



基于香橙派AIpro开发板CosyVoice应用部署
发表于: 2025/08/30
01.引言
CosyVoice是一款基于语音量化编码的语音生成大模型,能够深度融合文本理解和语音生成,实现自然流畅的语音体验。它通过离散化编码和依托大模型技术,能够精准解析并诠释各类文本内容,将其转化为宛如真人般的自然语音。
Wenet是一款面向工业落地应用的语音识别工具包。Wenet网络结构设计借鉴Espnet的joint loss框架,这一框架采取Conformer Encoder + CTC/attention loss, 利用帧级别的CTC loss和label级别attention-based auto-regression loss联合训练整个网络。
通义千问Qwen是阿里云自主研发的大语言模型,Qwen-1.5-0.5B 为其轻量版,拥有5亿参数,具备低成本和高效文本生成能力。适用于文字创作、文本处理、编程辅助、翻译服务和对话模拟等场景。
02.环境准备
本案例我们首先在华为云弹性云服务器(即ECS)购买Tesla T4 、Unbutu22.04环境搭建了cosyvoice服务器,然后在香橙派AIpro开发板部署WeNet和Qwen两个模型并调用搭建好的cosyvoice服务器,能够实现人机智能AI语音聊天。
注意:华为云ECS服务器是收费的,您可以选择合适的设备进行。
2.1 香橙派AIpro开发板环境
硬件
香橙派AIpro 20T(24G)或者香橙派 AIpro 8T(16G) 开发板套件
PC机、网线等
镜像
香橙派官网 Ubuntu 镜像
软件版本
CANN:8.0.0
MindSpore:2.4.10
MindNLP:0.4
网络连接
连接互联网
具体可参考:初识OrangePi Alpro开发板
2.2 GPU服务器环境搭建
2.2.1 GPU服务器推荐配置
Ubuntu:22.04
GPU驱动>=550+
CUDA>= 11.3
GPU显存>=8G
2.2.2 GPU环境搭建
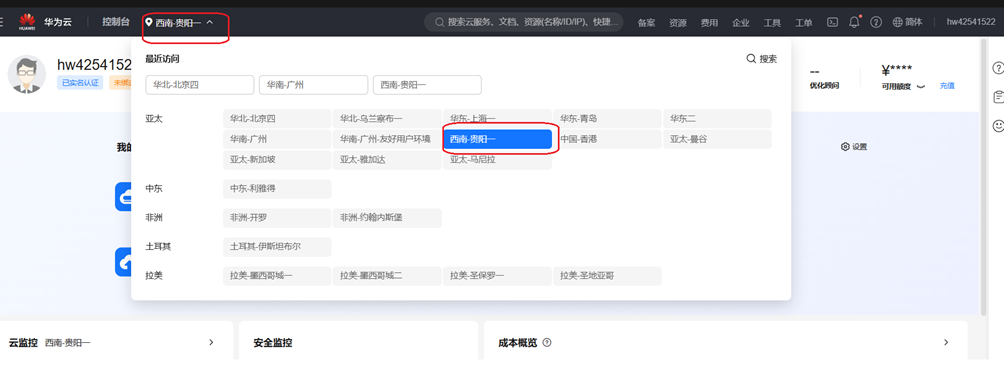
(1)登录华为云ECS
华为云官网ECS服务器控制台 区域选择“贵阳一”
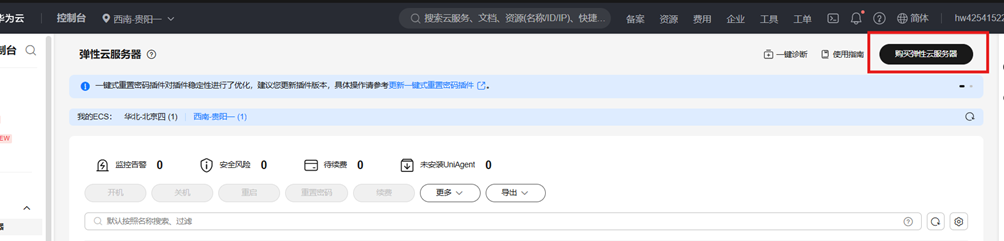
(2)购买GPU服务器
1)点击“购买弹性云服务器”
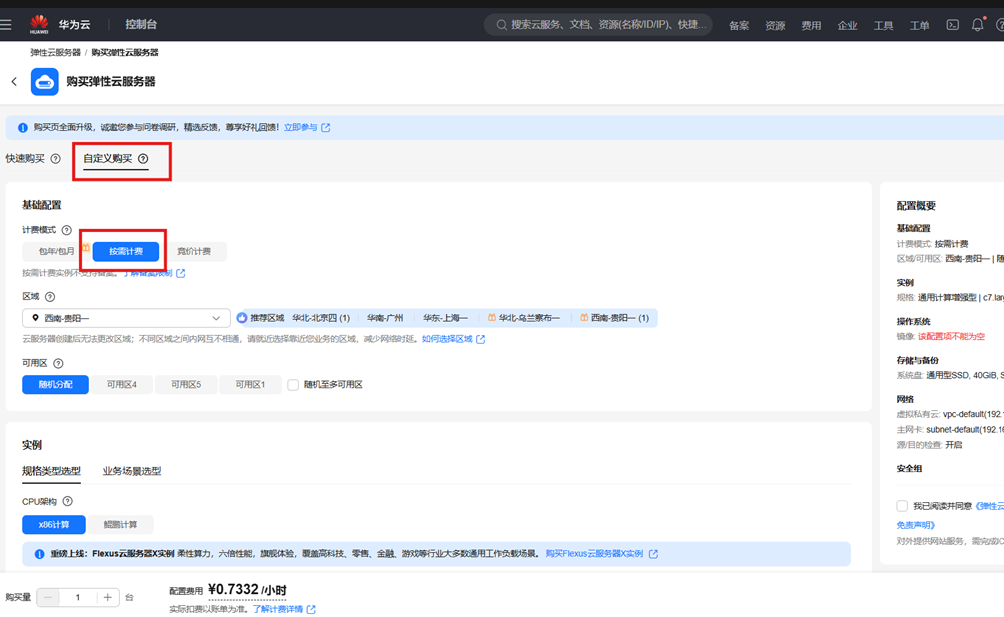
2)选择自定义购买和按需计费
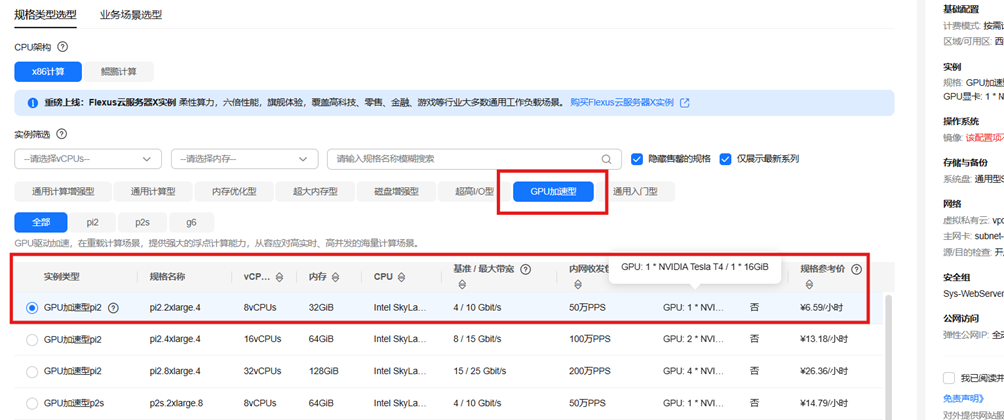
3)选择gpu加速和gpu型号
选择GPU: 1 * NVIDIA Tesla T4 / 1 * 16GIB
4)选择镜像
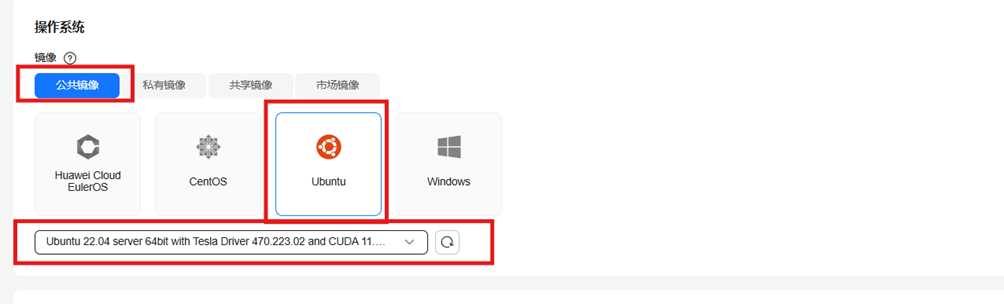
选择镜像为:公共镜像
选择操作系统为:ubuntu
选择镜像版本为:Ubuntu 22.04 server 64bit with Tesla Driver 470.223.02 and CUDA 11.4(40GiB)
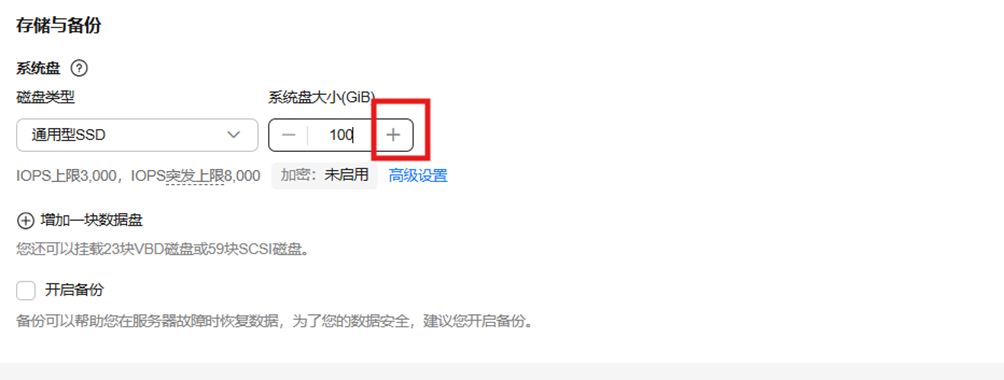
5)选择存储与备份
设置系统盘大小:100
6)安全组
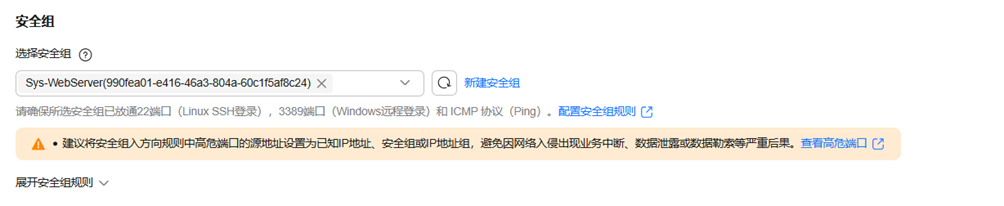
安全组设置示意:
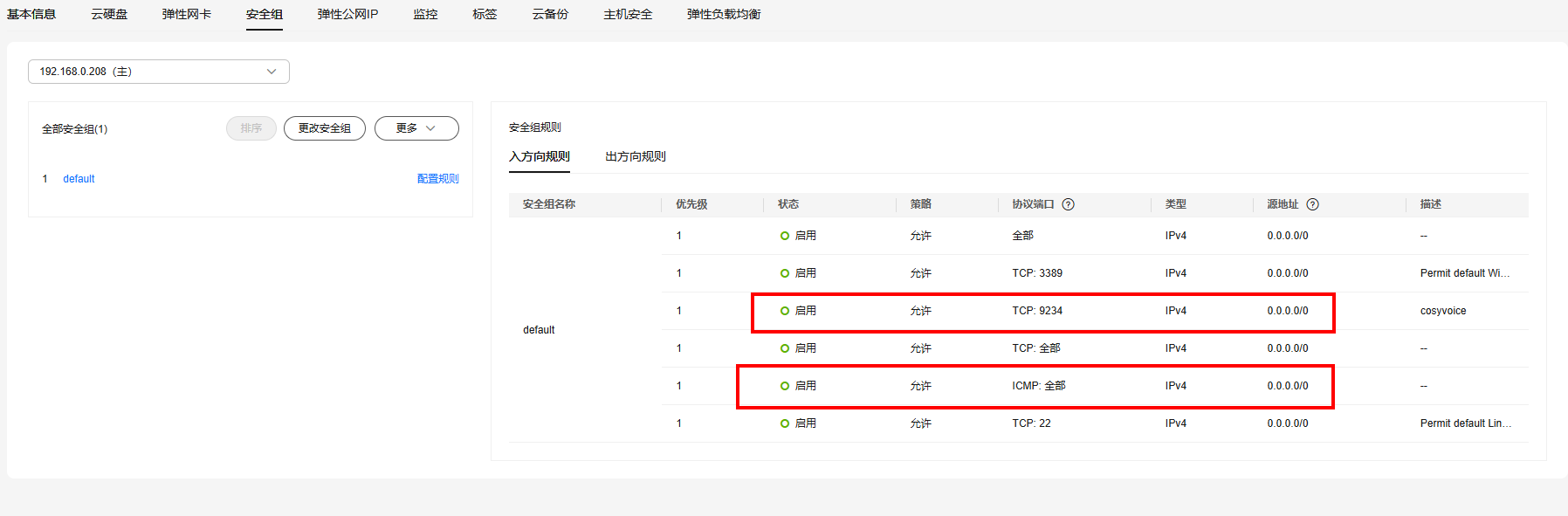
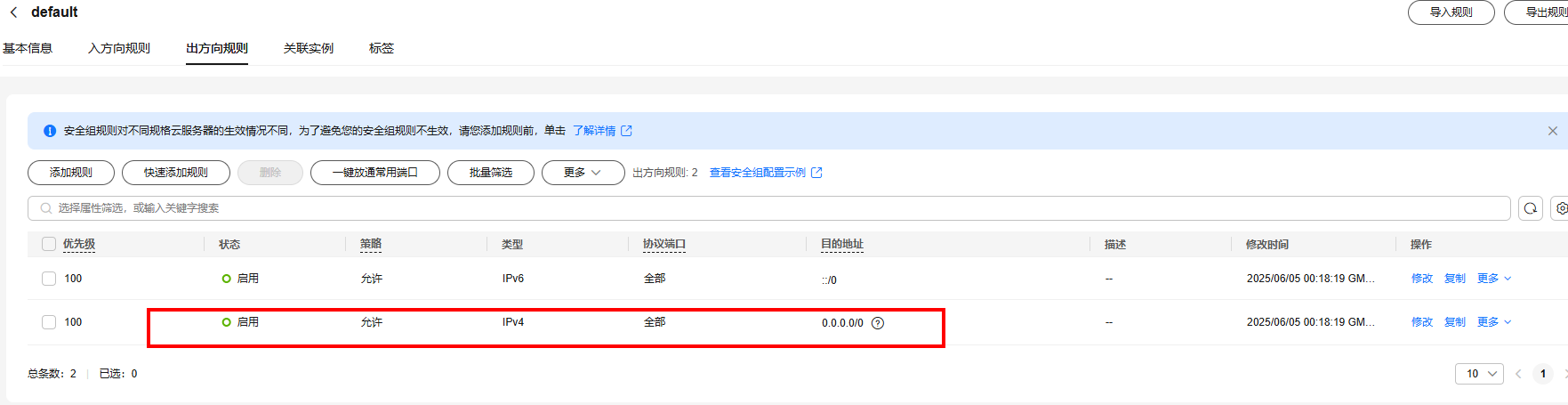
注意:TCP端口号(后面这个端口号多次用到)、ICMP开放
7)公网访问
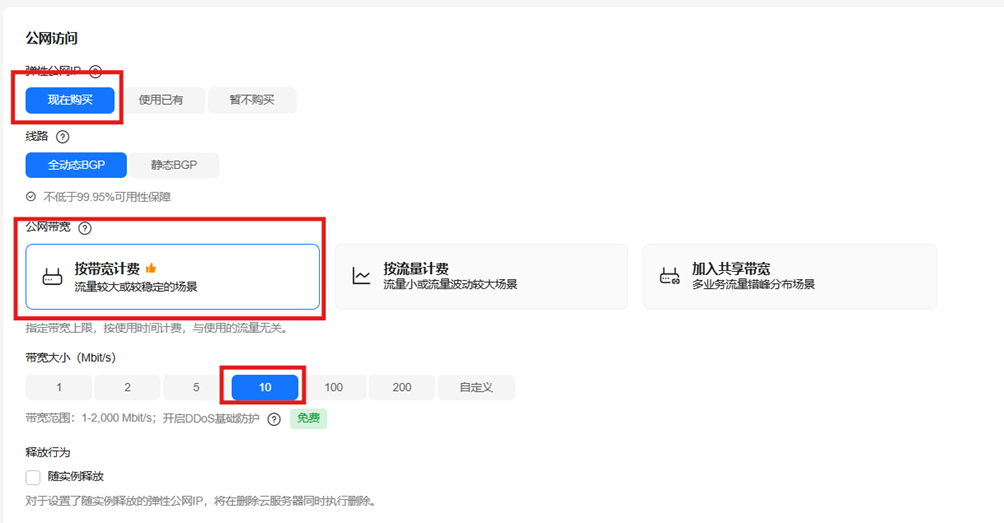
8)云服务器管理
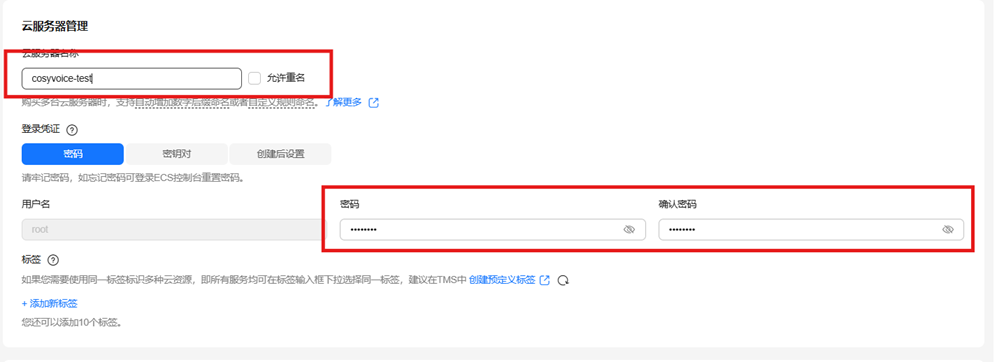
修改云服务器名称,密码为:自行设置(可同香橙派AIpro开发板密码)
9)提交购买
点击“我已阅读并同意"、”立即购买”

10)返回服务器列表
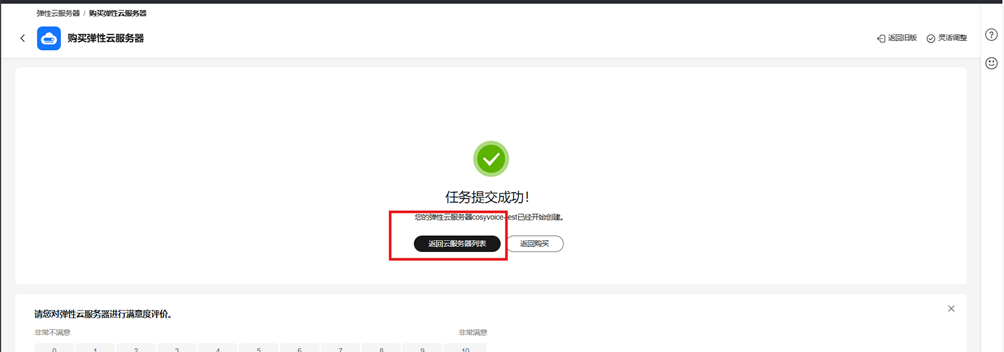
11)查看服务器
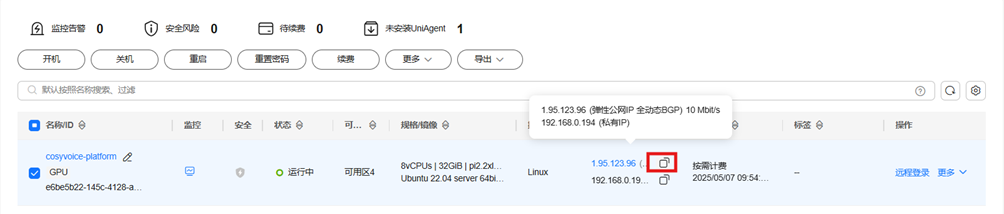
(3)服务器环境搭建
1)使用Mobaxterm进行远程登录
打开Mobaxterm,点击”会话”->”SSH”,粘贴IP
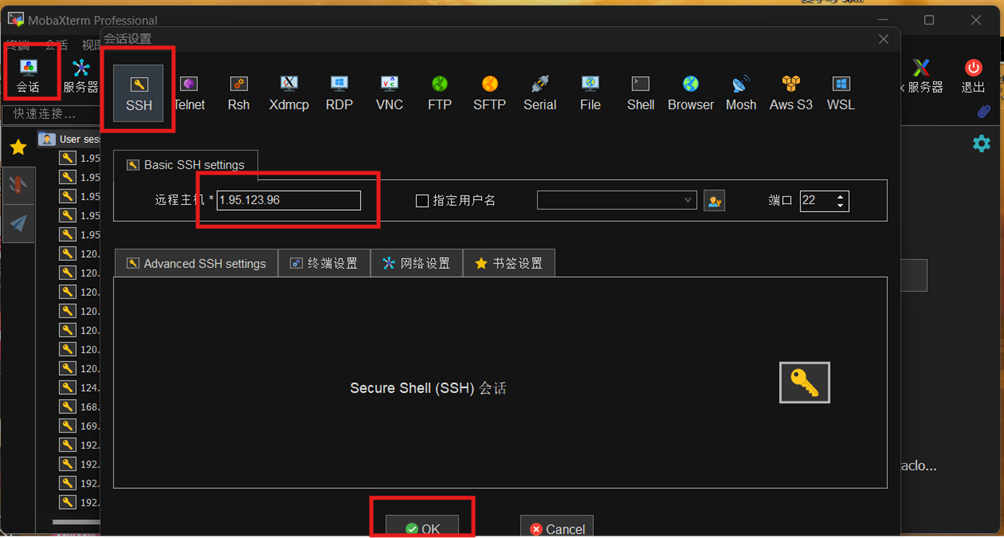
输入用户名:root,密码:Mind@123
登录成功
2)GPU驱动升级
我们本案例使用驱动:NVIDIA-Linux-x86_64-550.163.01.run,可到英伟达官网自行下载
i)apt更新
apt updateii)安装工具
sudo apt install libcurl4-openssl-dev
sudo apt install ffmpeg
sudo apt install git git-lfsPS:建议一行行命令安装,确保所有都安装成功
iii)删除原来的英伟达相关的套件
apt-get purge nvidia-*iv)安装GPU新驱动
chmod +x NVIDIA-Linux-x86_64-550.163.01.run
./NVIDIA-Linux-x86_64-550.163.01.run安装过程出现如下界面根据红框选择:
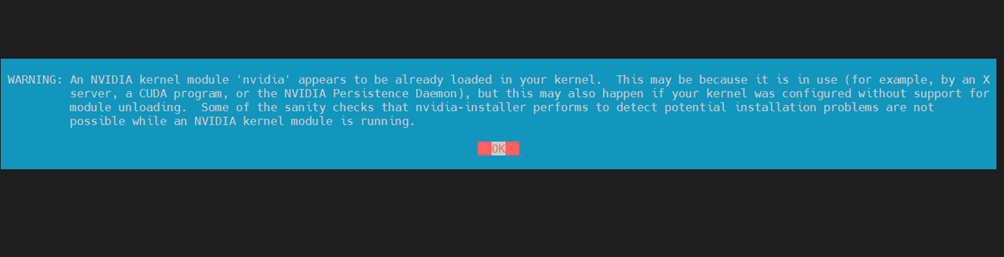
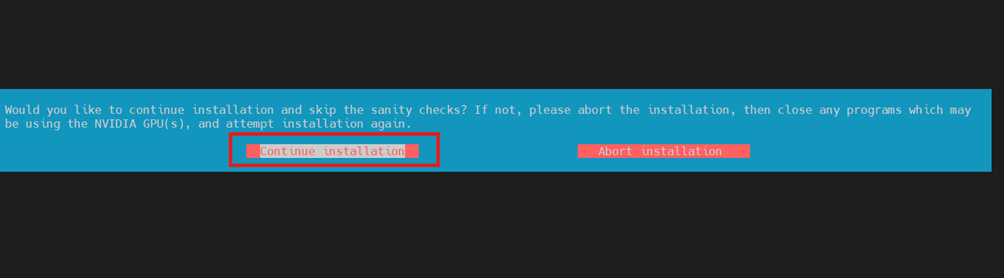



v)服务器重启
驱动与cuda安装完成后 reboot一下
rebootMobaxterm重新登录后,查看驱动版本
nvidia-smi输出如下即可
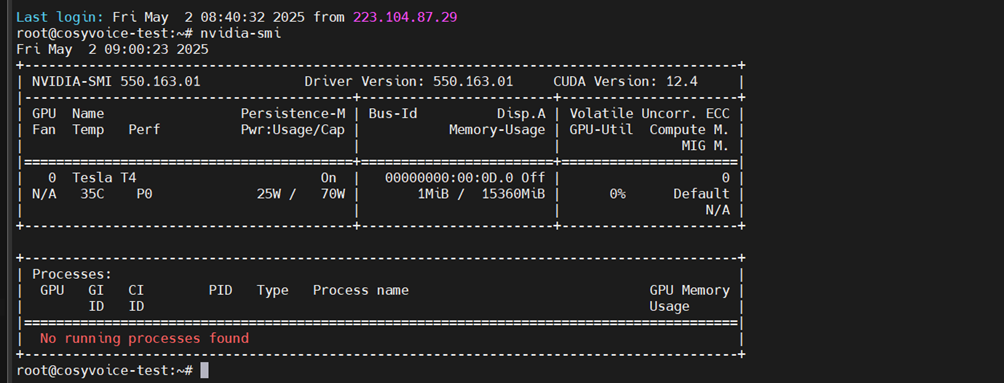
备注:这里cuda并没有升级,服务器自带
vi)cuda版本查询
nvcc -version如果未能正确输出,需要把cuda路径加载到环境变量中去
cuda路径查询
sudo find / -name nvcc 2>/dev/null
# 输出 /usr/local/cuda-11.4/bin/nvcc vim ~/.bashrc
export PATH=/usr/local/cuda-11.4/bin${PATH:+:${PATH}} # 修改cuda对应路径
export LD_LIBRARY_PATH=/usr/local/cuda-11.4/bin/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}#修改cuda对应路径
source ~/.bashrc再次运行以下命令,检查cuda是否OK
nvcc -version03.CosyVoice服务器搭建
(1)安装miniconda
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
source ~/miniconda3/bin/activate
conda init --all(2)创建python虚拟环境
conda create -n cosyvoice python=3.10
conda activate cosyvoice出现如下字样表成功

安装相关python库
conda install -y -c conda-forge pynini==2.1.5(3)下载代码仓
i)下载代码仓库
git clone https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
git submodule update --init --recursive#网络波动时需多次尝试,执行ii)安装requirements的python库
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com备注:这里一定要确保所有库都正确安装,耗时较久,请耐心等待
iii)安装其他库
pip install ffprobe -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install peft -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install WeTextProcessing -i https://pypi.tuna.tsinghua.edu.cn/simple(4) 模型下载
编写模型下载脚本
cd /root/CosyVoice
vim model_download.py把下面代码粘贴进去
# SDK模型下载
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice2-0.5B', local_dir='iic/CosyVoice2-0.5B')
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
snapshot_download('iic/CosyVoice-300M-25Hz', local_dir='pretrained_models/CosyVoice-300M-25Hz')
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')编辑完成后,保存并退出
执行模型下载脚本
python model_download.py等待模型下载成功

(5)音色克隆
1)内置音色模型启动
python webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M-SFT通过 SSH 端口映射本地访问云服务
ssh -L50000:localhost:50000 ecs-user@<云服务器公网IP> # 修改ecs-user为自己用户名,<云服务器公网IP> 公网ip地址启动浏览器 访问 http://<公网ip地址>:50000
如果访问不成功,检查端口是否开放
netstat -tulnp | grep :50000输出如下,OK
tcp 0 0 0.0.0.0:50000 0.0.0.0:* LISTEN 9345/python检查防火墙,确保端口开放
firewall-cmd --list-ports | grep 50000 # 检查是否开放
sudo firewall-cmd --permanent --add-port=50000/tcp # 开放端口
sudo firewall-cmd --reload # 重新加载配置运行后,再次尝试访问http://<公网ip地址>:50000
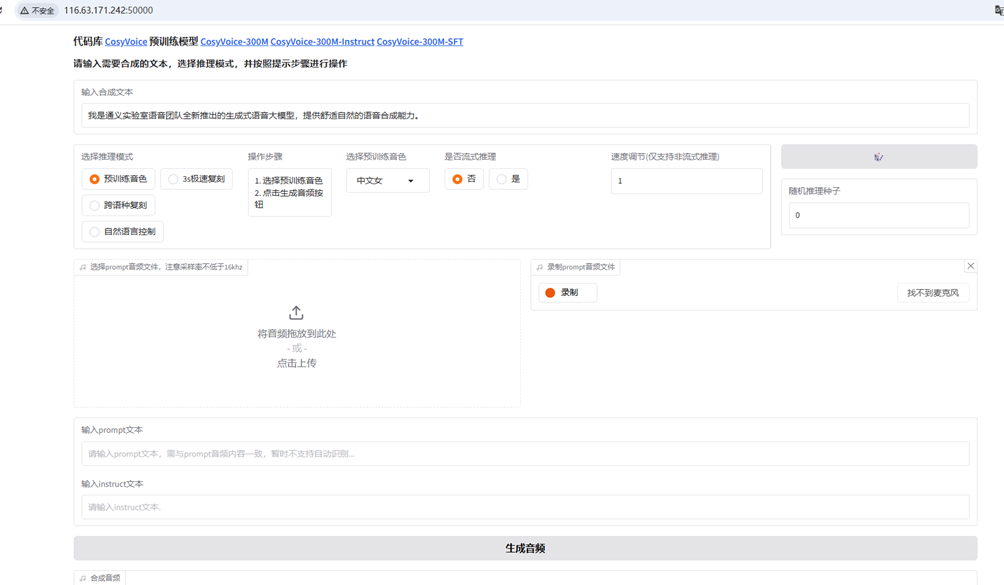
您可以在这里体验cosyvoice的功能。
2)音色克隆(可选)
i)提供一段需要克隆的音色(10s左右)语音文件test.wav
cosyvoice支持个性化定制语音,方法也比较简单,利用电脑自带录音机,录制较短的语音wav格式+对应文本
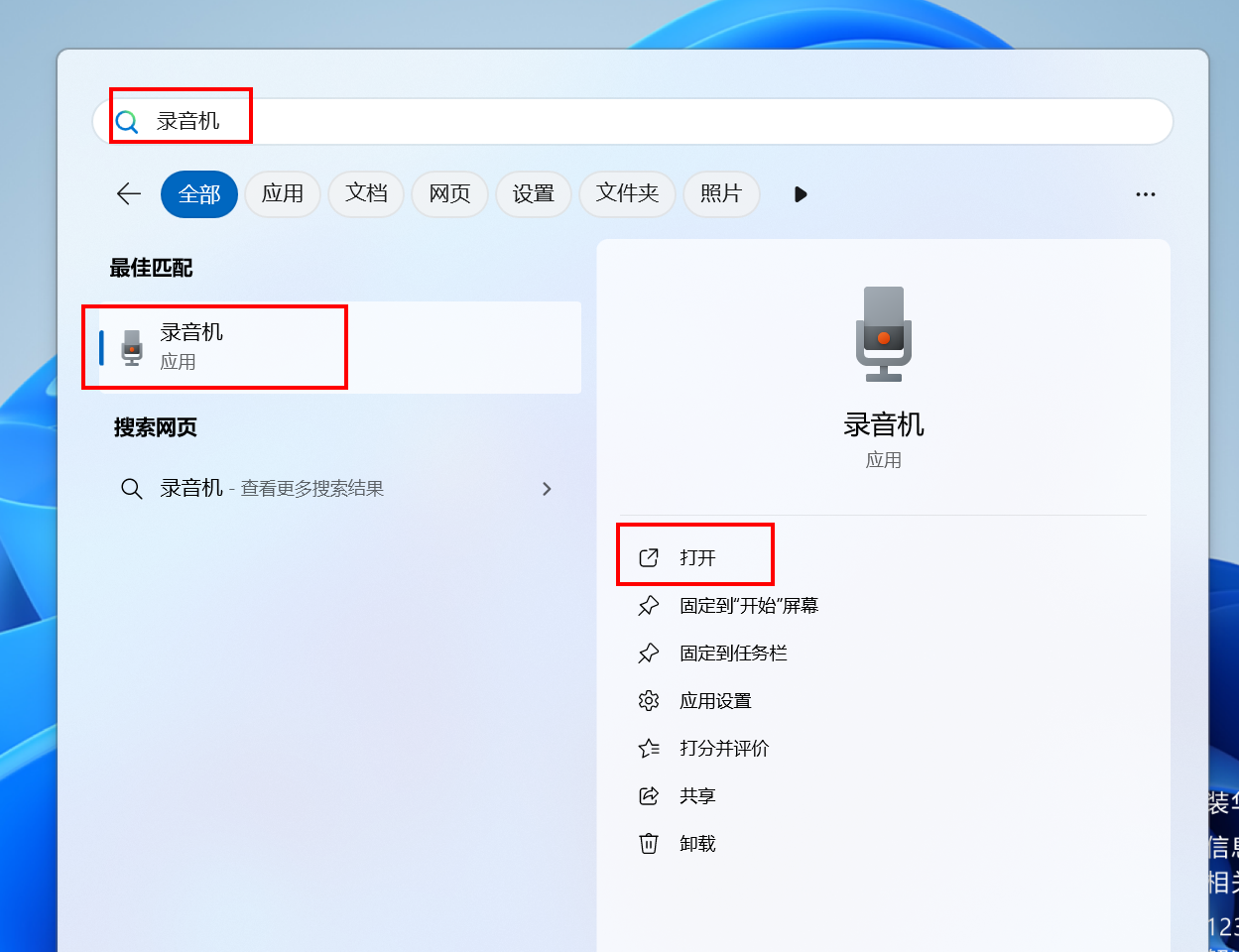
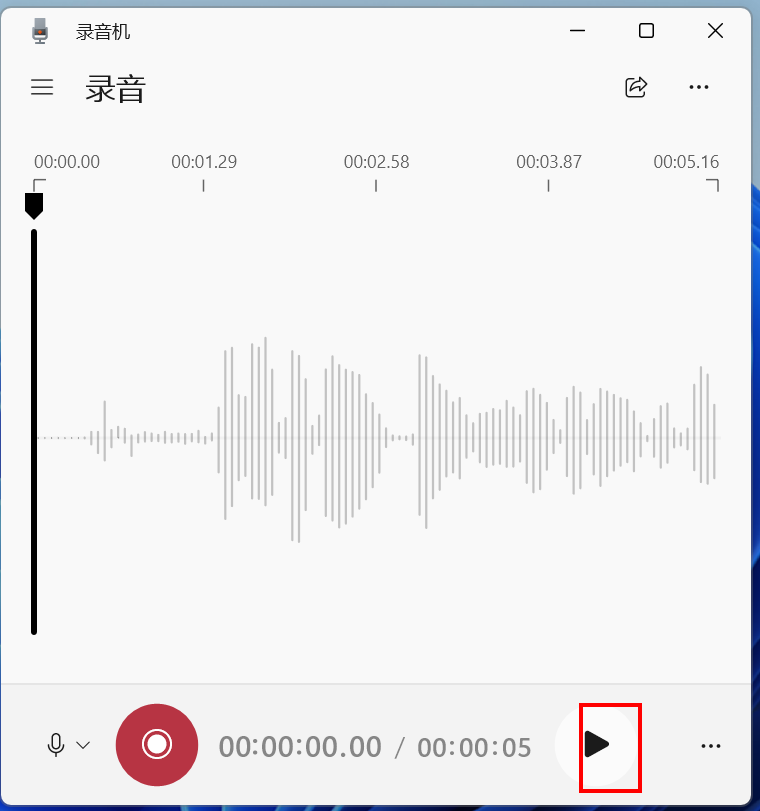
我录制了一段语音,命名: test.wav,文本:"《静夜思》 唐 李白 床前明月光,疑是地上霜,举头望明月,低头思故乡。"
ii)编写wav2pt.py代码生成音色特征spk2info.pt文件
#wav2pt.py代码参考如下
import os
import sys
import torch
import torchaudio
from cosyvoice.cli.cosyvoice import CosyVoice2
from cosyvoice.utils.file_utils import load_wav
# 将第三方库Matcha-TTS的路径添加到系统路径中
sys.path.append('third_party/Matcha-TTS')
# 初始化模型
cosyvoice = CosyVoice2('iic/CosyVoice2-0.5B', load_jit=False, load_trt=False, fp16=False)
# 加载参考音频
speaker = 'test'# 改成自己的文件名,例如test
# 加载16kHz的提示语音
prompt_speech_16k = load_wav(f'./{speaker}.wav', 16000)
spk2info_path = f'./spk2info.pt'
# 如果说话人信息文件存在,则加载
if os.path.exists(spk2info_path):
spk2info = torch.load(
spk2info_path, map_location=cosyvoice.frontend.device)
else:
spk2info = {}
# 想要重新生成当前说话人音频特征的取消以下注释
#if speaker in spk2info:
# del spk2info[speaker]
if speaker not in spk2info:
# 获取音色embedding
embedding = cosyvoice.frontend._extract_spk_embedding(prompt_speech_16k)
# 获取语音特征
prompt_speech_resample = torchaudio.transforms.Resample(orig_freq=16000, new_freq=cosyvoice.sample_rate)(prompt_speech_16k)
speech_feat, speech_feat_len = cosyvoice.frontend._extract_speech_feat(prompt_speech_resample)
# 获取语音token
speech_token, speech_token_len = cosyvoice.frontend._extract_speech_token(prompt_speech_16k)
# 将音色embedding、语音特征和语音token保存到字典中
spk2info[speaker] = {'embedding': embedding,
'speech_feat': speech_feat, 'speech_token': speech_token}
# 保存音色embedding
torch.save(spk2info, spk2info_path)使用音色进行语音合成
iii)语音合成测试
编写pt2wav.py
#pt2wav.py
#-*- coding:utf-8 -*-
import time
import torch
import torchaudio
import csv
from glob import glob
from tqdm import tqdm
import sys # 添加sys导入
import os # 添加os导入
import hashlib # 用于生成文件名哈希
# 将第三方库Matcha-TTS的路径添加到系统路径中
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice2
from cosyvoice.utils.file_utils import load_wav
# 初始化CosyVoice2模型
#cosyvoice = CosyVoice2() # 请根据CosyVoice2的实际初始化方式调整
cosyvoice = CosyVoice2('iic/CosyVoice2-0.5B',
load_jit=False, load_trt=False, fp16=False)
# 设置说话人名称
speaker = 'test'
# 设置说话人信息文件的路径
spk2info_path = f'./spk2info.pt'
# 如果说话人信息文件存在,则加载
if os.path.exists(spk2info_path):
spk2info = torch.load(
spk2info_path, map_location=cosyvoice.frontend.device)
else:
spk2info = {}
# 设置提示文本
prompt_text = "《静夜思》 唐 李白 床前明月光,疑是地上霜,举头望明月,低头思故乡。"
# 设置要合成的文本列表
tts_text_list = ["收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。",
"人类不断挑战极限,在这一过程中超越自我,攀登新的高度。登山作为一项古老的极限运动,自古以来就吸引了无数冒险者,即使在现代,依然是许多人的热爱。"]
# 定义一个文本到语音的函数,参数包括文本内容、是否流式处理、语速和是否使用文本前端处理
def tts_sft(tts_text, speaker_info: dict, stream=False, speed=1.0, text_frontend=True):
'''
参数:
tts_text:要合成的文本
speaker_info:说话人音频特征
stream:是否流式处理
speed:语速
text_frontend:是否使用文本前端处理
返回值:
合成后的完整音频(所有句子拼接)
'''
full_audio = None
sentences = cosyvoice.frontend.text_normalize(tts_text, split=True, text_frontend=text_frontend)
for sentence in tqdm(sentences, desc="Processing sentences"):
# 提取文本的token和长度
tts_text_token, tts_text_token_len = cosyvoice.frontend._extract_text_token(sentence)
# 提取提示文本的token和长度
prompt_text_token, prompt_text_token_len = cosyvoice.frontend._extract_text_token(prompt_text)
# 获取说话人的语音token长度
speech_token_len = torch.tensor([speaker_info['speech_token'].shape[1]],
dtype=torch.int32).to(cosyvoice.frontend.device)
# 获取说话人的语音特征长度
speech_feat_len = torch.tensor([speaker_info['speech_feat'].shape[1]],
dtype=torch.int32).to(cosyvoice.frontend.device)
model_input = {
'text': tts_text_token,
'text_len': tts_text_token_len,
'prompt_text': prompt_text_token,
'prompt_text_len': prompt_text_token_len,
'llm_prompt_speech_token': speaker_info['speech_token'],
'llm_prompt_speech_token_len': speech_token_len,
'flow_prompt_speech_token': speaker_info['speech_token'],
'flow_prompt_speech_token_len': speech_token_len,
'prompt_speech_feat': speaker_info['speech_feat'],
'prompt_speech_feat_len': speech_feat_len,
'llm_embedding': speaker_info['embedding'],
'flow_embedding': speaker_info['embedding']
}
# 处理当前句子
for model_output in cosyvoice.model.tts(**model_input, stream=stream, speed=speed):
current_audio = model_output['tts_speech']
# 拼接音频
if full_audio is None:
full_audio = current_audio
else:
full_audio = torch.cat([full_audio, current_audio], dim=1)
return {'tts_speech': full_audio} if full_audio is not None else None
# 确保outputs目录存在
os.makedirs('outputs1', exist_ok=True)
# 遍历文本列表
for index, text in enumerate(tts_text_list): # 修复:移除函数调用括号,使用enumerate获取索引
print(f"Processing text {index}: {text[:20]}...") # 打印进度
start = time.time()
# 获取完整音频
result = tts_sft(text, speaker_info=spk2info[speaker], stream=False, speed=1.0, text_frontend=True)
运行代码pt2wav.py脚本
生成与提供音色一致的语音文件,打开wav进行试听。
3)cosvoice应用场景--理论课程视频生成
i)下载示例
cd /root/CosyVoice
wget https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com/cosyvoice/CosyVoice-set.tgz ###
tar -xzvf CosyVoice-set.tgz
#文件中包含不同音色的wav及spk2info.pt、要生成的逐字稿文本csv、语音生成脚本A2-batch-voice.py等iI)拷贝spk2info.pt到CosyVoice2-0.5B目录下
cp input/spk2info.pt iic/CosyVoice2-0.5B/iii)修改A2-batch-voice.py
vim A2-batch-voice.py修改内容如下:
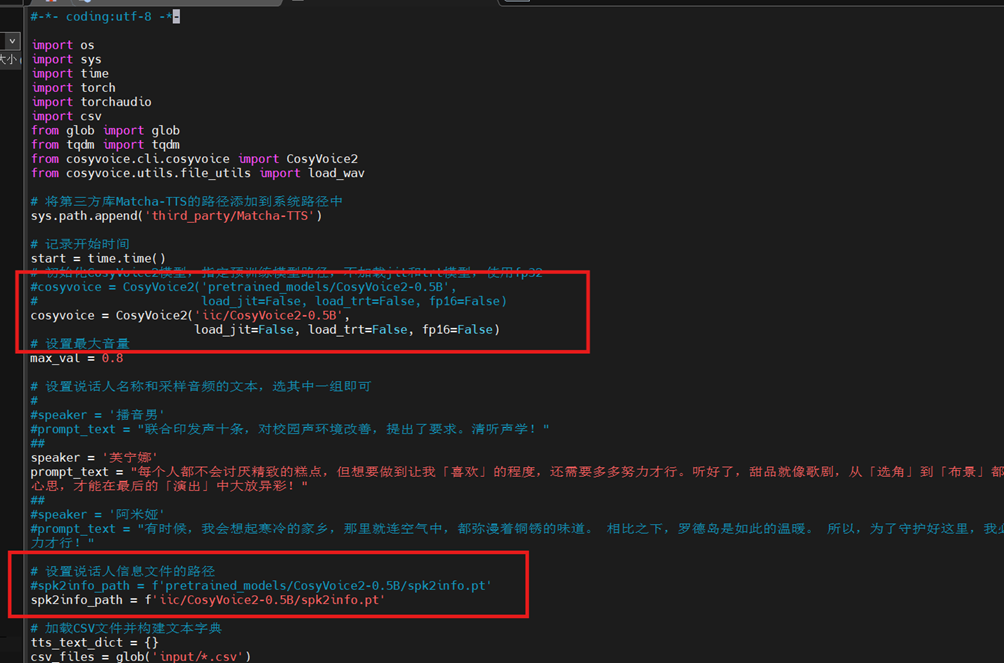
修改完成后,保存并退出
iv)运行脚本
python A2-batch-voice.py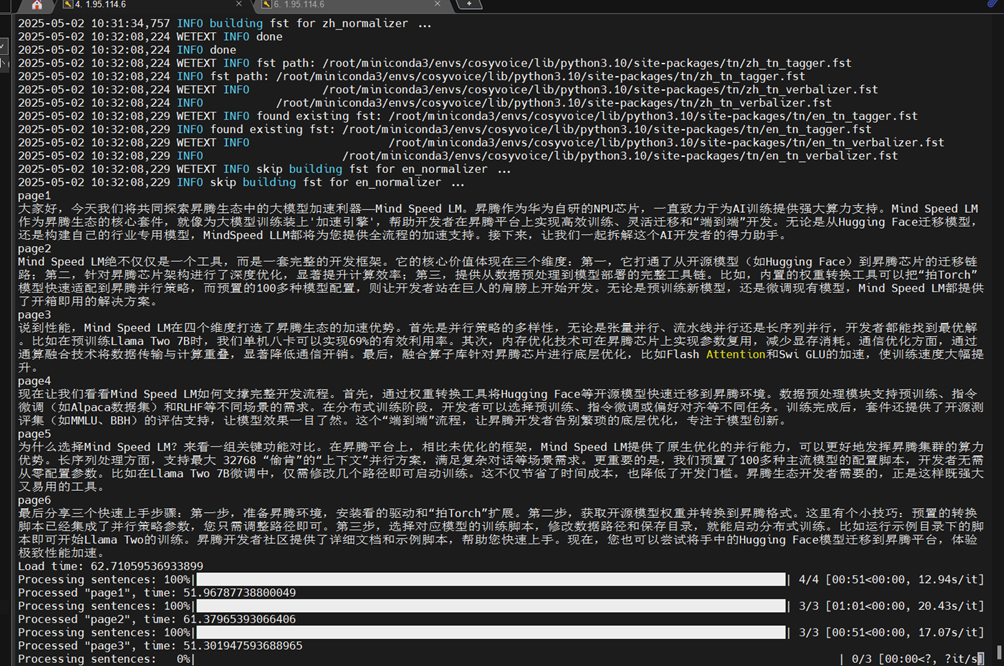
查看生成语音文件
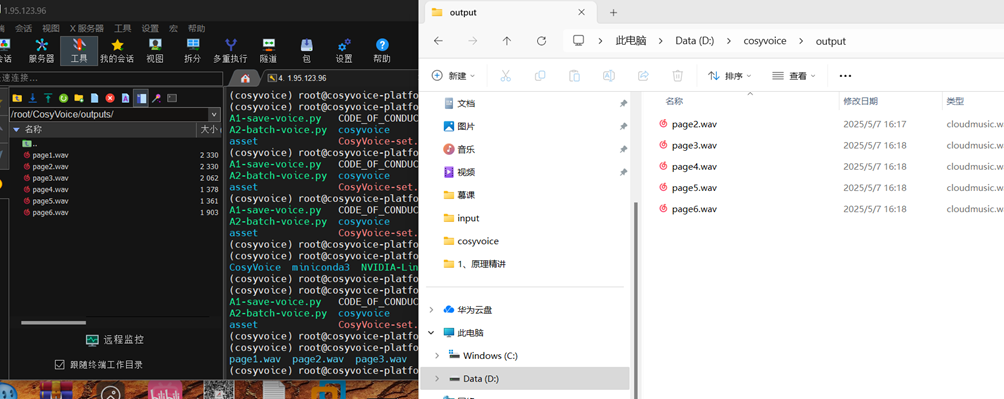
ls
v)wav文件下载到本地PC机
vi)打开对应的ppt
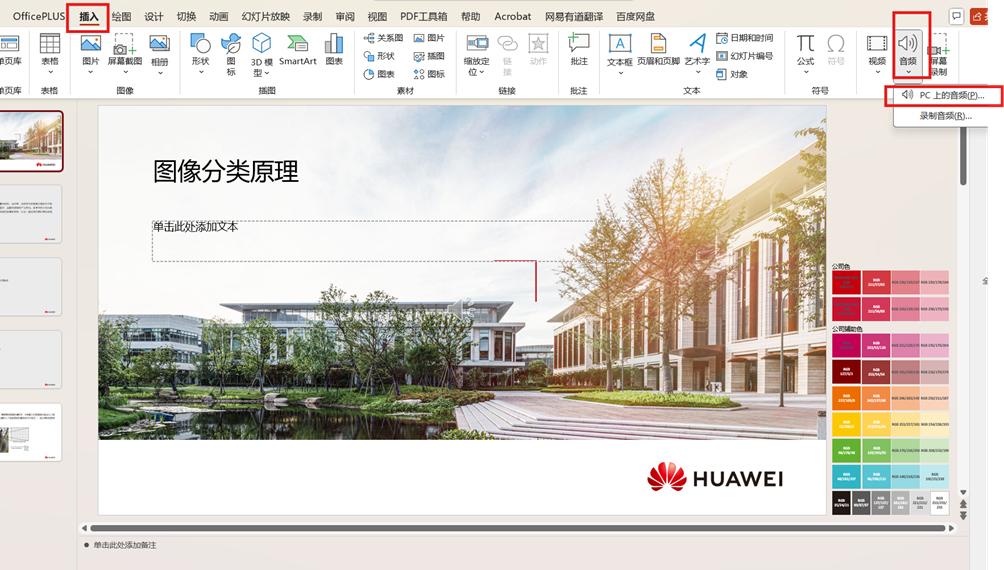
vii)把推理出的wav插入到对应的ppt上
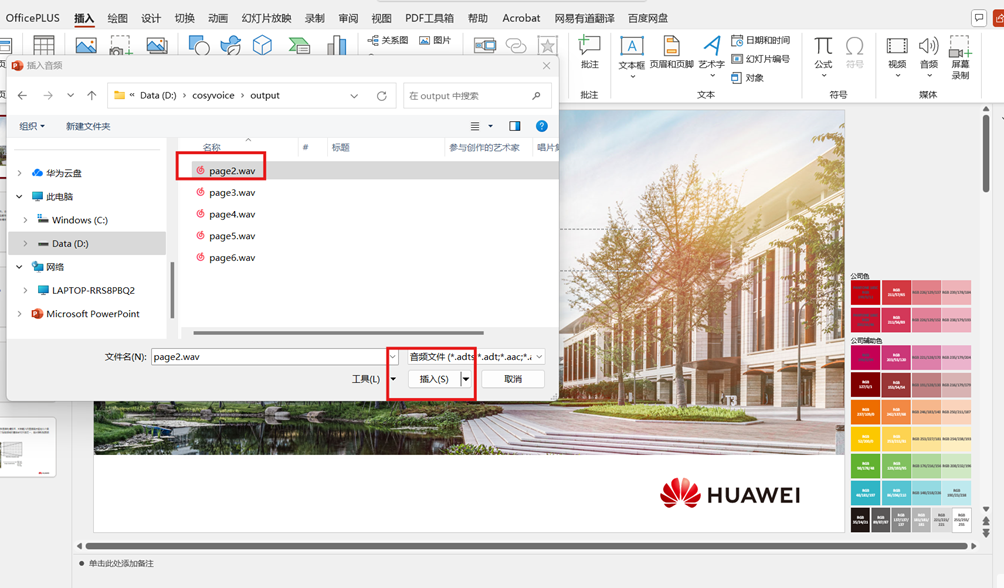
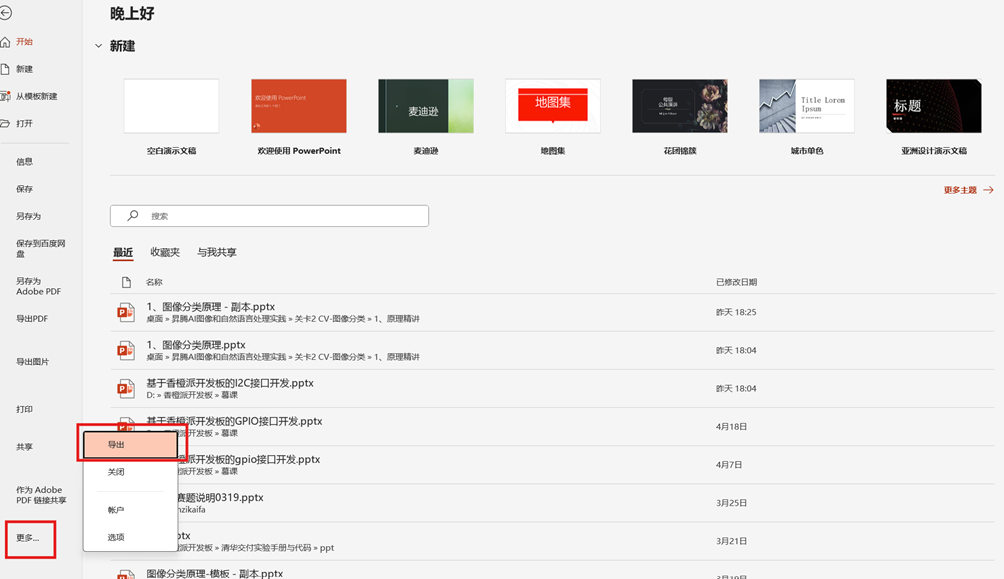
viii)导出视频
点击“文件”->“更多”->“导出”
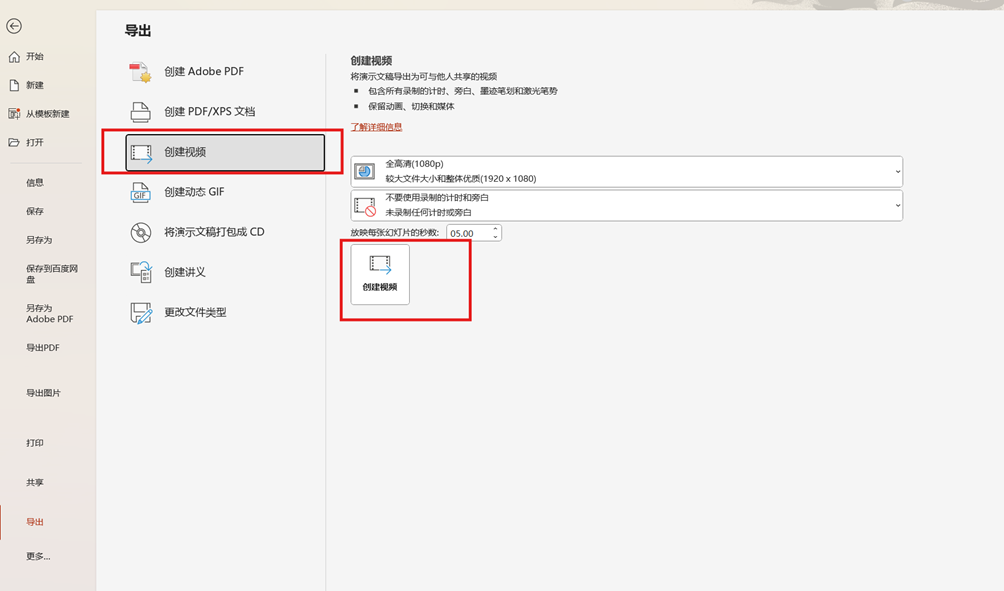
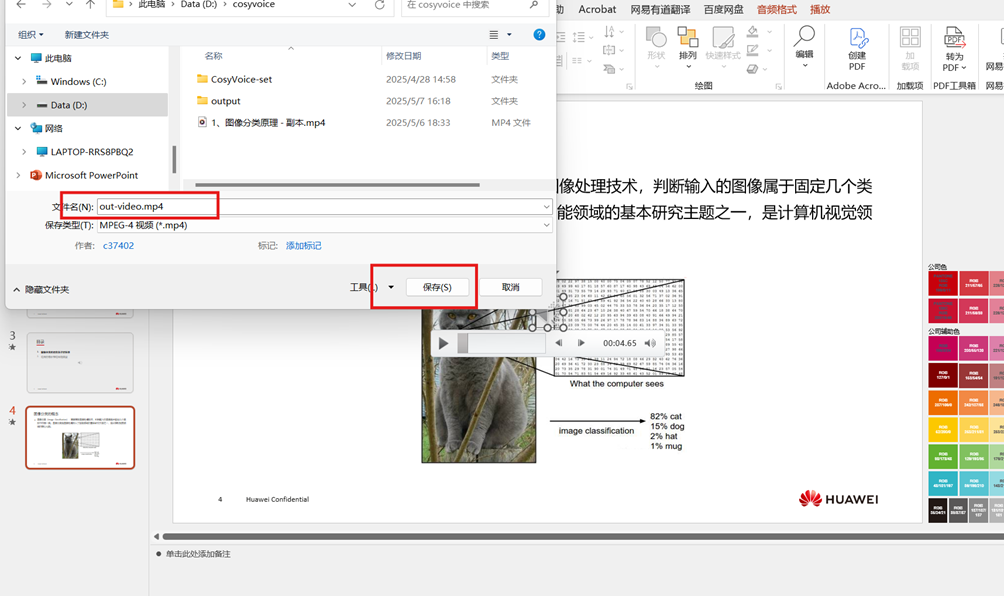
至此,cosyvoice应用已成功搭建,后续我们将在开发板上使用该应用进行语音聊天。
04.香橙派AIpro开发板搭建智能AI语音助手
(1)香橙派AIpro开发板上WeNet模型准备
1)香橙派AIpro开发板登录
用户名:HwHiAiUser、密码:Mind@123
2)下载代码包
mkdir cosyvoice
cd cosyvoice
wget https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com/cosyvoice/Voice.zip
unzip Voice.zip
cd Voice/ModelConvert下载语音识别WeNet的onnx文件
wget https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com/cosyvoice/offline_encoder_sim.onnxonnx模型转换为om
atc --model=offline_encoder_sim.onnx --framework=5 --output=offline_encoder --input_format=ND --input_shape="speech:1,1478,80;speech_lengths:1" --log=error --soc_version=Ascend310B4等待片刻,输出,表转换模型成功。

将om模型拷贝到wenet文件夹下
cp offline_encoder.om ../v2/wenet/(2)Qwen大模型部署
cd /Voice/v2/qwen
vim qwen1.5-0.5b-terminal.py修改第5行和第6行为:
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat", ms_dtype=mindspore.float16)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-0.5B-Chat", ms_dtype=mindspore.float16)
#修改后保持并退出运行脚本
python qwen1.5-0.5b-terminal.py代码运行,会下载qwen模型如下:
备注:开发板一定要连接互联网
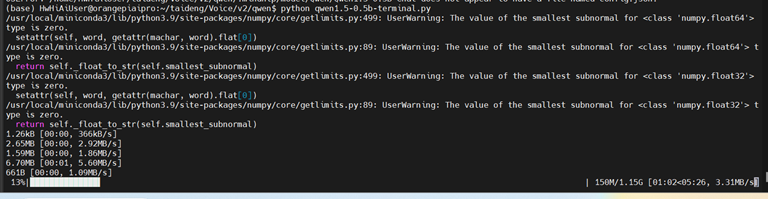
下载完成后,加载完千问模型便可以向模型提问
输入:你好啊,你是谁?
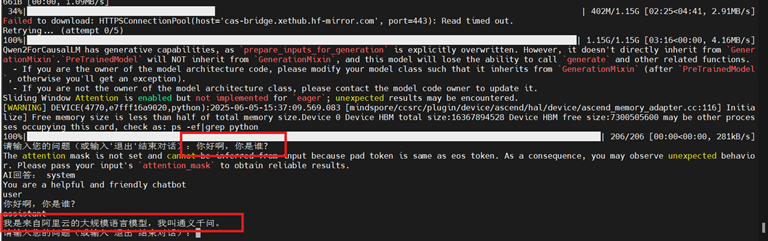
输入:退出,退出qwen推理
检查qwen模型下载路径
cd /home/HwHiAiUser/cosyvoice/Voice/v2/qwen
ll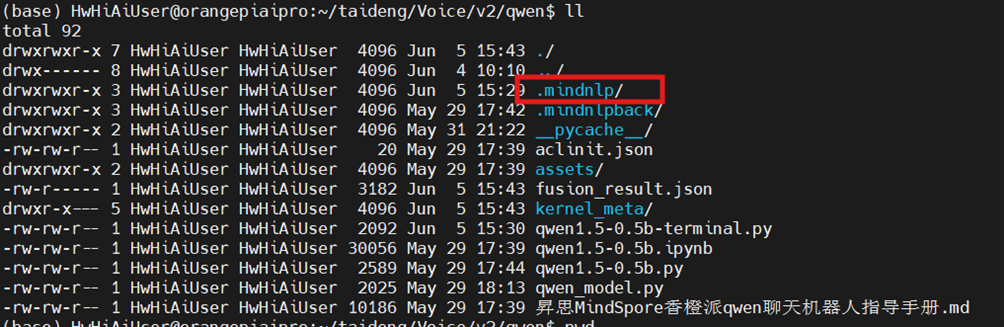
vim qwen1.5-0.5b-terminal.py修改第5与第6行,修改模型加载路径
tokenizer = AutoTokenizer.from_pretrained("/home/HwHiAiUser/taideng/Voice/v2/qwen/.mindnlp/model/Qwen/Qwen1.5-0.5B-Chat", ms_dtype=mindspore.float16)
model = AutoModelForCausalLM.from_pretrained("/home/HwHiAiUser/taideng/Voice/v2/qwen/.mindnlp/model/Qwen/Qwen1.5-0.5B-Chat", ms_dtype=mindspore.float16)修改后,保存并退出,模型加载来源于本地,避免重复下载。
(3)CosyVoice服务器的Web服务搭建
1)搭建cosyvoice服务器的Web服务
i)下载api.py到cosyvoice项目目录下
浏览器打开网址:https://github.com/jianchang512/cosyvoice-api/tree/main
ii).把api.py放到CosyVoice的目录下

iii). 修改api.py
修改178,186两行代码为:
tts_model=CosyVoice2('pretrained_models/CosyVoice2-0.5B', load_jit=False, load_trt=False, fp16=False)iv).测试cosyvoice服务器端口
conda activate cosyvoice
pip install flask
cd /root/CosyVoice
python api.py
运行成功后,会自动下载CosyVoice2-0.5B与CosyVoice-300M-SFT,服务器开启,端口可访问。
备注:香橙派AIpro开发板调用该web服务,一定确保api.py持续运行
如不想重复下载,可终止api.py运行,把下面两行代码注释掉,再次运行api.py
#snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')
#snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')(2)香橙派AIpro开发板调用cosyvoice的Web服务器
HwHiAiUser用户登录香橙派AIpro开发板,测试cosyvocie服务器可用性
注意:香橙派AIpro开发板一定要联网
1.测试cosyvoice服务器是否可用
ping 公网ip地址 #测试公网ip是否OK2.测试服务器端口是否可用
telnet 公网ip <端口> # 测试端口9234是否OK输出下面信息,服务器端口可用

如不可用,需要检测ECS安全组端口是否开放(检查ECS服务器安全组设置)、防火墙设置是否正确(防火墙设置可参考前面)
3.编写test.py
#python test.py
import requests
my_data = {}
my_data["text"] = "只因你太美 baby 只因你太美 baby 只因你实在是太美 baby 只因你太美 baby 迎面走来的你让我如此蠢蠢欲动 这种感觉我从未有 Cause I got a crush on you who you 你是我的我是你的谁 再多一眼看一眼就会爆炸 再近一点靠近点快被融化"
my_data["reference_audio"] = "test.wav"
my_data["reference_text"] = "《静夜思》 唐 李白 床前明月光,疑是地上霜,举头望明月,低头思故乡。"
print(my_data)
response = requests.post('http://<公网IP>:<端口>/clone_eq', data=my_data, timeout=3600) #这里端口用的是9234
with open('output_clone_eq.wav', 'wb') as f:
f.write(response.content)
运行test.py脚本,在香橙派AIpro开发板,输出output_clone_eq.wav,同时cosyvoice服务器会用定制的语音样板进行播放。
3).使用Web服务
cd /home/HwHiAiUser/cosyvoice/Voice/v2
vi main.py修改内容如下:
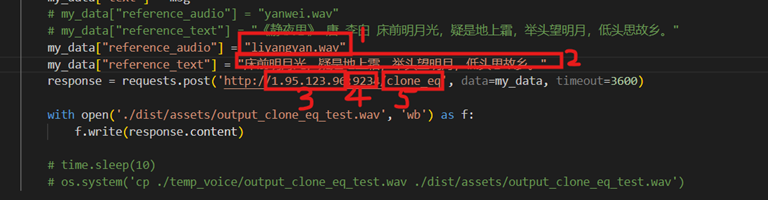
参数解释:
- cosyvoice服务器上需要混合语音合成的wav文件
- 混合语音合成的wav文件对应的朗读文本
- cosyvoice服务器的公网ip
- cosyvoice上api.py的端口号
- 需要语音合成功能的写”clone_eq”,也可以使用默认音色的写”tts”
修改完成后,保持并退出。
python main.py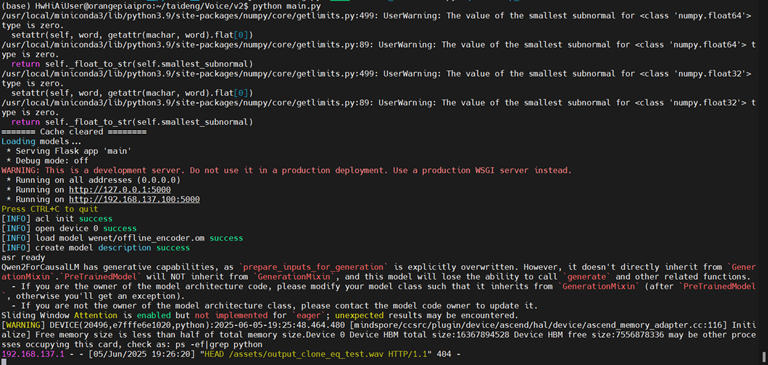
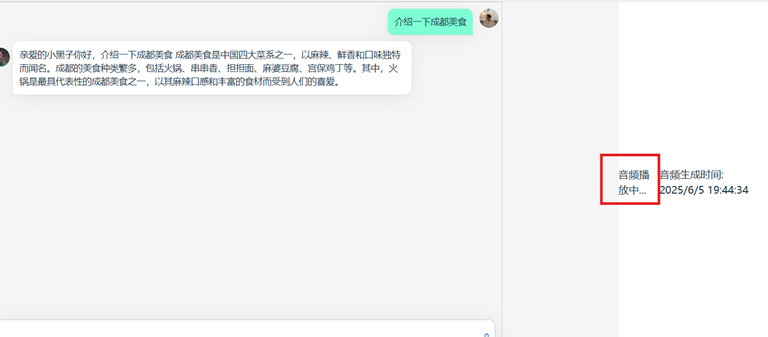
打开chrome浏览器,输入“chrome://flags/#unsafely-treat-insecure-origin-as-secure”,将 http://192.168.137.100:5000/ 复制输入到下面图中文本框中,将选项配置为“Enabled”,单击“Relaunch”按钮重启浏览器。
在重启后的浏览器地址栏输入http://192.168.137.100:5000/ ,按下键盘“Enter”键,进入语音交互界面。
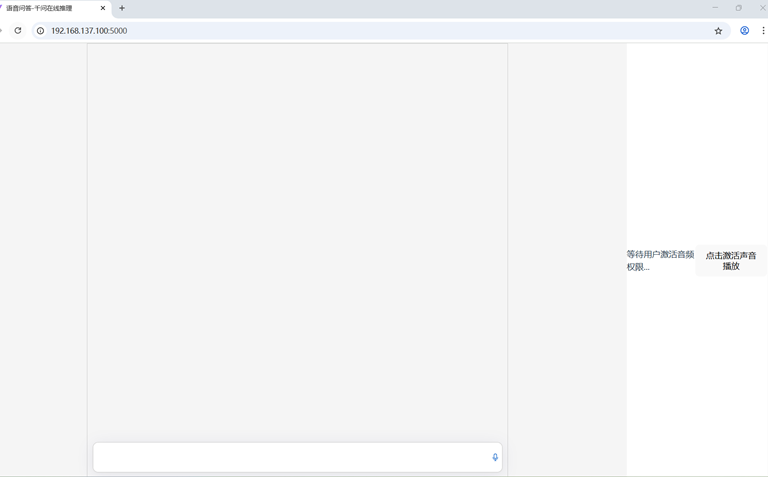
单击录音按钮开始录音,语音输入指令,再次单击按钮结束录音
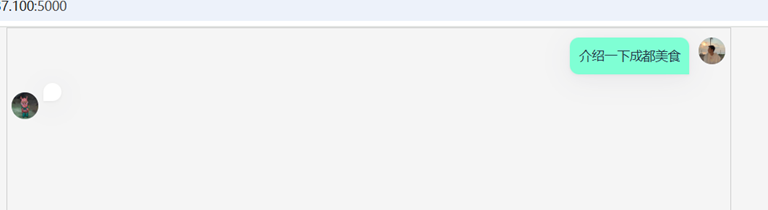
语音提问“介绍一下成都美食“
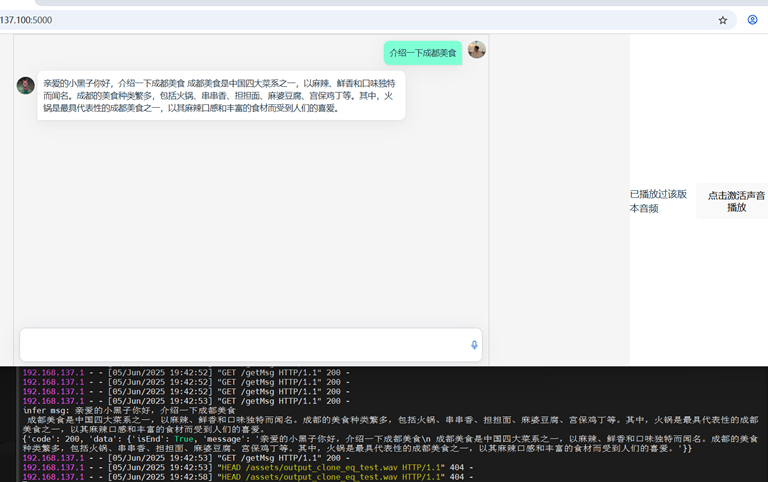
片刻后,qwen模型推理介绍:
CosyVoice服务器推理运行截图如下
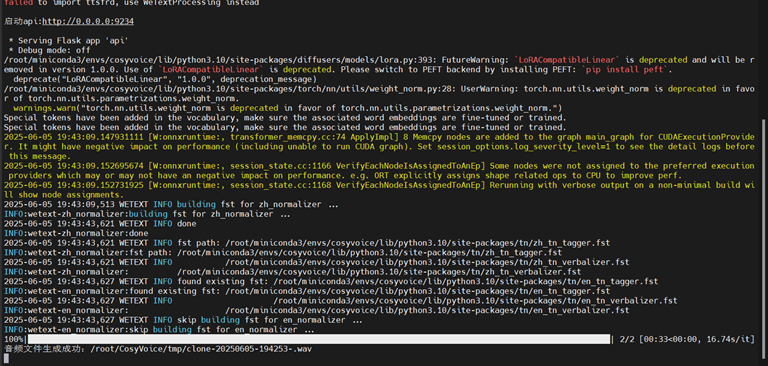
等待运行成功后,可以播放
文件存放位置:/home/HwHiAiUser/cosyvoice/Voice/v2/dist/assets/output_clone_eq_test.wav
