



【昇腾热点算子大解密】CANN创新通算融合算子破局MoE通信瓶颈,实现推理吞吐50%提升
发表于: 2025/07/26
MoE架构带来的通信优化挑战
在大模型训练和推理领域,MoE架构凭借其动态专家激活机制带来的计算稀疏性优势,以及千亿参数规模下的高推理吞吐能力,已然成为超大规模模型的核心技术方案。该架构通过分发(Dispatch)和组合(Combine)这两个关键操作,实现了输入数据的动态分配与多专家输出的高效整合,从而,在维持海量参数规模的同时确保了高性能计算。然而,随着专家并行(EP)规模的不断扩大,专家间频繁交互带来的高额通信开销,逐渐演变成为制约大模型推理性能的关键瓶颈。
创新通算融合算子破局MoE通信瓶颈
针对MoE架构,我们的技术团队深入分析后发现,高额的通信开销主要源于两大技术挑战:
(1) AllToAllV通信的缺陷
动态专家选择机制下,每个Token分发的目标专家呈现离散分布特征,导致两个关键问题:
- 数据分发不均匀:不同专家接收的Token长度存在差异,需依赖低效的AllToAllV通信;
- 元数据同步开销:获取收发信息需调用前置AllGather算子收集路由表,并在Host侧完成同步,引入额外通信开销和Stream同步延迟;
(2) 小数据包与Host Bound困境
推理场景中的Token数据量小,引发双重挑战:
- 算子下发延迟:传统Host驱动通信需要构造子图并调度,其下发时延随EP规模线性增长;
- RDMA同步开销:RDMA前同步和后同步引入额外的RTT时延。
分析这些瓶颈点后,我们创新性地开发了MoeDistributeDispatch和MoeDistributeCombine两个融合算子,并历经三个阶段的迭代优化,最终实现模型推理吞吐提升50%的显著收益。
Dispatch/Combine双算子协同优化
DeepSeekV3模型的MoE架构创新性地采用了动态路由机制,每个Token会动态选择topK个专家进行处理。在这一架构中,Dispatch操作发挥核心调度作用,基于Token与专家的路由对应关系表,采用分布式计算策略:首先将各专家节点需处理的Token数量计算任务下沉到对应设备执行,随后通过AllToAllV通信完成Token的跨设备传输,同时预计算Combine阶段所需参数;而Combine操作则扮演着整合者的角色,负责对各专家输出的计算结果执行加权求和,并通过逆向的AllToAllV通信将处理后的Token数据恢复至原始位置,从而完成整个分布式专家计算的协同与整合。
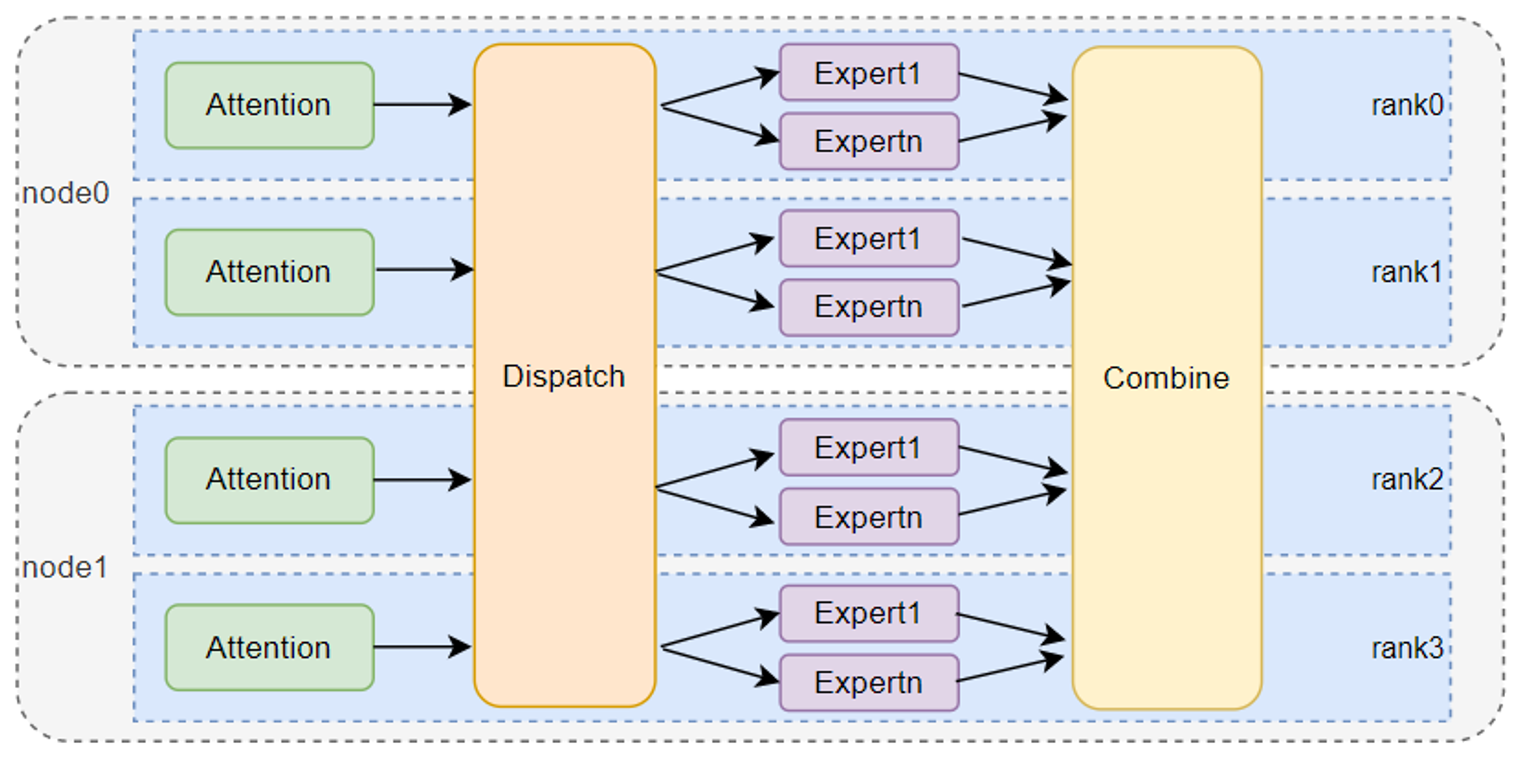
由上可知,Dispatch/Combine操作本质上是计算与通信的结合。因此,我们创新型地实现了MoeDistributeDispatch和MoeDistributeCombine这两个通算融合算子,将路由计算等Host侧逻辑下沉至Device侧,消除了Host与Device间的同步开销。同时,将Combine操作中所需的参数计算、Token的加权求和等计算操作与AllToAllV通信流水并行,也得以实现计算与通信的耗时掩盖。
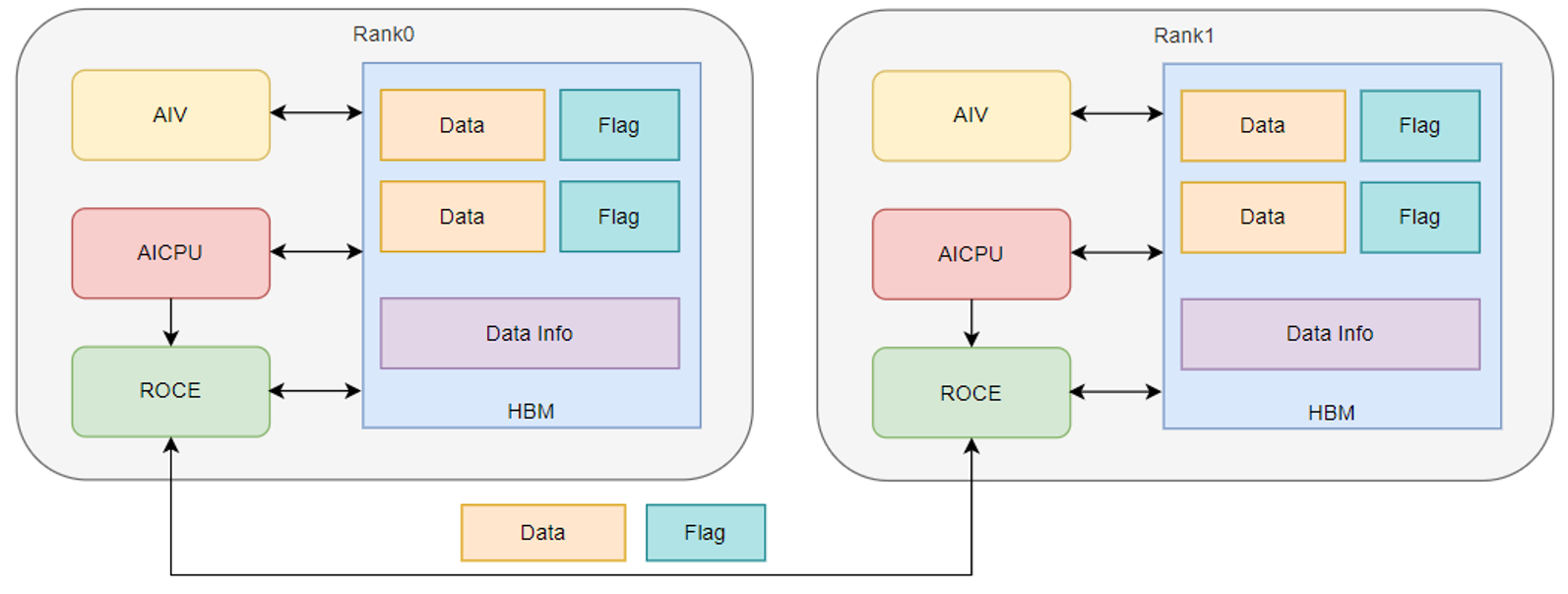
阶段一:基于AIV+AICPU融合架构的RDMA全互联方案
AIV作为昇腾硬件NPU主要的计算单元,负责完成数据的预处理、RDMA通信元数据的准备、数据接收Flag的轮询以及接收数据的后处理等关键环节。
在预处理阶段,首先会获取每个Token的路由信息,依照专家索引对Token进行重排,将发往同一个目标rank的数据汇聚。这样,仅一次通信就可以完成目标rank上所有专家的数据发送,以减少RDMA下发时延。
与此同时,AIV将数据在共享内存中的地址、数据长度信息通过GM直接传递给同处Device侧上的AICPU,由AICPU直接驱动RDMA通信,彻底摒弃了传统需要Host侧构造子图和调度RDMA任务的繁琐流程,不仅解决了Host侧处理耗时长的问题,更消除了传统调度方式带来的额外时延。在通信环节,AIV轮询数据接收Flag,以确保所有rank的Token数据全部接收完成,从而消除RDMA同步带来的通信时延。最后,AIV将共享内存中的数据按照专家汇总搬出,为后续FFN层的计算提供数据准备。这一系列优化形成了完整的低延迟处理闭环。
阶段二:基于AIV+AICPU融合的分层通信方案
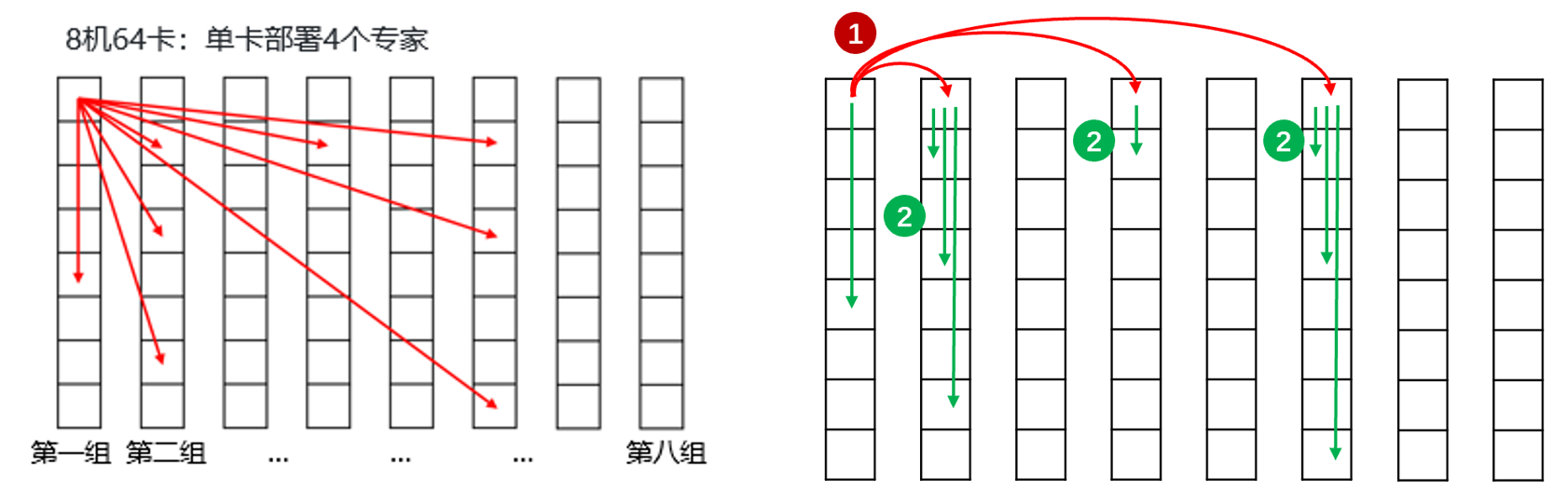
在阶段一的实现方案中,由于完全依赖RDMA通信且昇腾A2的RDMA带宽相对有限,我们的技术团队敏锐地发现了进一步优化通信时延的可能性。经过对DeepSeekV3模型的深入剖析,我们发现其采用了创新的Node-Limited Routing策略,展现出显著的专家路由亲和性特征。具体而言,在8机部署且topK = 8的典型应用场景中,每个Token选择的topK专家呈现出高度集中的分布特性,仅集中分布在4台服务器上。这意味着模型通信中存在着50%的潜在优化空间,有一半的数据可以通过高带宽的机内通信完成传输。
基于这一关键洞察,CANN技术团队创新性地设计了AIV+AICPU分层通信架构:在EP域下,仅同号卡组(如rank0-8-16等)之间维持原有的AICPU直驱RDMA跨机通信机制;而对于非同号卡的目标rank,采用智能中转策略,即先将数据发送至目标节点的同号卡,再由同号卡通过高效的机内通信完成最终传输。基于这一巧妙设计,当Token选择的目标专家分布在同一台服务器上时,仅需完成一次跨机数据通信。这不仅显著降低了跨机通信频次,更大幅缩减了整体跨机通信数据量,为系统性能带来质的提升。
下图直观对比了RDMA全互联通信方案与分层通信方案的架构设计差异。
以BS = 16,H = 7168,topK = 8,数据类型FP16场景为例:
- RDMA全互联方案下,总通信量近似为BS * H * topK * sizeof(FP16) * 63/64 = 1.75(MB)(63/64是因为发往本卡的MoE专家无需通过RDMA通信),总通信时间约86.1us。
- 分层方案下,每个Token平均选择4个node,机间通信量BS * H * 4 * sizeof(FP16) * 7/8 = 0.766(MB),机间通信时间约为38.3us,机内通信量为BS * H * 8 * sizeof(FP16) * 7/8=1.53(MB),机内通信时间约8us,总通信时间46.3us。
分层通信方案充分发挥了机内高带宽的传输优势,可以大幅减少通信耗时。结合上述理论公式推导分析,发现该方案的优化效果与业务场景shape密切相关:BS较大的场景下,由于机间数据聚合效应增强,可获得显著的绝对性能收益;而当EP规模扩大导致MoE专家分布趋于分散时,优化收益则会相应降低,呈现出明显的参数敏感性特征。
阶段三:完全基于AIV的分层通信方案
基于AIV和AICPU的分层通信方案已经充分利用机内高带宽,我们的技术团队进一步深入分析MoeDistributeDispatch和MoeDistributeCombine算子的流水分布情况,识别到当前融合方案仍存在优化空间。虽然实现了计算与通信的初步融合,但受限于AICPU驱动RDMA时WQE串行下发的固有机制,导致计算与通信、机间与机内通信无法实现深度流水并行,且下发时延随下发次数线性增长的问题迫使数据必须按目标rank汇聚。
为了提高流水并行度,技术团队在AIV+AICPU分层方案的基础上,创新性地实现了AIV直驱RDMA的通路。该方案不再依赖AICPU,实现更低时延,且多个AIV核可以并行下发WQE,WQE下发时延不再是算子耗时的关键,彻底解除了Token数据需按照目标rank汇聚的限制,可以直接以Token为粒度发送;同时,将机间RDMA接收和机内转发处理前置,实现机间和机内通信流水并行,进一步掩盖通信耗时,最终使得算子平均性能较原有AIV+AICPU的分层方案提升10%+,为MoE架构的通信优化树立了新的标杆。
结语
CANN在昇腾平台上的持续创新实践中,从全互联RDMA到创新性的AIV直驱RDMA流水并行,MoeDistributeDispatch和MoeDistributeCombine算子不断突破通信性能的边界——每一次技术跃迁都在重新定义算力的天花板。正是这种对通信效率的极致追求,让我们得以逐步解锁MoE架构千亿参数模型的部署潜能,将理论性能转化为现实生产力。
MoeDistributeDispatch和MoeDistributeCombine算子功能通过CANN软件包使能,社区版资源下载地址:
https://www.hiascend.com/developer/download/community/result?module=cann
算子接口定义为:
aclnnStatus aclnnMoeDistributeDispatchGetWorkspaceSize(const aclTensor* x, const aclTensor* expertIds, const aclTensor* scales,
const aclTensor* xActiveMask, const aclTensor* expertScales, const char* groupEp, int64_t epWorldSize, int64_t epRankId,
int64_t moeExpertNum, const char* groupTp, int64_t tpWorldSize, int64_t tpRankId, int64_t expertShardType, int64_t sharedExpertNum,
int64_t sharedExpertRankNum, int64_t quantMode, int64_t globalBs, int64_t expertTokenNumsType, aclTensor* expandX, aclTensor* dynamicScales,
aclTensor* expandIdx, aclTensor* expertTokenNums, aclTensor* epRecvCounts, aclTensor* tpRecvCounts, aclTensor* expandScales,
uint64_t* workspaceSize, aclOpExecutor** executor)
aclnnStatus aclnnMoeDistributeDispatch(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
aclnnStatus aclnnMoeDistributeCombineGetWorkspaceSize(const aclTensor* expandX, const aclTensor* expertIds, const aclTensor* expandIdx,
const aclTensor* epSendCounts, const aclTensor* expertScales, const aclTensor* tpSendCounts, const aclTensor* xActiveMask,
const aclTensor* activationScale, const aclTensor* weightScale, const aclTensor* groupList, const aclTensor* expandScales,
const char* groupEp, int64_t epWorldSize, int64_t epRankId, int64_t moeExpertNum, const char* groupTp, int64_t tpWorldSize, int64_t tpRankId,
int64_t expertShardType, int64_t sharedExpertNum, int64_t sharedExpertRankNum, int64_t globalBs, int64_t outDtype, int64_t commQuantMode,
int64_t groupList_type, aclTensor* x, uint64_t* workspaceSize, aclOpExecutor** executor)
aclnnStatus aclnnMoeDistributeCombine(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)详细接口文档可参考昇腾社区API描述: