



昇腾推理微服务+多模态SDK,构建视频知识提取应用实践
发表于: 2025/09/29
昇腾推理微服务+多模态SDK,构建视频知识提取应用实践
1 简介
本文基于Atlas 800I A2服务器,使用:视频分析与理解推理微服务(基于qwen2.5-vl-32b-instruct)以及多模态SDK,构建了视频知识提取应用。
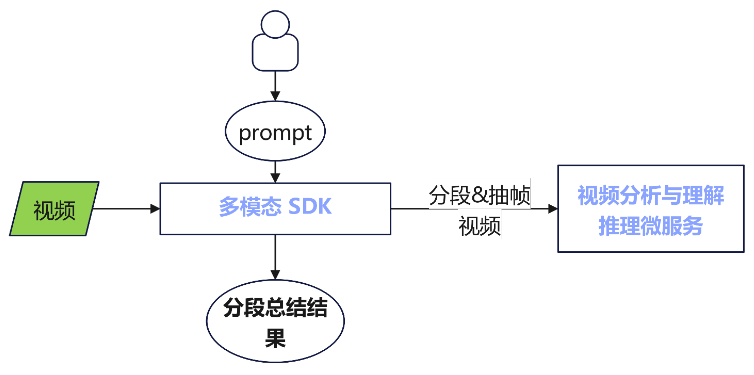
多模态视频知识提取应用框架图
| 组件名 | 功能简介 |
|---|---|
| 多模态SDK | 多模态SDK提供了视频分块、帧抽取、视频解码、视频预处理、多模态知识提取等原子加速能力。 |
| 视频分析与理解推理微服务 | 视频分析与理解的智能服务。为开发者提供RESTful API接口以高效处理和分析视觉数据,提供精准的视图理解能力。 |
2 支持的产品和版本
| 产品 | CANN 版本 | 多模态SDK版本 | 系统推荐 |
|---|---|---|---|
| Atlas 800I A2 | 8.2.RC1 | 7.2.T4 | Ubuntu 20.04.6 |
3 快速部署
步骤1:下载微服务容器镜像、下载多模态SDK软件包并安装;
步骤2:启动推理微服务容器;
步骤3:使用多模态视频知识提取应用
3.1 下载微服务镜像与安装多模态SDK软件包
下载
| 镜像名称 | 镜像仓库地址 |
|---|---|
| 视频分析与理解推理微服务镜像(qwen2.5-vl-32b-instruct) | https://www.hiascend.com/developer/ascendhub/detail/3c2cac7ad7f74583bfe419800a71341c |
| 多模态SDK软件包 | https://support.huawei.com/enterprise/zh/ascend-computing/mindx-pid-252501207/software/266619255?idAbsPath=fixnode01|23710424|251366513|254884019|261408772|252501207 |
检查镜像加载情况
docker images检查软件包完整性
chmod u+x Ascend-mindxsdk-multimodal_{version}_linux-{arch}.run./Ascend-mindxsdk-multimodal_{version}_linux-{arch}.run --check若显示如下信息,说明软件包已通过校验。
Verifying archive integrity... 100% SHA256 checksums are OK. All good. 安装多模态SDK软件包
若用户未指定安装路径,则将安装在当前路径下。若用户指定了安装路径,将安装在指定的路径下。以安装路径“/home/work/Mind_SDK”为例
./Ascend-mindxsdk-multimodal_{version}_linux-{arch}.run --install --install-path=/home/work/Mind_SDK设置安装包的环境变量
. /home/work/Mind_SDK/multimodal-7.2.T4/script/set_env.sh安装结果验证,打开python3,执行如下命令导入包,包导入成功则表示安装成功:
import mm如果需要卸载,请执行如下命令:
. /home/work/Mind_SDK/multimodal-7.2.T4/script/uninstall.sh3.2 启动推理微服务
启动视频分析与理解推理微服务
# 设置本地缓存路径
export LOCAL_CACHE_PATH=/data/models
# 设置容器名称
export CONTAINER_NAME=qwen2.5-vl-32b-instruct
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/qwen2.5-vl-32b-instruct:7.2.T4-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=0,1,2,3 \
-e MIS_CONFIG=atlas800ia2-4x32gb-bf16-vllm-default \
-e MIS_LIMIT_VIDEO_PER_PROMPT=1 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
-p 8000:8000 \
--shm-size 1gb \
$IMG_NAME
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}确认推理微服务启动状态
执行启动命令后,在对应的微服务启动界面显示如下内容则表示启动成功:
Application startup complete如需关闭对应的推理微服务,执行如下命令即可:
docker stop $CONTAINER_NAME3.3 使用多模态视频知识提取
3.3.1 自定义插件示例
自定义视频抽帧插件,以插件目录为/home/code/sampler/plugins/sampler_case.py为例:
from mm import FrameSampler
@FrameSampler.register("sample_all")
def sampler_case(
frames: list) -> list:
return frames # Sample all frames注意事项:
1. 自定义插件目录和文件权限需为0o550
2. 用户自定义的插件实现,需要通过装饰器来修饰注册,如@FrameSampler.register("插件名")
3. 用户自定义的插件实现,接口格式需为: def sampler(name: str, frames: List[Frame], **params) -> List[Frame],其中Frame为泛帧类型
4. 当前软件包内提供默认均匀采样器功能,不配置frame_sampler_method、frame_sampler_plugin_path字段则默认使用均匀采样抽帧插件
自定义视频分块插件,以插件目录为/home/code/segmenter/plugins/segmenter_case.py为例:
import cv2
from mm import VideoSegmenter
@VideoSegmenter.register("segmenter_one")
def segmenter_case(
video_path: str
) -> list[tuple[float, float]]:
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise ValueError("Unable to open video file!")
fps = cap.get(cv2.CAP_PROP_FPS)
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
duration = frame_count / fps
cap.release()
return [(0.0,duration)]注意事项:
1. 自定义插件目录和文件权限需为0o550
2. 用户自定义的插件实现,需要通过装饰器来修饰注册,如@VideoSegmenter.register("插件名")
3. 用户自定义的插件实现,接口格式需为: def segment(name: str, video_path: str = None, **params) -> List[Tuple[float, float]]
4. 当前软件包内提供默认固定长度分段功能,不配置video_segmenter_method、video_segmenter_plugin_path字段则默认使用固定长度分段插件
3.3.2 知识提取示例
from mm import SummarizeParams, MmKlgExtractHdlr, handle_response
if __name__ == '__main__':
# 初始化知识提取参数配置类SummarizeParams
params = SummarizeParams(
file_path="视频文件地址",
prompt="请对该视频进行摘要总结。",
chunk_time=30.0, # 视频分块的时间长度(以秒为单位)
sample_num_per_chunk=60, # 每个视频分块经帧采样后保留的帧数目
batch_size=1, # 批处理的大小,默认值为1,当前仅支持1
top_p=0.8, # 控制VLM大模型生成过程中考虑的词汇范围
temperature=0.9, # 控制VLM大模型生成的随机性
max_tokens=8092) # 控制VLM大模型输入输出长度
# 初始化多模态知识提取处理器MmKlgExtractHdlr
args = {
"npu_num": 4, # VLM大模型部署的卡数
"npu_ids": [0, 1, 2, 3], # VLM大模型推理使用的NPU卡ID
"vlm_url": http://${微服务机器IP}:8000/openai/v1, # VLM推理微服务地址
"vlm_model_name": "Qwen2.5-VL-32B-Instruct",
"frame_sampler_method": "sample_all", # 视频抽帧插件名,不配置该字段则使用默认均匀采样抽帧插件
"video_segmenter_method": "segmenter_one", # 视频分块插件名,不配置该字段则使用默认固定长度分段插件
"frame_sampler_plugin_path": "/home/code/sampler/plugins", # 视频抽帧插件地址,不配置该字段则使用默认均匀采样抽帧插件
"video_segmenter_plugin_path": "/home/code/segmenter/plugins" # 视频分块插件地址,不配置该字段则使用默认固定长度分段插件
}
handler = MmKlgExtractHdlr(args)
# 调用总结接口
req_id = handler.summarize(params)
# 获取多模态知识提取响应结果
response_list = handle_response(handler, req_id)
for idx, chunk_resp in enumerate(response_list):
# 打印输出每一个视频分块的摘要总结
print(f"chunk {idx}: {chunk_resp.vlm_response}")
# 停止多模态知识提取服务
handler.stop()执行结果:
