



基于昇腾推理微服务快速构建 Coze Studio AI智能体
发表于: 2025/08/11
昇腾推理微服务(Mind Inference Service, MIS)
昇腾推理微服务MIS: 2步部署高性能模型服务,AI应用小时级构建
MIS提供广泛的模型支持,无需复杂依赖安装,即可在数据中心、云端及边缘设备上实现快速部署。针对昇腾硬件进行深度性能优化,省去繁琐的调优过程。提供行业标准接口,便于集成到企业业务系统中,助力业务高效运行。
- 核心特性
- 统一推理框架:集成多种引擎(vLLM,MindIE,TEI,CLIP),对外提供统一框架
- 支持模型广泛:支持主流文本大语言(LLM)、多模态(VLM)、向量化(Embedding/Reranker/CLIP)等不同种类模型
- 内置性能优化:内置多种昇腾亲和的性能优化配置,支持配置一键切换
- 易用性部署:镜像部署,无需繁琐配置,可在数据中心、云端快速部署
- 标准化接口:提供符合行业标准的RESTful API接口,支持与企业业务系统无缝集成
Coze Studio
Coze Studio (以下简称coze) 是字节跳动推出的AI应用开发平台,支持快速构建和部署基于大语言模型的智能应用。平台提供了丰富的工具和插件,让开发者能够无代码或低代码地创建AI Bot。
- 核心特性
- 可视化编排:支持通过DAG工作流实现多模型协同
- 推理插件化扩展:提供预集成工具链实现知识库管理、API调用等扩展功能
- 低代码开发:通过配置式开发降低智能体构建门槛
快速入门 (以昇腾310系列硬件为例)
1. 下载昇腾推理微服务MIS
推理微服务是构建AI智能体的关键组件,从昇腾社区镜像仓库下载相应的推理微服务镜像,即可快速部署推理微服务。
- 大语言模型推理微服务镜像 [deepseek-r1-distill-qwen-7b] (Atlas 800I A2与310I Pro/Duo采用相同镜像)
- 向量化模型推理微服务镜像 [bge-large-zh-v1.5]
2. 下载coze
访问coze代码仓下载压缩包 或者通过 git 下载项目
git clone https://github.com/coze-dev/coze-studio.git3. 容器化部署推理微服务
推理微服务允许用户选择vLLM与MindIE推理引擎并根据性能需求(高吞吐、低时延或默认)配置推理引擎。更多详情请参考各镜像模型的镜像概述。
3.1 启动LLM推理微服务
# 设置本地缓存路径 (请根据需求自行替换路径,微服务会从LOCAL_CACHE_PATH路径下的 MindSDK/DeepSeek-R1-Distill-Qwen-7B 进行权重的加载,请确保模型放置路径正确)
export LOCAL_CACHE_PATH=/data/models
# 设置容器名称
export CONTAINER_NAME=deepseek-r1-distill-qwen-7b
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/deepseek-r1-distill-qwen-7b:7.1.T9-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=0,1 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
-p 8000:8000 \
--shm-size 1gb \
$IMG_NAME
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}3.2 启动EMB推理微服务
export LOCAL_CACHE_PATH=/home/models
# 设置容器名称
export CONTAINER_NAME=bge-large-zh-v1.5
# 选择镜像
export IMG_NAME=昇腾社区下载镜像名(可由docker images查看)
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
-p 9000:9000 \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=2 \
-e MAX_BATCH_REQUESTS=128 \
-e MAX_CLIENT_BATCH_SIZE=128 \
-e MAX_CONCURRENT_REQUESTS=128 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
$IMG_NAME
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}3.3 确认推理微服务启动状态
执行启动命令后,在对应的微服务启动界面显示如下内容则表示启动成功
Application startup complete4. 配置coze
4.1 配置大语言模型服务
构建模型配置,拷贝coze-studio/backend/conf/model/template/model_template_ark_doubao-seed-1.6.yaml文件至coze-studio/backend/conf/model路径并修改,或在coze-studio/backend/conf/model目录中新建配置 deepseek-r1-distill-qwen-7b.yaml ,如下为参考示例
# deepseek-r1-distill-qwen-7b.yaml
id: 65536 # 自定义模型 ID,必须是非 0 的整数,且全局唯一
name: DeepSeek-R1-Distill # 模型平台展示名称
...
meta:
name: DeepSeek-R1-Distill # 模型名称,用于记录,不展示
protocol: openai # 模型连接协议
capability:
input_modal:
- text # 模型输入支持模态
output_modal:
- text # 模型输出支持模态
prefix_caching: false # 是否支持 prefix caching
reasoning: true # 是否支持 reasoning
prefill_response: false # 是否支持 prefill
conn_config:
base_url: "https://MIS-LLM服务地址HOST:MIS-LLM服务端口PORT/openai/v1" # 根据情况切换https/http服务
api_key: ""
timeout: 0s
model: "DeepSeek-R1-Distill-Qwen-7B" # 模型名称
...4.2 配置向量化模型服务
拷贝示例环境配置
cd coze-studio/docker
cp .env.example .env修改 .env 文件,其修改示例如下
# Settings for Embedding
# The Embedding model relied on by knowledge base vectorization does not need to be configured
# if the vector database comes with built-in Embedding functionality (such as VikingDB). Currently,
# Coze Studio supports three access methods: openai, ark, ollama, and custom http. Users can simply choose one of them when using
# embedding type: openai / ark / ollama / http
export EMBEDDING_TYPE="openai" # ark 修改为 openai
# openai embedding
export OPENAI_EMBEDDING_BASE_URL="https://MIS-EMB服务地址HOST:MIS-EMB服务端口PORT/v1" # (string) OpenAI base_url #按需选择https / http
export OPENAI_EMBEDDING_MODEL="bge-large-zh-v1.5" # (string) embedding model
export OPENAI_EMBEDDING_API_KEY=""
export OPENAI_EMBEDDING_BY_AZURE=false # (bool) OpenAI by_azure 设置为false
export OPENAI_EMBEDDING_API_VERSION=""
export OPENAI_EMBEDDING_DIMS=1024 # (int) 向量维度 # 更换EMB模型需重新配置,详情见 常见问题4 (# https://github.com/coze-dev/coze-studio/wiki/9.-%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98)
export OPENAI_EMBEDDING_REQUEST_DIMS=1024 # 更换EMB模型需重新配置,详情参考同上配置详情请参考coze文档
5. 容器化部署coze
由于 Redis 容器可能因为检测到ARM64架构的内核COW(Copy-on-Write)bug而自动退出,需忽略ARM64-COW-BUG警告(具有安全风险,仅供参考)。
修改 coze-studio/docker 路径下 docker-compose.yml 文件,在 Redis 服务中添加配置 --ignore-warnings ARM64-COW-BUG。
redis:
image: bitnami/redis:8.0
...
command: >
...
exec /opt/bitnami/scripts/redis/entrypoint.sh /opt/bitnami/scripts/redis/run.sh --ignore-warnings ARM64-COW-BUG # 强制跳过COW缺陷告警(生产环境慎用)首次部署并启动 Coze Studio 需要拉取镜像、构建本地镜像,耗时较久
# 启动服务
cd coze-studio/docker
docker compose up -d # Compose V2语法(V1版本替换为docker-compose)6. AI 智能体构建实践
全部服务启动后,访问 http://部署节点IP:8888/ 即可打开 Coze Studio,首次进入需要注册(离线)
6.1. 构建知识库
1. 在 工作空间 中的 资源库 页面中,选中 +资源 下拉菜单中的 知识库

2. 在创建知识库页面,选择 文本格式 ,设置知识库名称,导入类型 选择 本地文档 ,选择 创建并导入
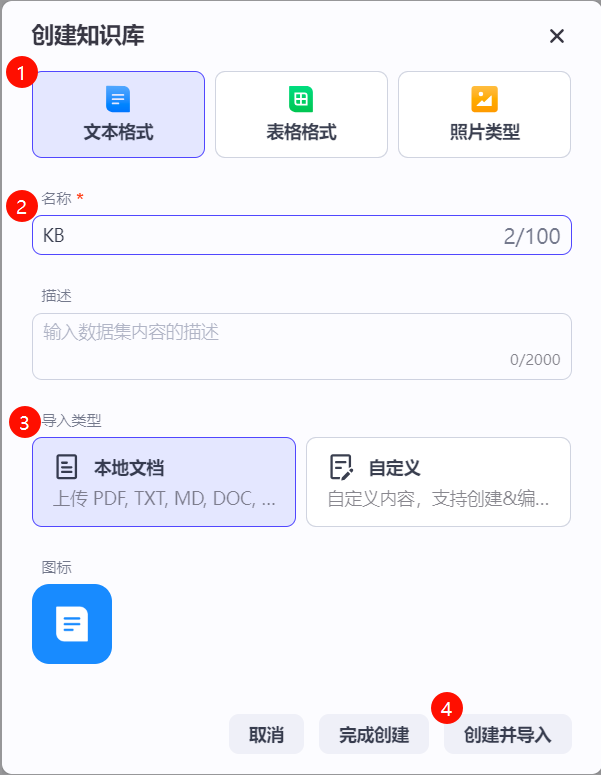
3. 上传相应文件并在完成后点击 下一步
4. 文档解析策略 选择 快速解析,分段策略 选择 自动分段与清洗
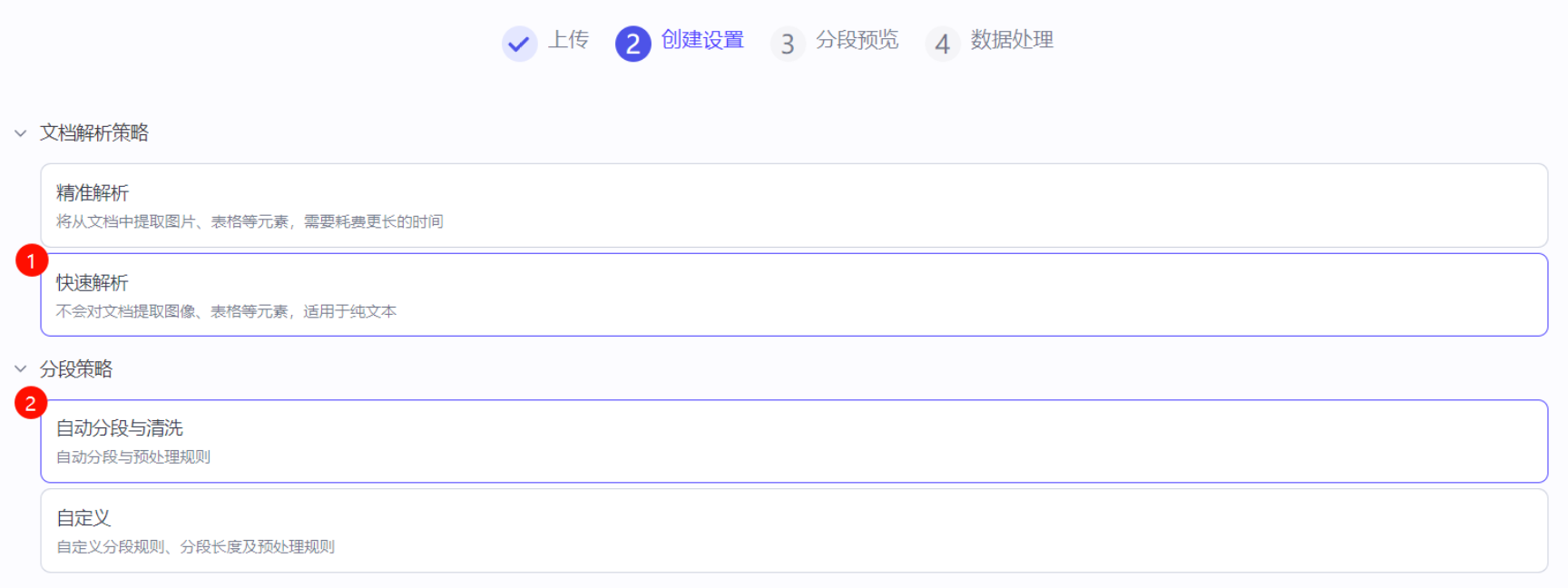
5. 分段预览页面中确定分段符合预期之后选择 下一步
6. 等待知识库完成向嵌入后点击 确认 或直接点击 确认 (点击确认不影响数据处理)
6.2. 创建智能体
1. 在 工作空间 中的 项目开发 页面中,选中 +创建 弹出菜单中的 创建智能体
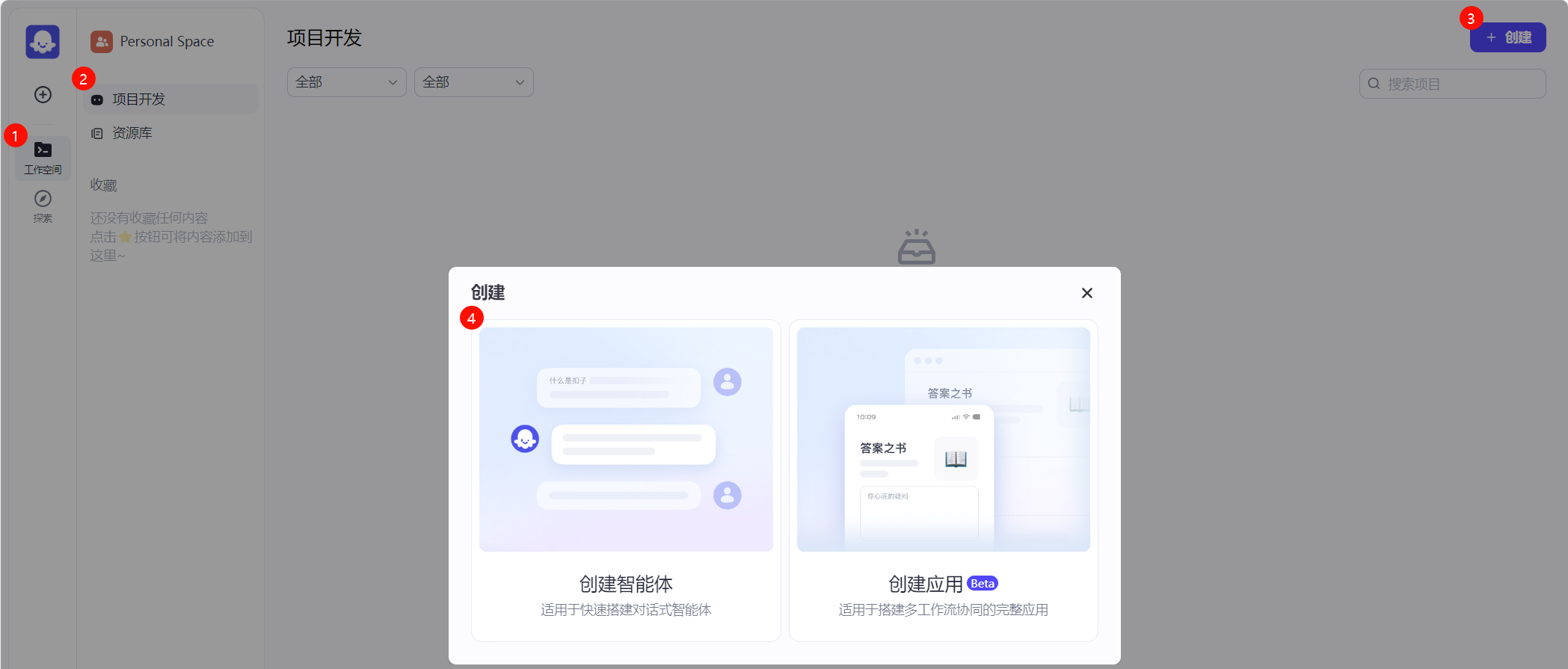
2. 设置 智能体名称 并确认
3. 进入智能体构建页面,左侧为 编排 页面,右侧为 预览与调试 页面
4. 在左侧 编排 页面,可以通过预设模板补全人设与回复逻辑
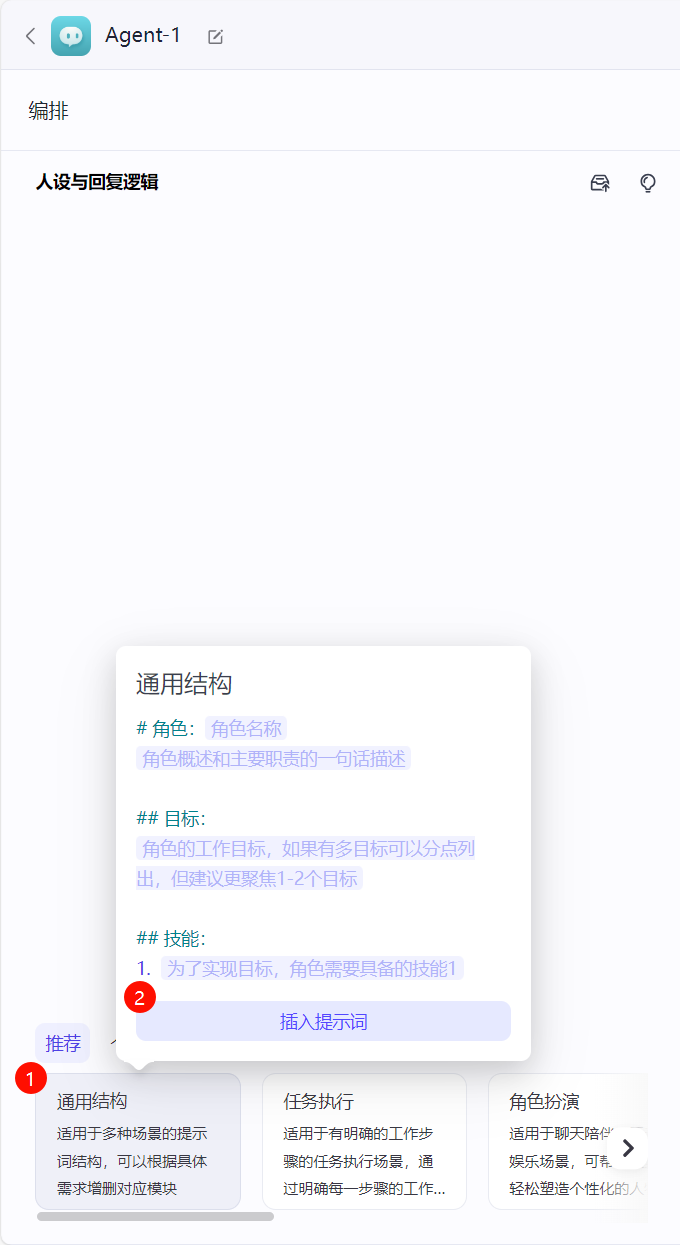
5. 在 编排 右半部分,可以设置对话模型以及知识库
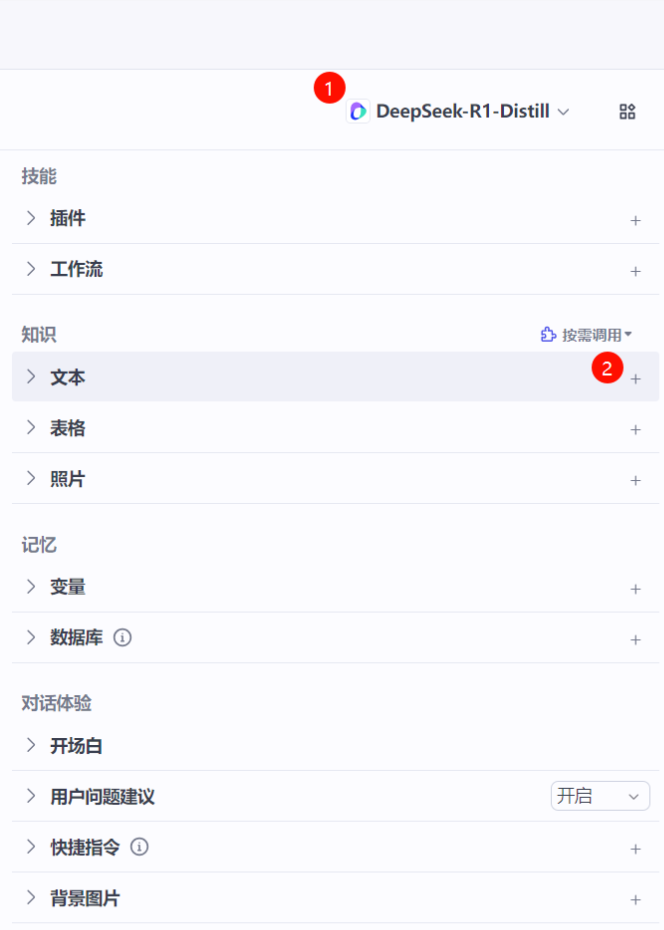
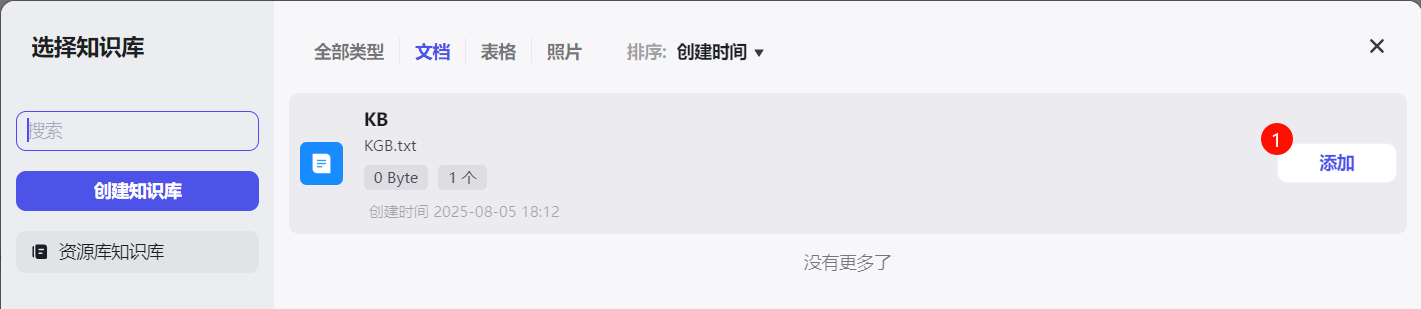
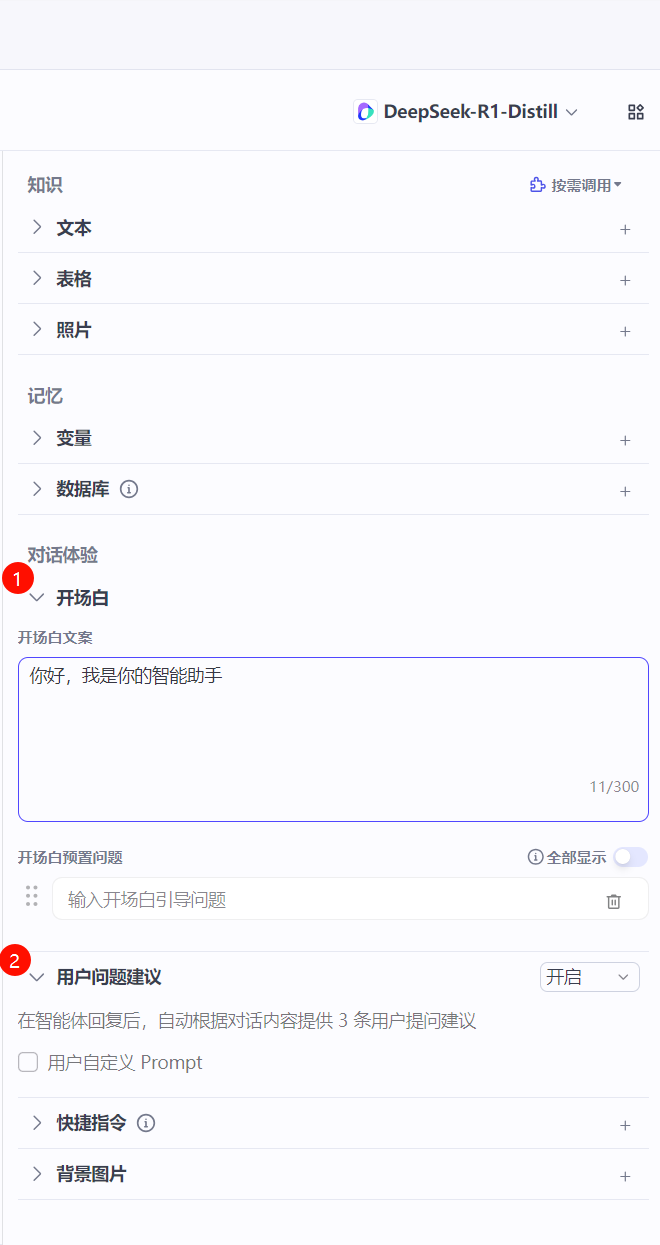
还可以根据需要设置智能体开场白,回复后的自动建议以及其他快捷指令
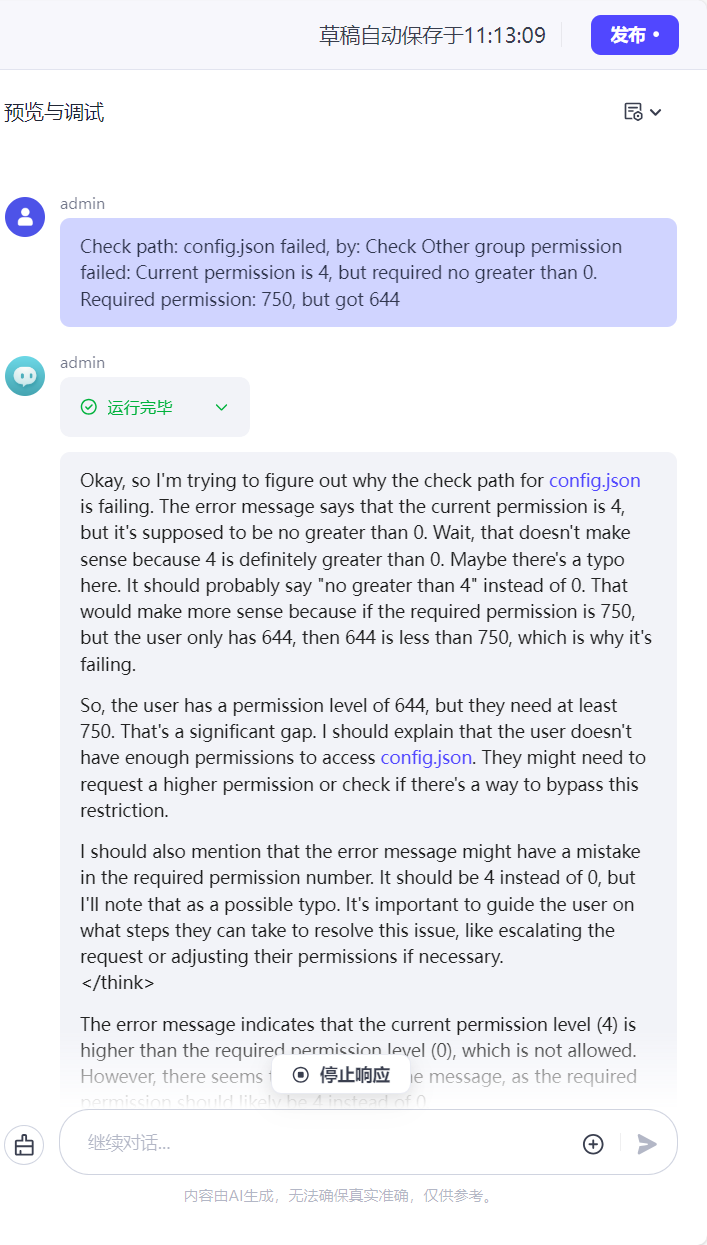
6. 右侧 预览与调试 页面中,可与编排好的Agent对话以调试功能,调试完毕则可发布
更多 MIS 案例可查看:10分钟快速搭建基于推理微服务的RAG对话机器人应用;昇腾多模态SDK视频总结问答应用开发实践