



告别参数泥潭!MindStudio快速锁定大模型推理服务化吞吐最优解
发表于: 2025/07/18
服务化参数调优难题
大模型上线服务时,开发者们常陷入这样的困境:
- 手动试错成本高:batch size、最大token数、并发线程数等参数组合爆炸式增长;
- 算力消耗大:参数测试验证动辄消耗数小时算力;
- 延迟与吞吐难平衡:需满足低延迟的同时追求最大吞吐;
- 影响因子多:请求长度不一,负载特征不同,硬件配置、量化精度、并行策略不同,批处理、调度算法配置差异等都会影响服务化性能。
大模型服务化部署的最大痛点,往往不是模型本身,而是服务化参数的调优迷宫。传统人工调优难以应对上述多维变量的组合爆炸问题,如同盲人摸象。
针对此类调优难题,MindStudio全新推出服务化自动寻优工具(msServiceProfiler Optimizer),帮助开发者降低试错成本,快速获取服务化参数优解。
MindStudio服务化自动寻优特性解读
MindStudio 服务化自动寻优工具,支持 MindIE Service 和 vLLM两大主流服务化框架,提供仿真与轻量化双模引擎,帮助开发者推荐参数组合以自动优化服务吞吐。
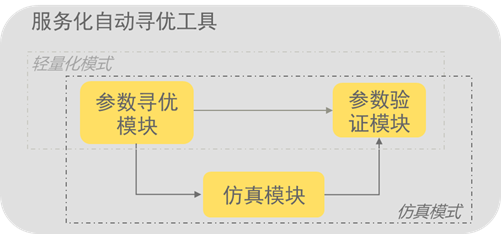
图1. 服务化自动寻优工具架构示意图
工具支持仿真与轻量化两种模式,主要包括三大核心功能模块:
- 参数验证模块:自动化启动服务化进程与Benchmark进程,进行参数测试,获取性能结果。
- 参数寻优模块:利用PSO粒子寻优算法自动生成服务化参数组合,不断逼近最优解;同时,Early Rejection算法通过理论建模、调优经验、及部分实测数据对服务化参数完成早期评估;
- 仿真模块:基于XGBoost模型对大模型推理时长进行精确预测,结合服务化调度的虚拟时间轴技术,加速服务化参数验证速度。
服务化自动寻优工具能够基于以上功能模块,自动推荐吞吐较优的服务化参数组合。轻量化模式注重精度与可靠性,结合参数验证、参数寻优模块,通过真机实测给出可靠的服务化参数推荐值。仿真模式注重速度及资源占用,调动所有模块快速、精确地预测各组参数的吞吐,在较低NPU资源占用的前提下给出服务化参数推荐值。
经典案例与操作指南
接下来,我们通过一个DeepSeek调优案例带领大家一起学习工具的使用方法。开发者在使用MindIE Service部署服务时,虽然硬件优化均已打开,但仍未达到预期吞吐,需要从服务化参数调优打开突破口。
1)环境准备
确保环境可以拉起MindIE Service服务,以及Benchmark服务。
推荐使用PyPI源安装服务化自动寻优工具:
# 轻量化模式
pip install -U msserviceprofiler .[real]
# 仿真模式(全量)
pip install -U msserviceprofiler .[speed]2)轻量化寻优
Step1. 修改配置文件,指定寻优参数及服务化参数
修改config.json内容,包括寻优参数:n_particles(粒子寻优每轮生成的服务化参数的组数)、iters(粒子寻优的轮数)、decode_constraint(time_per_output_token的限制时延约束)等。
以及服务化参数,如下配置表示服务化参数max_batch_size的寻优搜索空间为10~400:
{
"name": "max_batch_size",
"config_position": "BackendConfig.ScheduleConfig.maxBatchSize",
"min": 10,
"max": 400,
"dtype": "int"
}Step2. 开启轻量化寻优
执行以下命令,一键启动寻优:
msserviceprofiler optimizer寻优成功时终端输出如下:
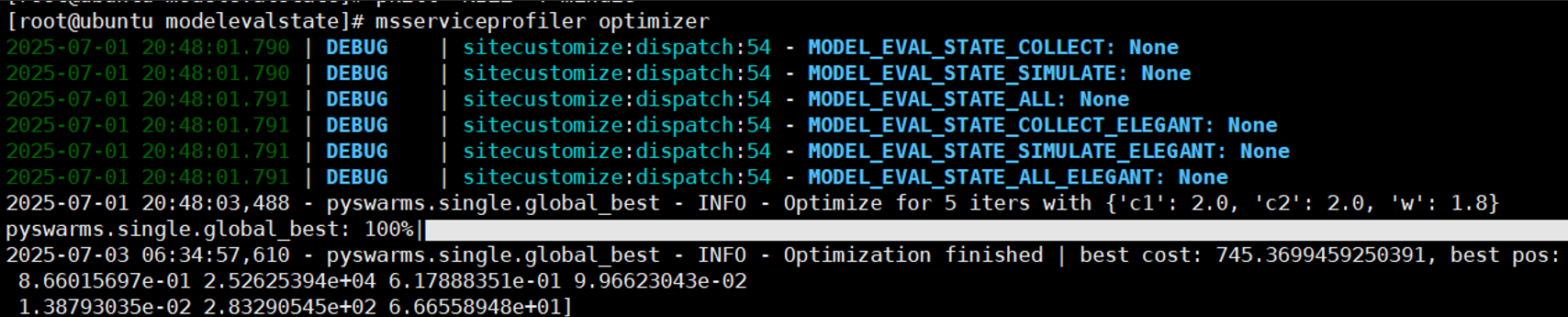
图2. 轻量化寻优成功终端展示
模型的大小和Benchmark请求数量决定寻优时间,一般在4~8小时完成,结束后会输出一个名为data_storage_*.csv的文件,其中记录了各组参数的性能,如:

图3. 寻优结果展示
寻优输出csv文件每一行为一组服务化参数测试结果,根据其内容可以筛选出符合要求的吞吐最佳的服务化参数组合。若用户的要求是延迟(time_per_output_token)必须小于0.05秒,那么选择第三列time_per_output_token小于0.05的参数组合,并在第一列generate_speed中选择吞吐最大的一组或若干组参数即可。
3)仿真模式寻优
仿真模式需要增加对XGBoost模型的训练步骤,训练后,模型会自动将前向推理过程进行mock模拟,避免长时间占用NPU资源,提升测试效率。
Step1:采集服务化性能数据
利用服务化性能采集功能(参考https://www.hiascend.com/document/detail/zh/mindstudio/80RC1/T&ITools/Profiling/mindieprofiling_0001.html)对MindIE推理服务进行一次profiling性能数据采集与解析,存入自定义路径(/path/to/input)。包括以下关键指标:forward_time(前向计算时长,即预测目标), batch_type(推理阶段,Prefill或Decode), batch_size(组batch大小), need_blocks(显存占用数)等。
Step2:载入XGBoost模型训练
将上一步profiling数据解析数据作为输入,载入XGBoost进行模型训练,训练完成后,会在用户自定义路径(/path/to/output)落盘新模型,用于预测前向计算时长,模拟真实推理过程。
msserviceprofiler train -i=/path/to/input -o=/path/to/outputStep3:配置参数
参考上一节轻量化寻优Step1的操作,在config.json中配置寻优参数与服务化参数。
Step4:启动仿真寻优
配置完成后即可启动仿真寻优:
export MODEL_EVAL_STATE_ALL=True
msserviceprofiler optimizer寻优结果存储在data_storage_*.csv文件中,目前仿真的精度误差在5%左右,但不同环境或不同运行模式可能有一定差异。建议筛选2~3组仿真模式推荐参数,在真机环境中再次实测,根据实测结果确定最终的服务化参数。
4)寻优结果分析(可选)
寻优结果支持使用Tensorboard可视化分析,使用以下命令:
python tensorboard_hparam_visualize.py –saved_csv_result data_storage_*.csv –target average_decode-metric throughput
tensorboard –logdir mindie_hpo_results –bind_all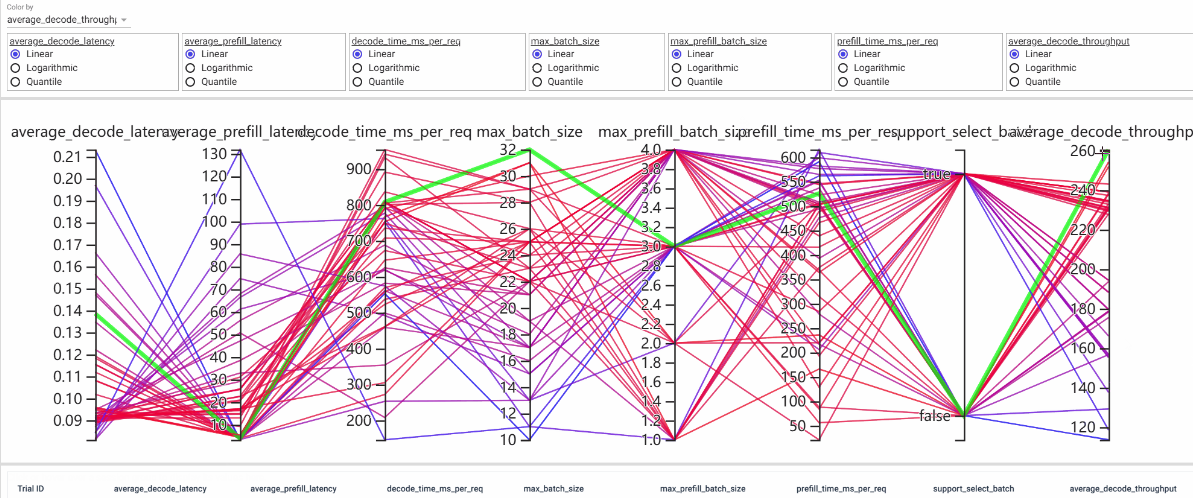
图4. Tensorboard寻优结果可视化
在上图中,最右侧轴代表优化目标average_decode_throughput(平均decode吞吐量),其左侧每个轴都表示影响该目标的关键参数,各个参数与最终优化目标通过连线相关联,线条颜色越红的路径指向的最终吞吐量越大。被选中的参数组合被标识为绿色。以参数max_batch_size(第4轴)为例,可以看出红色折线集中在max_batch_size的上端,即max_batch_size参数取值越大,越有可能带来较大吞吐。
结语
MindStudio服务化自动寻优工具,通过仿真建模,自动搜索推荐最优配置参数,帮助开发者告别繁琐的参数调试流程,有效减少反复分析服务化参数-实测-再分析的试错过程,大幅提升服务化调优效率。目前该工具已正式发布,欢迎广大开发者点击链接下载体验!