



vLLM-Omni全模态模型服务发布!昇腾快速上手体验
发表于: 2025/12/02
自 vLLM 诞生以来,一直专注于为大型语言模型(LLMs)提供高吞吐量、内存高效的推理服务。然而,生成式 AI 的格局正在迅速变化。模型不再仅仅是文本输入、文本输出的工具。如今的顶尖模型能够在文本、图像、音频和视频之间进行推理,并使用不同的架构生成异构输出。

为了更好的全模态模型推理服务的支持,vLLM社区在12月1日发布了 vLLM-Omni(vllm-project/vllm-omni)项目。vLLM-Omni 是首个支持全模态模型推理的插件,它将 vLLM 卓越的性能扩展到了多模态和非自回归推理领域。
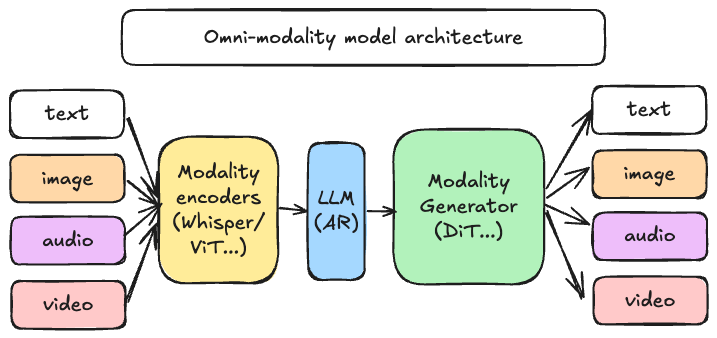
为什么是 vLLM-Omni?
传统推理服务引擎的优化重心集中于文本类自回归(AR)任务。而随着模型逐步演进为 “全模态智能体”—— 具备视觉、听觉与语言交互能力,推理服务基础设施也需同步迭代升级。
vLLM-Omni 针对性解决了模型架构演进中的三大核心能力:
- 原生全模态支持:无缝处理并生成文本、图像、视频、音频等多模态数据,打破单一模态局限;
- 突破自回归边界:将 vLLM 高效的内存管理技术,拓展至Diffusion扩散模型等并行生成模型,覆盖更多模型类型;
- 异构模型流水线调度:支持单请求触发多异构模型组件的复杂工作流编排,例如多模态编码、自回归推理、扩散式多模态生成等场景。
我们与vLLM-Omni项目的开发者共同完成了昇腾支持和验证。这意味着开发者现在就可以一键拉起基于vLLM-Ascend容器镜像在昇腾设备上实现Qwen Omni(Omni全模态模型)、Qwen Image(Diffusion扩散模型)等模型的推理。
基于昇腾的快速上手体验
第一步,安装并启动服务
在体验之前,需确认固件/驱动已正确安装,可运行如下命令确认:
npu-smi info可以使用如下命令,一键拉起 vLLM Ascend 容器镜像:
# Update DEVICE according to your NPUs (/dev/davinci[0-7])
export DEVICE0=/dev/davinci0
export DEVICE1=/dev/davinci1
# Update the vllm-ascend image
# Atlas A2:
# export IMAGE=quay.nju.edu.cn/ascend/vllm-ascend:v0.11.0rc2
# Atlas A3:
# export IMAGE=quay.nju.edu.cn/ascend/vllm-ascend:v0.11.0rc2-a3
export IMAGE=quay.nju.edu.cn/ascend/vllm-ascend:v0.11.0rc2
docker run --rm \
--name vllm-omni-npu \
--shm-size=1g \
--device $DEVICE0 \
--device $DEVICE1 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 8000:8000 \
-it $IMAGE bash拉取源码进行安装(包含example代码的下载):
cd /vllm-workspace
git clone -b v0.11.0rc1 https://github.com/vllm-project/vllm-omni.git
cd vllm-omni
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install -v -e .安装 modelscope 并配置环境变量加速模型下载:
pip install modelscope
export VLLM_USE_MODELSCOPE=True1.Qwen Omni - 全模态模型体验:
在vLLM Omni接下来我们将在昇腾环境中,使用 vLLM Omni 运行 Qwen2.5-Omni,使用仓库已有的 examples 即可快速体验 Qwen2.5-Omni 语音生成:
echo "请用15字内解释可扩展音频生成流程的系统架构" > examples/offline_inference/qwen2_5_omni/prompt.txt
VLLM_WORKER_MULTIPROC_METHOD=spawn VLLM_USE_MODELSCOPE=True \
python examples/offline_inference/qwen2_5_omni/end2end.py \
--output-wav output_audio \
--query-type text \
--txt-prompts examples/offline_inference/qwen2_5_omni/prompt.txt该示例要求“请用15字内解释可扩展音频生成流程的系统架构”,生成如下文本及其音频:
嗯...这个嘛,就是先输入数据,然后经过算法处理,最后输出音频。你要是还有啥想知道的,尽管再问哈。2.Qwen Image - Diffusion 扩散模型图片生成体验
使用仓库已有的 examples 即可快速体验 Qwen-Image 图片生成:
VLLM_USE_MODELSCOPE=True python examples/offline_inference/qwen_image/text_to_image.py \
--prompt "a cup of coffee on the table" \
--seed 42 \
--cfg_scale 4.0 \
--num_images_per_prompt 1 \
--num_inference_steps 50 \
--height 1024 \
--width 1024 \
--output outputs/coffee.png该示例要求"生成一杯在桌子上的咖啡图片",生成如下图片:

未来规划
下一步,我们将与vLLM社区开发者共同完善vLLM Omni,不断扩展全模态、多模态、扩散模型等主流模型的昇腾支持,更进一步提升推理性能。我们诚挚邀请社区伙伴共同参与,携手塑造 vLLM-Omni 的未来发展方向。您可以通过已有的GitHub 仓库和用户文档来了解更多的细节,也可以通过参加我们的每周例会(每周三上午 11:30),与我们共同讨论Roadmap和新功能。让我们共同携手,构建多模态服务的未来!
GitHub 仓库:https://github.com/vllm-project/vllm-omni
用户文档:https://docs.vllm.ai/projects/vllm-omni/en/latest