



MindStudio全新负载均衡调优工具,减少算力资源浪费,让推理更快更稳
发表于: 2025/10/30
负载不均导致的性能难题
随着大模型技术从训练走向落地,推理阶段的效率与资源利用率,已成为企业降本增效的核心诉求。但现实常常令人沮丧:“推理部署上线了,性能却远低于预期”。有些卡忙到爆,有些卡却闲着转;MoE 模型里,部分专家被“挤爆”,其他专家在“摸鱼”;Prefill/Decode 比例没调准,节点之间互相等待,算力远远没有跑满。
这一切的根因,其实可以用一句话概括——负载不均衡。在当前主流的大模型推理架构中,三类负载均衡技术已经成为效率底线,并逐渐演化为可落地的实践方案:
- DPLB(Data Parallel Load Balancer):优化数据并行下的任务分配,让计算均衡分布在各节点上,避免“有的卡很忙、有的卡很闲”;
- EPLB(Expert Parallel Load Balancer):采用冗余专家和分层均衡算法,动态调整专家路由,缓解部分专家过载、部分专家空转的问题;
- P/D 分离部署:合理配置 Prefill/Decode 节点比例,匹配不同阶段的算力需求,避免单一环节成为瓶颈。
问题在于,这些方案“纸面上很香”,落地时却让研发团队频频卡壳:
- 看不见:DP 域里哪张卡的 batch size 突然翻倍?EP 层哪个专家暗中过载?PD 节点早高峰的请求量到底涨了多少?负载问题藏在黑盒里,排查像“盲人摸象”;
- 测不准:改了 DPLB 的调度参数,batch size 波动是偶然还是必然?调整 PD 节点比例后,请求分发是否真的均衡?没有量化数据,优化全凭感觉。
“看不见、测不准”的困境,成了大模型推理效率提升的最大障碍。
MindStudio负载均衡调优工具
针对上述痛点问题,MindStudio的服务化调优工具msServiceProfiler 新增了“负载均衡分析与优化”能力:拆开服务化推理“黑盒”,围绕 DP、EP、P/D 三个维度提供端到端观测、瓶颈定位与优化建议。让开发者能看得见、调得准、改得快,真正释放集群潜能。
核心能力一: DP 域的 “身份证 + 泳道图”,负载差异一眼看穿
在数据并行(DP)里,最怕的就是“同域不同命”——dp0 拼命干活,dp1 在摸鱼。以前查原因像“摸黑找人”。msServiceProfiler 直接给 DP 域装了 “双保险,从“猜哪域有问题”到“看哪域有问题”,10 秒锁定 batch size 不均、显存瓶颈,让 DPLB 优化有了精准靶子。
使用MindStudio Insight可视化工具,可以查看服务化推理的Trace图。
1. 如图1所示,采集工具给每个推理进程打上清晰的 dp_rank 标识,相当于发了“身份证”。每个 DP 域都有一条“泳道”,展示 batch size、KVCache 占用曲线,就像看交通路况图。
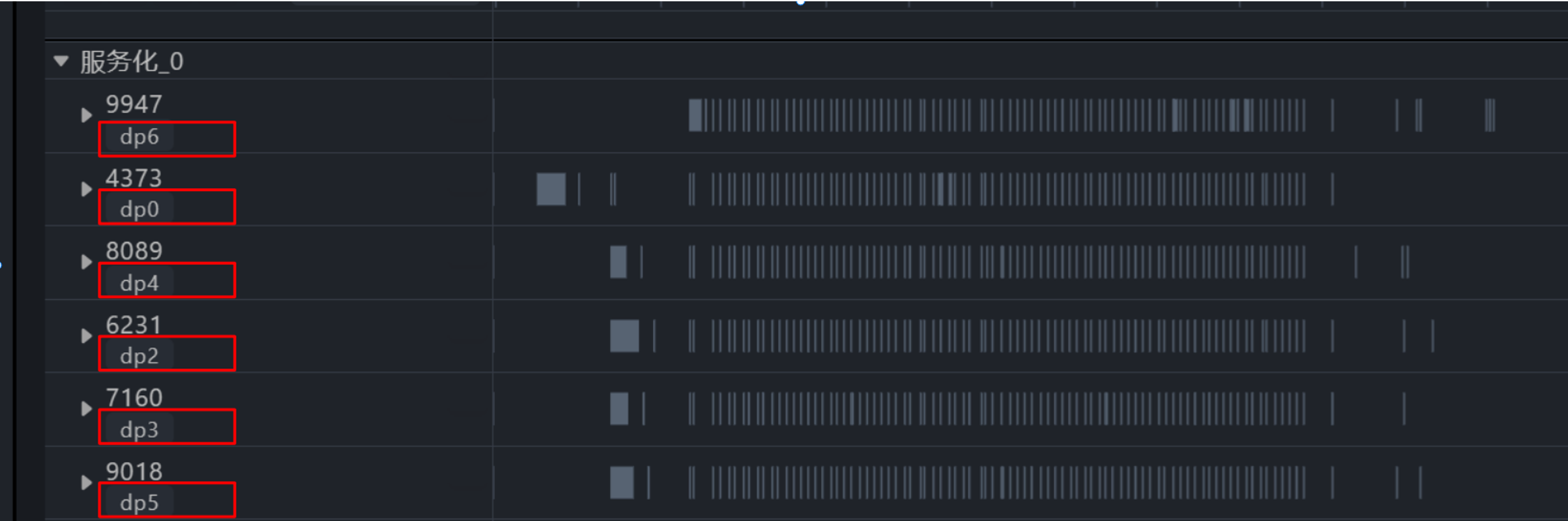
图1. 多DP域泳道展示图
在每个DP域泳道中,可直接查看该DP域上每轮请求调度的batch size大小(如图2所示),以及KVCache显存占用情况(如图3所示),助您分析请求调度及算力使用情况。
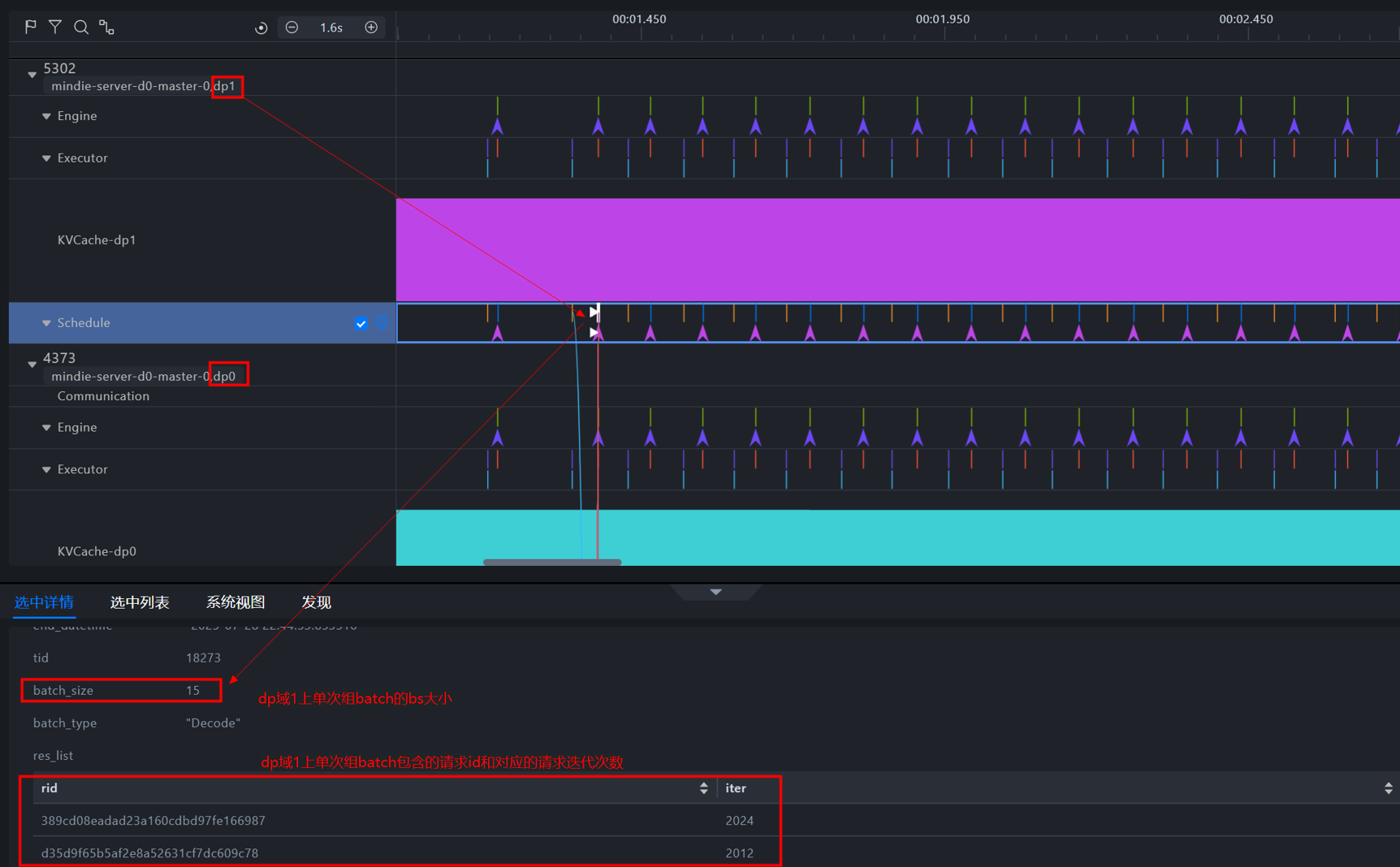
图2. 多DP域batch size展示图。图中展示了当前选中的dp1中单次组batch的batch size大小为15
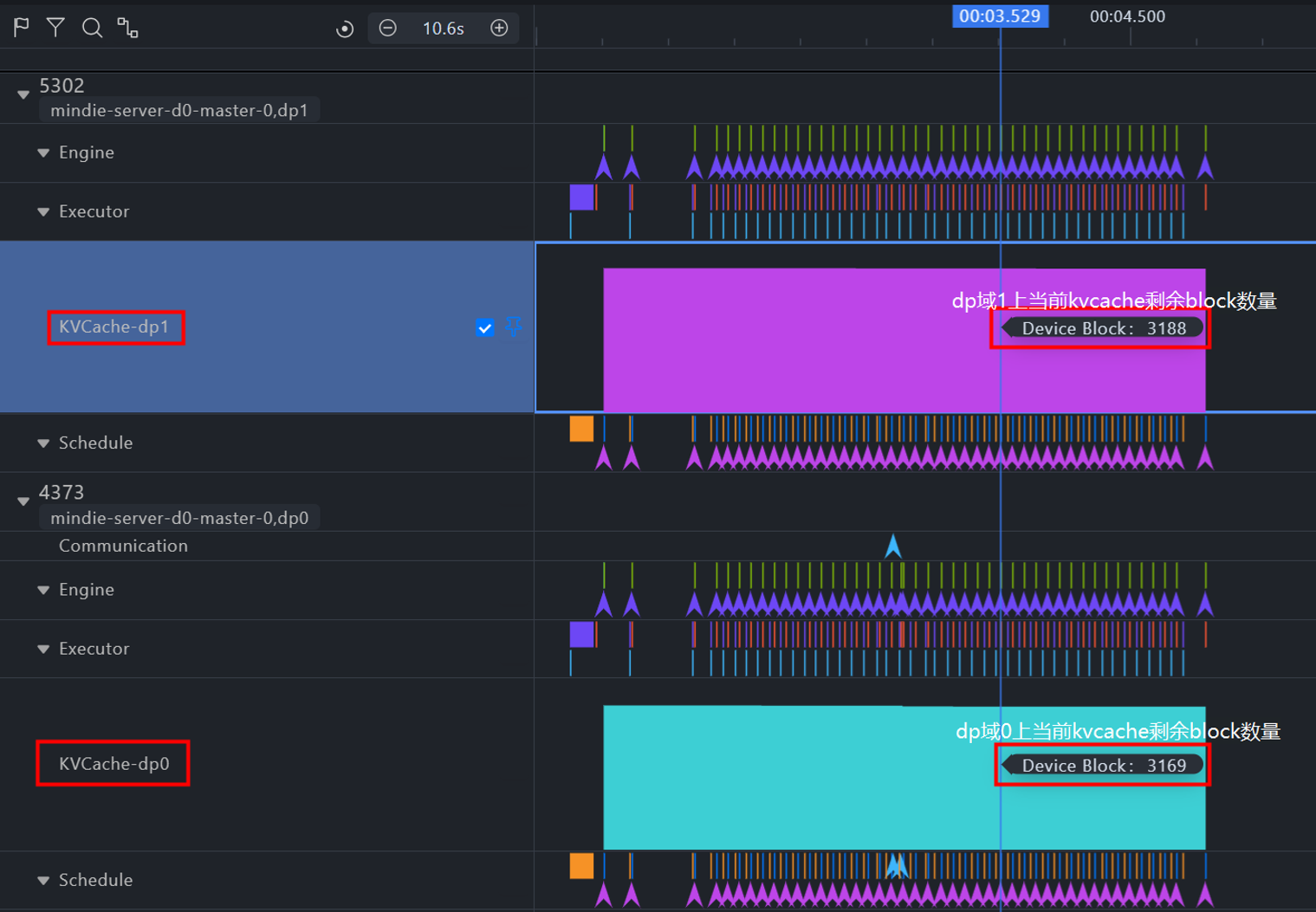
图3. 多DP域KVCache占用情况展示图。图中KVCache-dp0、KVCache-dp1两个泳道中分别展示了dp域0、1上当前kvcache剩余的block数量
2. 工具还会导出 CSV,记录 prof_id(卡的唯一标识)、forward_iter(推理次数)、dp_rank(域归属),配合折线图一眼看到 batch size 异常波动。
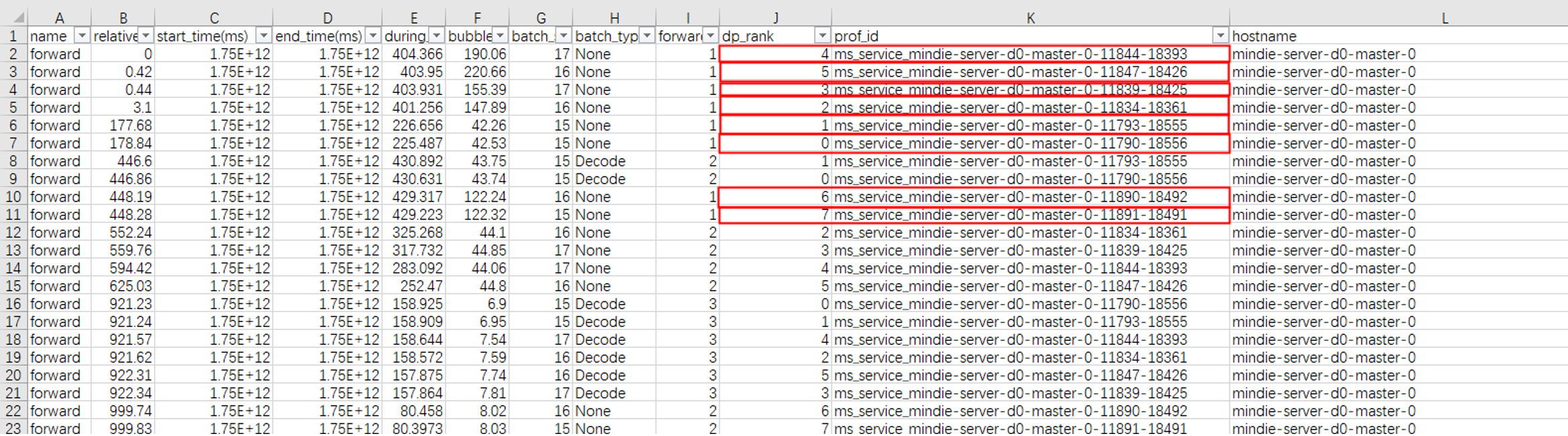
图4. 多DP域CSV结果展示图
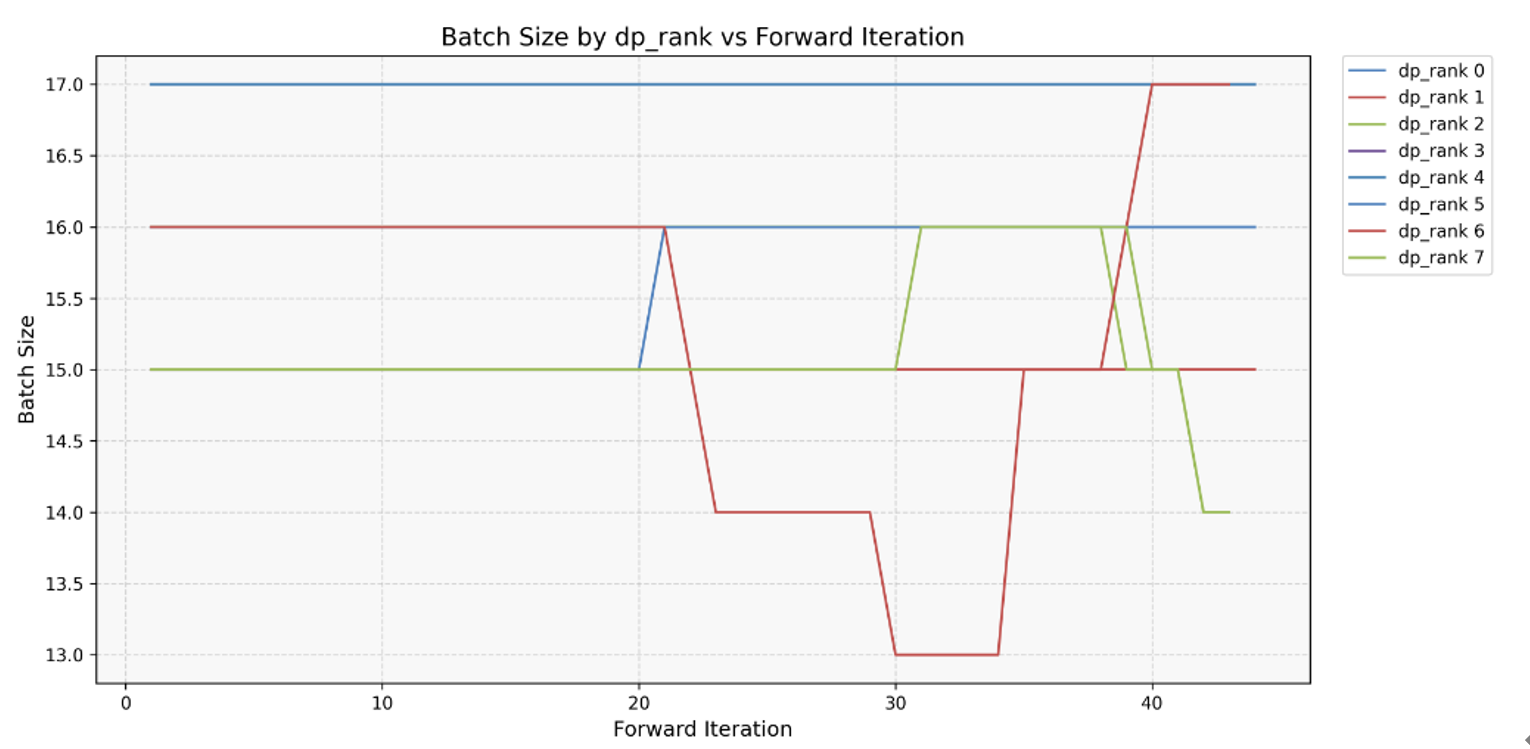
图5. 多DP域batch size变化折线图。基于图4 CSV文件生成的折线图,展示不同数据并行等级(dp_rank)下batch size随模型推理次数(forward_iter)的变化趋势
核心能力二:节点负载的 “时间心电图”,请求波动全记录
分布式推理场景中,PD实例的配比可能不合适,导致P或者D出现性能瓶颈。也可能多个P实例的请求并不均匀,有的P实例请求很多,有的P实例请求很少。msServiceProfiler工具支持精细化请求统计,量化请求在各个节点上的分发情况,为分析整个系统的负载情况提供数据依据。
1. 工具支持生成CSV交付件,按时间序列记录每个时刻点:
- P节点/D节点上新增的请求数量;
- 结束的请求数量;
- 正在运行的请求数量。
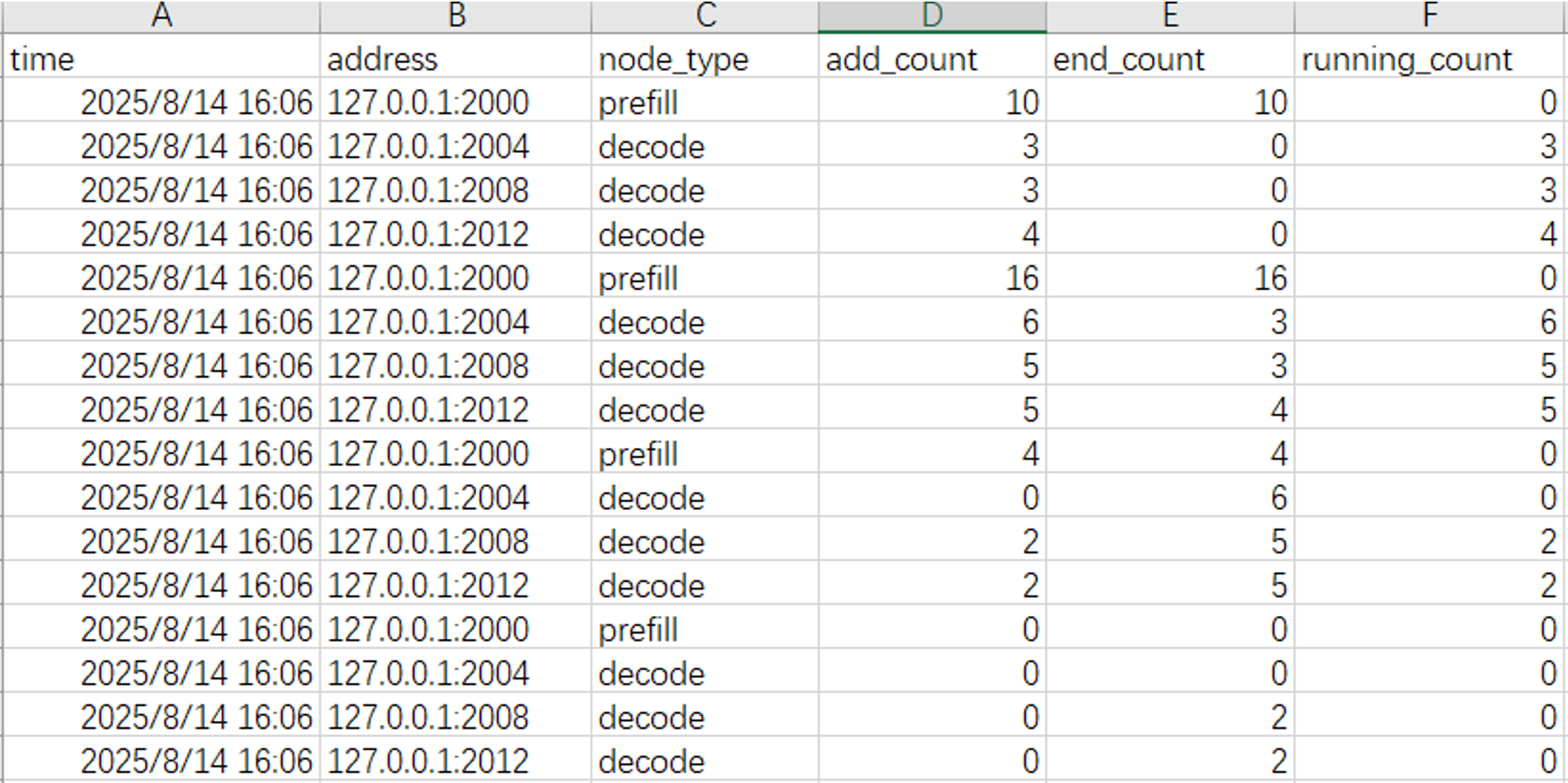
图6. PD节点请求数量展示图
2. 工具提供折线图,直观展示各个节点在不同时刻的请求新增数量变化趋势。通过折线图,可以轻松识别出是否存在某个节点在特定时刻请求负载过高,发现负载倾斜问题。
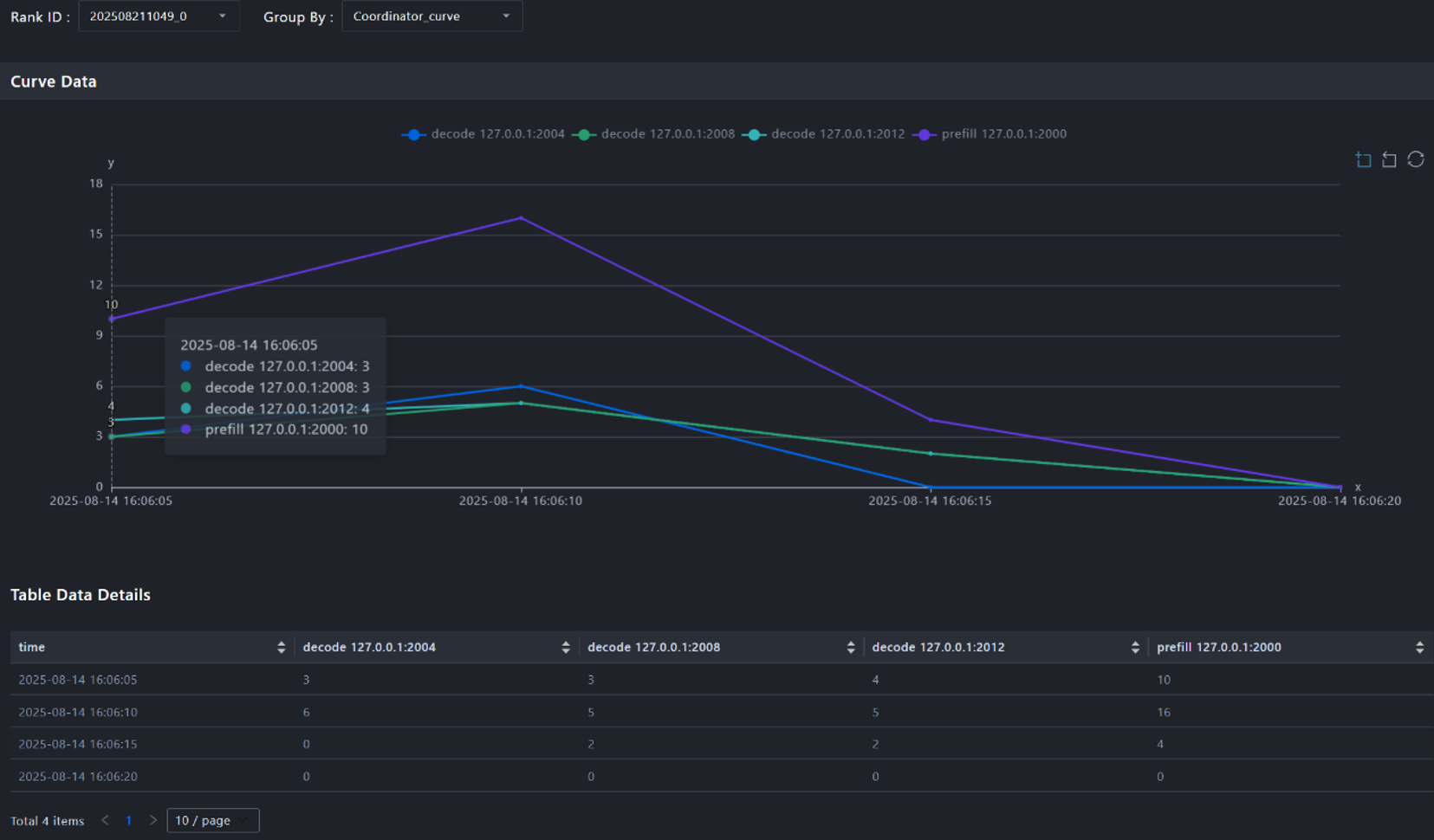
图7. PD节点请求数量变化折线图
核心能力三:专家负载的 “热力地图”,冷热专家全曝光
MoE 模型里的专家,就像一群老师,有的教室挤满学生,有的却空无一人。肉眼很难看清到底哪位老师最受追捧。MoE负载不均时,各专家的访问次数存在显著差异,计算资源分配不均衡。msServiceProfiler工具支持直观的专家负载均衡效果展示,能够及时发现专家负载不均情况,识别特定专家或节点的过载现象,指导专家负载均衡策略调优。
1. 工具支持生成热力图,在宏观上展示各张卡(Rank)在不同层上的负载分布,在微观上展示每张卡上各个专家(Expert)在不同层上的被访问频率,也就是负载情况。
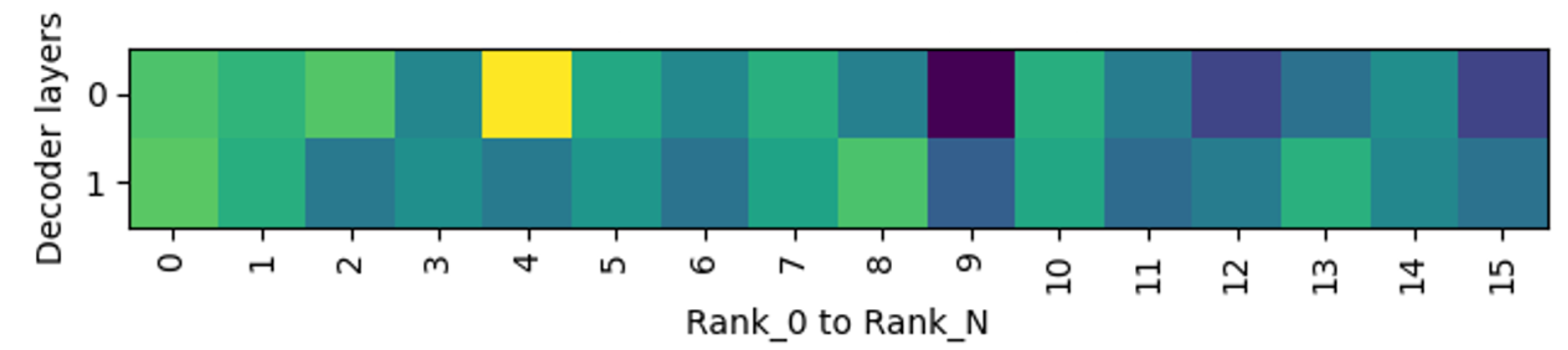
图8. Rank-Layer热力图:展示不同卡(rank0-rankN)在不同层(Decoder Layer)上的负载分布,从黄色(高频率)到绿蓝色(低频率)

图9. Expert-Layer热力图:展示不同卡(rank0-rankN)上,各个专家(Expert)在不同层(Decoder Layer)上的负载情况。图中显示,每张卡部署有17个专家(含1个共享专家)。整体来看,每张卡上,序号较小的专家访问频率较高,而序号较大的专家访问频率则逐渐降低
2. 在动态负载均衡场景下,每组数据会额外新增一张热力图,展示各个专家(Expert)在不同层(Decoder Layer)上的被访问频率,也就是负载情况。
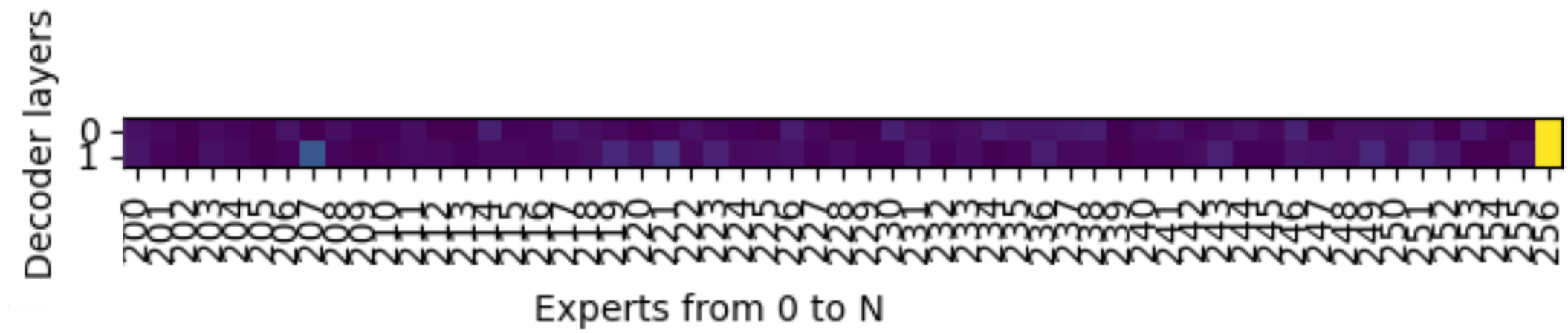
图10. Expert-Layer热力图:图中显示,从200-256号专家中,最后一位256号共享专家的访问频率最高。
msServiceProfiler工具使用指南
1. 环境准备
环境已安装CANN包,依据指导部署MindIE推理服务化框架,能正常执行模型推理。
参考资料:
https://www.hiascend.com/document/detail/zh/mindie/21RC2/envdeployment/instg/mindie_instg_0001.html
2. 数据采集
采集负载均衡数据之前,需要首先拉起推理服务化,并采集服务化性能数据。具体流程如下。
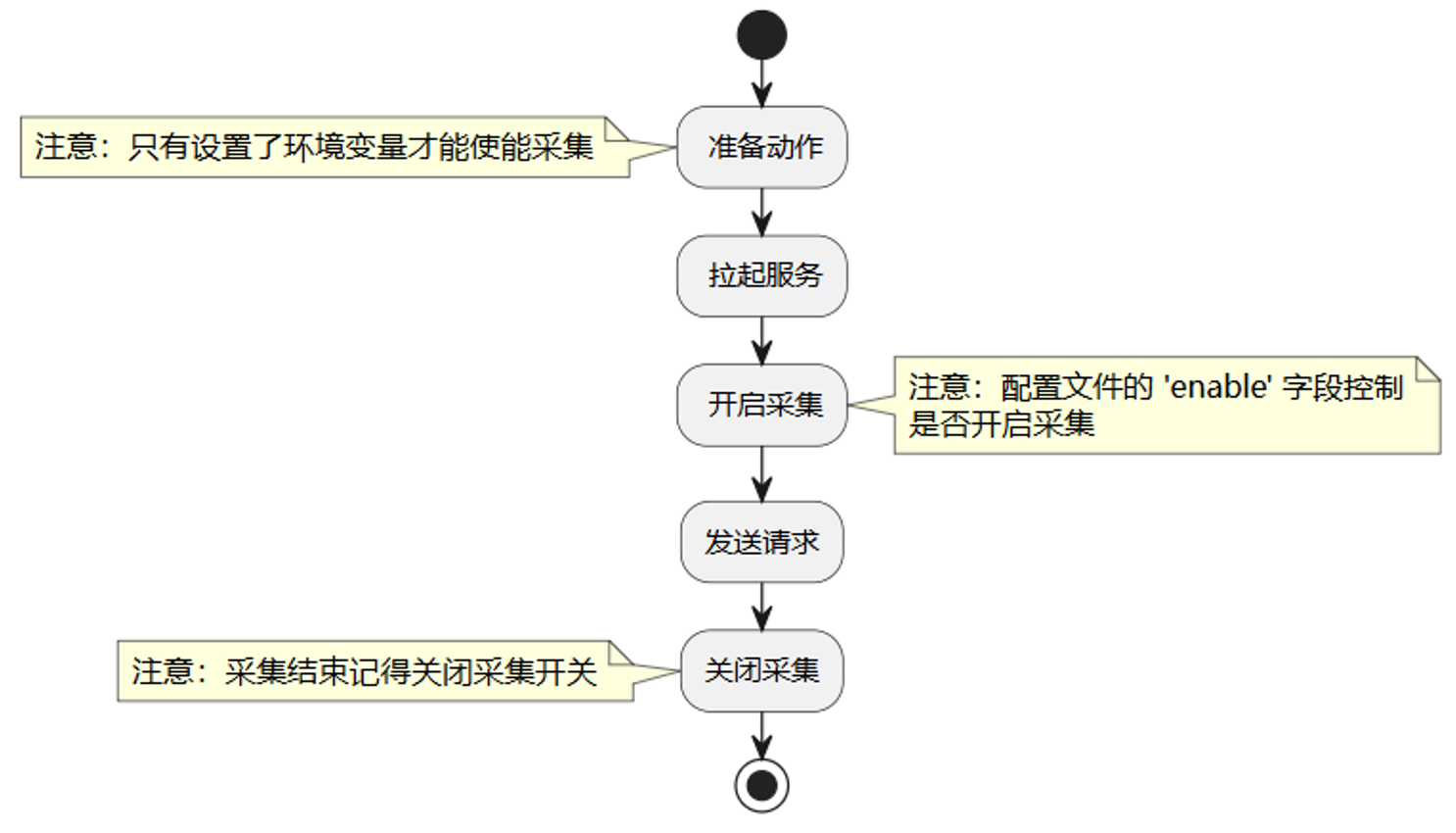
图11. 服务化性能数据采集流程
Step1. 准备动作。使能服务化配置文件环境变量。服务化性能数据采集通过json配置文件,配置采集数据的开关、保存路径等。配置如下环境变量,会自动创建默认配置的json文件。
export SERVICE_PROF_CONFIG_PATH=/your/config/path/ms_service_profiler_config.json
# 如需采集专家负载均衡数据,还需要额外配置:
export MINDIE_ENABLE_EXPERT_HOTPOT_GATHER=1
export MINDIE_EXPERT_HOTPOT_DUMP_PATH=/weight/path/to/model/Step2. 拉起服务。运行MindIE-Motor服务,具体参考https://www.hiascend.com/document/detail/zh/mindie/21RC2/mindieservice/servicedev/mindie_service0004.html。
成功后会看到Daemon start success!日志,当前为未开启Profiling数据采集状态。
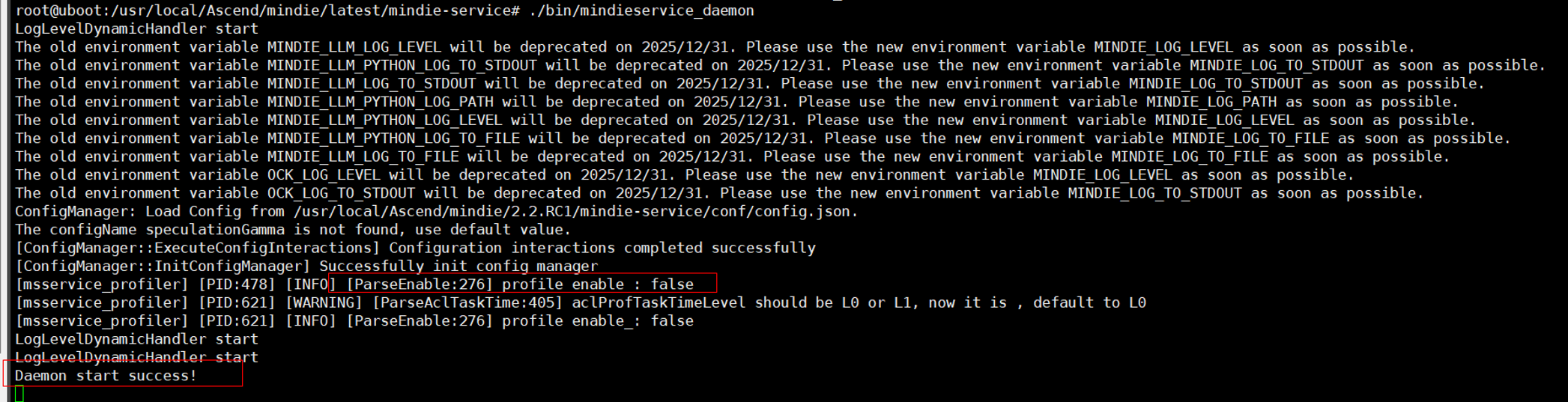
Step3. 开启采集。修改配置文件:
sed -i 's/"enable":\s*0/"enable": 1/' /your/config/path/ms_service_profiler_config.json # 修改配置文件中的 'enable' 字段由 0 改为 1开启采集还可通过修改该文件中的prof_dir字段控制采集到的性能数据的存放路径。采集时,会在prof_dir参数指定的路径下落盘Profiling性能数据。prof_dir默认为/root/.ms_server_profiler。
成功开启采集会出现如下日志:

更多采集参数配置说明请参考:https://www.hiascend.com/document/detail/zh/mindstudio/82RC1/T&ITools/Profiling/atlasprofiling_16_0029.html
Step4. 向推理服务端发送请求。请求发送方式可参考下述链接中的步骤2:
https://www.hiascend.com/document/detail/zh/mindie/21RC2/mindieservice/servicedev/mindie_service0004.html
请至少保证有一条请求正常推理结束,以下图为例:

Step5. 关闭采集。修改配置文件:
sed -i 's/"enable":\s*1/"enable": 0/' /your/config/path/ms_service_profiler_config.json # 修改配置文件中的 'enable' 字段由 1 改为 0,关闭采集成功关闭采集会出现如下日志:

3. 数据解析
Step1. CANN环境变量使能。source CANN包安装路径下的环境变量。例如,
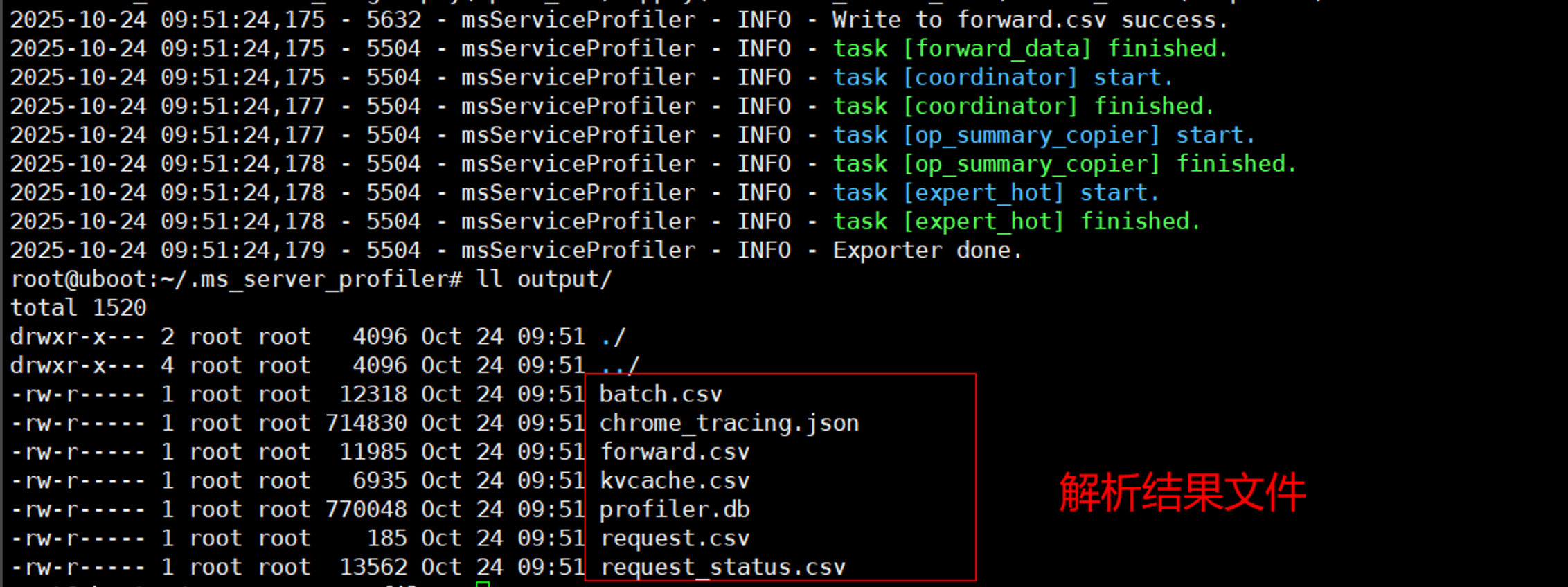
source /usr/local/Ascend/ascend-toolkit/set_env.sh #/usr/local/Ascend为CANN包安装路径。Step2. 执行解析命令。
python3 -m ms_service_profiler.parse --input-path= /profiling/data/directory/prof_dir/--input-path需指定为数据采集中prof_dir参数设置的路径。解析完成后,默认在当前目录下生成output文件夹,其中包含上述CSV及可视化原始文件。如下图所示:
更多解析命令行接口说明请参考:
解析结果文件说明请参考:
4. 数据可视化
解析后的性能数据支持多种可视化方式,推荐使用MindStudio Insight工具可视化。可通过将数据解析中获得的profiler.db或chrome_tracing.json导入MindStudio Insight获得泳道图和折线图等。
详细使用说明请参考:
总结
msServiceProfiler 全新负载均衡调优工具,通过采集落盘Profiling数据,打开复杂推理系统是黑盒,为负载均衡提供了精准的标尺。它让团队能够“看得清、调得准、控得住”,将技术方案的价值切实转化为降本增效的成果。目前工具已经发布,欢迎广大开发者试用,感受精准优化带来的性能提升。