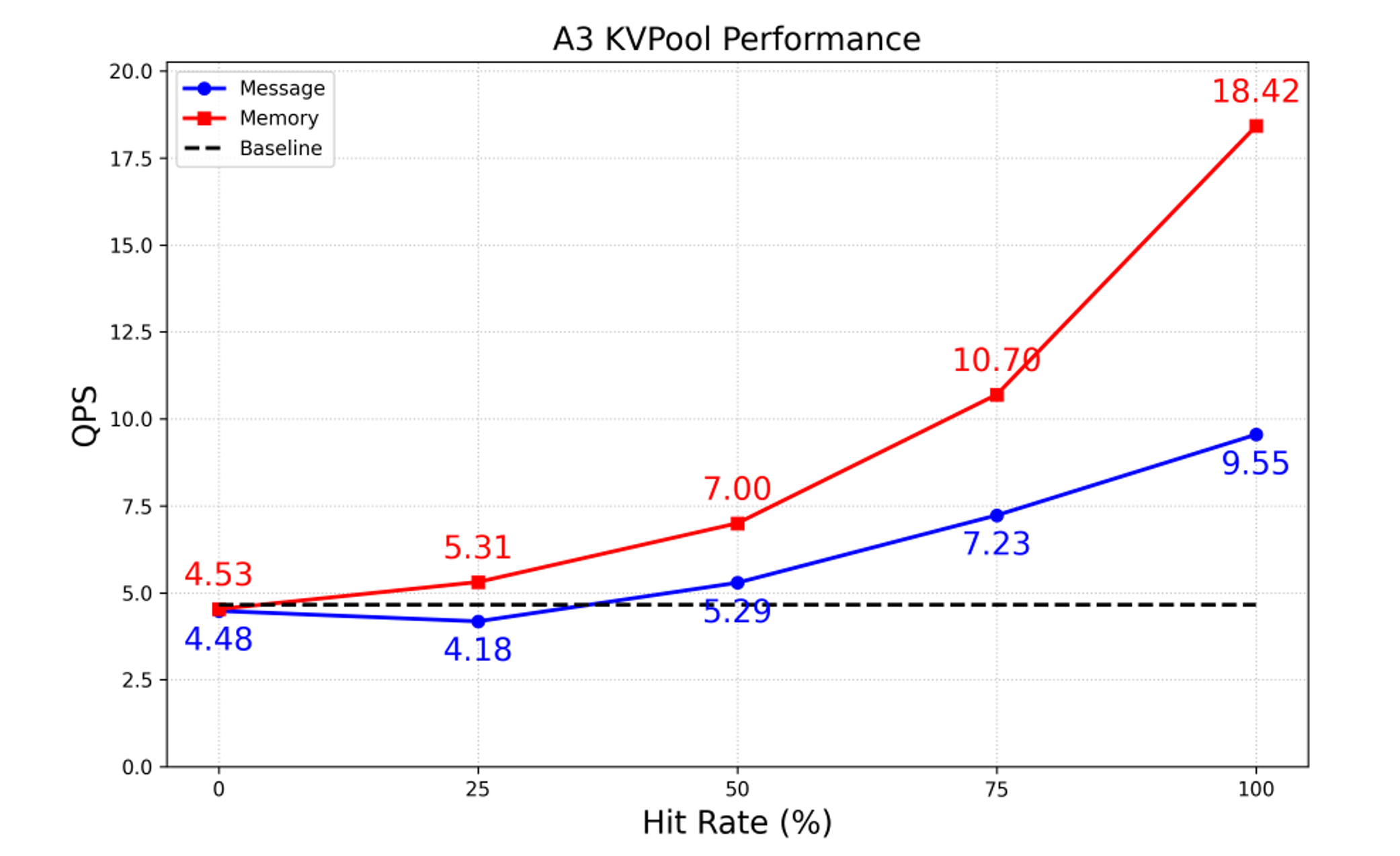 图9. Prefill QPS吞吐对比测试
图9. Prefill QPS吞吐对比测试
加入我们,共建内存语义池化基础设施
MemCache正处于开源建设阶段,很多功能还在不断完善中,欢迎大家访问试用,提出宝贵的建议或意见,开源地址:
https://gitcode.com/Ascend/memcache
同时,内存语义核心组件MemFabric也已经开源,欢迎大家访问试用,提出宝贵的建议或意见,MemFabric开源社区地址:
https://gitcode.com/Ascend/memfabric_hybrid
MemFabric性能测试Benchmark:
https://gitcode.com/Ascend/memfabric_hybrid/blob/master/example/bm/BmBenchmark/README.md
MemFabric使用样例:
https://gitcode.com/Ascend/memfabric_hybrid/blob/master/example/bm/BmCpp/README.md