



开源即支持!基于昇腾MindSpeed MM玩转GLM-4.1V-Thinking多模态理解最新模型
发表于: 2025/07/02
当前,多模态模型正从感知走向认知。通过引入强化学习机制,提升模型的推理能力,已成为提升多模态问答准确性与生成质量的重要路径。2025年7月2日,智谱正式发布GLM-4.1V-Thinking系列模型,其10B参数级别的视觉语言模型在兼顾部署效率的同时实现性能突破。MindSpeed MM首次实现了对GLM多模态理解模型的无缝支持,并同步开放源代码,目前不仅支持在线推理功能,还提供了基于GLM-4.1V-Thinking的微调实践参考。作为昇腾多模态大模型套件,MindSpeed MM基于MindSpeed Core构建,专注于多模态大规模分布式训练环境下的性能优化,致力于为开发者打造高效便捷的开发体验。
1、GLM-4.1V-Thinking模型介绍
GLM-4.1V-Thinking是一款支持图像、视频、文档等多模态输入的通用推理型大模型,专为复杂认知任务设计。它在GLM-4V架构基础上引入“思维链推理机制(Chain-of-Thought Reasoning)”,采用“课程采样强化学习策略(RLCS, Reinforcement Learning with Curriculum Sampling)”,系统性提升模型跨模态因果推理能力与稳定性。
模型特别在以下任务中表现卓越,展示出高度的通用性与稳健性:
l 图文理解(Image General):精准识别并综合分析图像与文本信息;
l 数学与科学推理(Math & Science):支持持复杂题解、多步演绎与公式理解;
l 视频理解(Video):具备时序分析与事件逻辑建模能力;
l GUI 与网页智能体任务(UI2Code、Agent):理解界面结构,辅助自动化操作;
l 视觉锚定与实体定位(Grounding):语言与图像区域精准对齐,提升人机交互可控性。
2、基于MindSpeed MM的GLM-4.1V-Thinking训练优化特性
基于多模态理解模型涉及文本、图像、音频、视频等模态数据,不同模态数据存在结构差异、特征差异和融合策略多样性、训练机制复杂等特点,模型训练存在负载不均衡、资源利用低等问题。昇腾MindSpeed MM在使用了融合算子、分布式优化器及流水调度优化等常用特性的基础上,陆续使能Encoder数据负载均衡、多模态异构流水线并行、动态流水线并行、数据分桶负载均衡、虚拟流水线并行、分离部署等优化加速特性,实现性能优化,更好地实现GLM-4.1V-Thinking多模态理解模型的微调训练效果。
Encoder数据负载均衡:
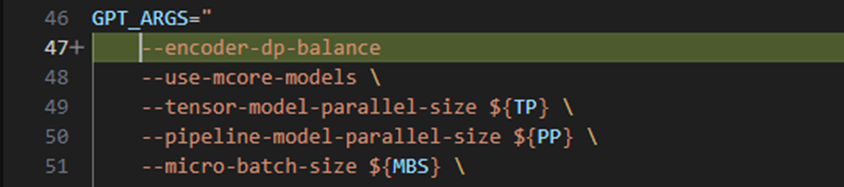
在分布式训练中,当数据并行度(Data Parallelism, DP)大于1时,由于不同DP分组间处理的图像Patch数量不均,加之Vision Transformer(ViT)与MLP 的计算复杂度差异较大,导致各设备在训练过程中计算负载不均衡。这种不均衡性会在梯度AllReduce阶段引发同步等待问题,从而降低整体训练效率。Encoder数据负载均衡通过AlltoAll通信机制实现跨DP组的数据重分配,将拥有较多Patch的DP设备上的数据迁移至负载较低的DP设备,从而在Encoder阶段实现计算负载均衡,提升性能5%。
使能方式:在examples/glm4.1v*/finetune_glm4.1v*B.sh中配置--encoder-dp-balance字段。(具体使用方式可参考仓库特性文档https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/docs/features/encoder_dp_balance.md)
分离部署(Dist-train):
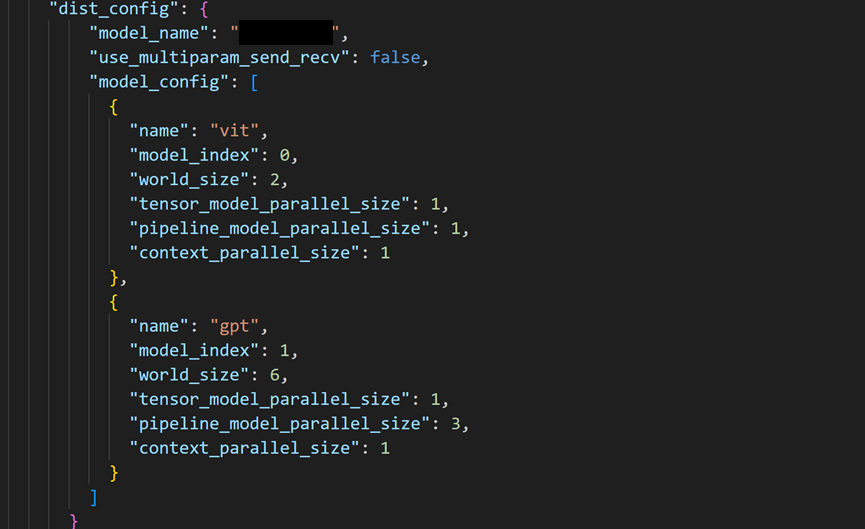
多模态模型的训练中,由于不同模态模型对算力和内存需求的异构性,不同模态模型的最优并行配置往往不一致,如果全部使用同一种并行配置,会造成负载不均衡、资源利用不充分。MindSpeed MM支持Dist-train功能,通过对异构模型配置不同的计算资源和并行配置,减少冗余的静态资源和异构模型间的空泡(bubble),使异构模型之间的运行速度达到最优匹配,提升性能15%。
使用方式:在examples/ glm4.1v*/ finetune_glm4.1v*B.sh中添加参数--dist-train,同时配置model.json中的dist_config字段。(具体使用方式可参考仓库特性文档https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/docs/features/dist-train.md)
3、基于MindSpeed MM微调训练的GLM-4.1V-Thinking模型推理体验
新一代的GLM-4.1V-Thinking多模态理解模型专注于实用场景中的推理与理解能力,让我们快速体验一下。
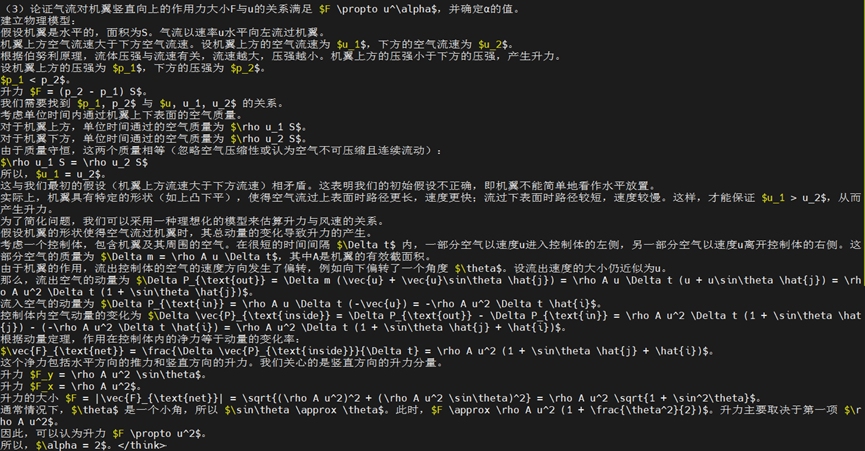
(1)物理解题

Prompt:解题,给出详细过程和答案
思考过程:

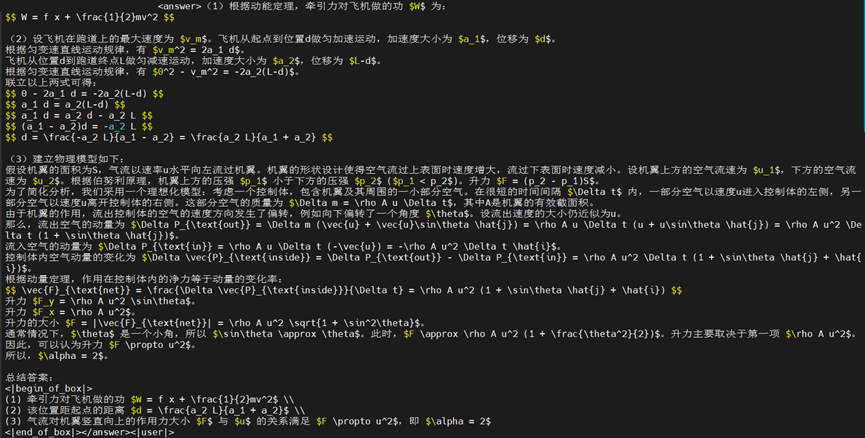
最终答案
(2)GUI问答
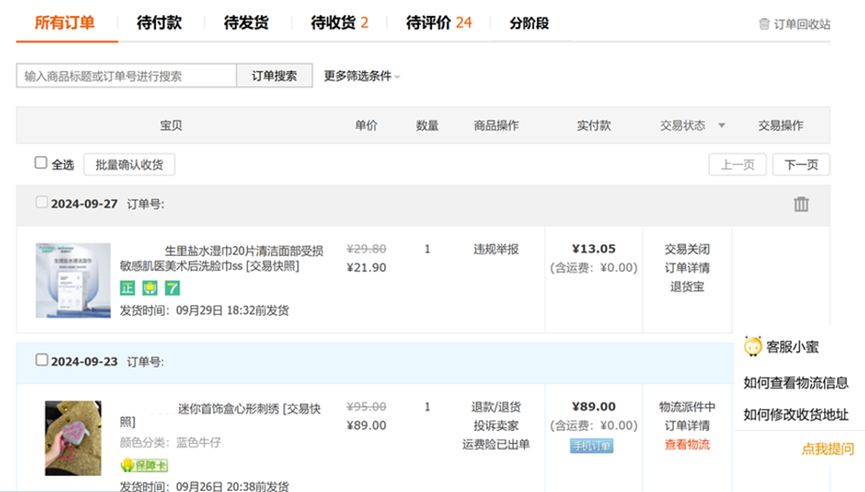
Prompt:问:两个商品哪个折扣力度大?
思考过程:

最终答案

(3)视频理解
Prompt:Q:为什么紫⾊的球动了?
思考过程:
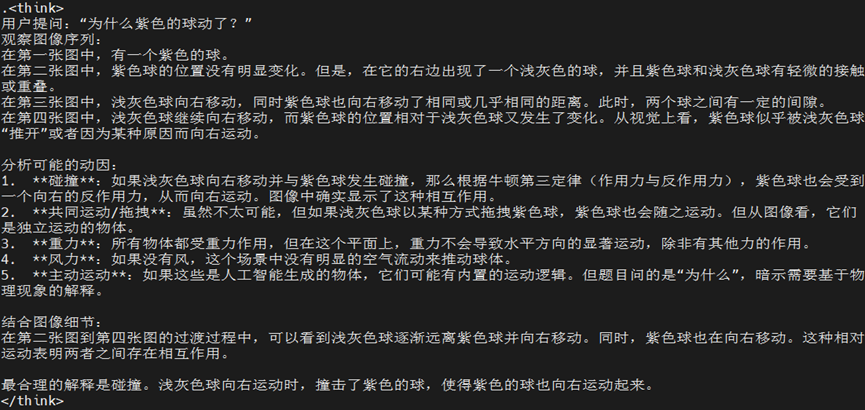
最终答案

4、 快速上手-基于MindSpeed MM玩转GLM-4.1V-Thinking
【环境安装】
模型开发时推荐使用配套的环境版本,详见仓库中的“环境安装”
https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/examples/glm4.1v/README.md
【权重下载及转换】
GLM-4.1V-9B系列模型权重下载:
| 模型 | 下载地址 | 模型类型 |
| GLM-4.1V-9B-Thinking | https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking | 推理模型 |
| https://modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Thinking | ||
| https://modelers.cn/models/zhipuai/GLM-4.1V-9B-Thinking | ||
| GLM-4.1V-9B-Base | https://huggingface.co/THUDM/GLM-4.1V-9B-Base | 基座模型 |
| https://modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Base | ||
| https://modelers.cn/models/zhipuai/GLM-4.1V-9B-Base |
权重转换:
MindSpeed-MM修改了部分原始网络的结构名称,使用mm-convert工具对原始预训练权重进行转换。该工具实现了huggingface权重和MindSpeed-MM权重的转换以及PP(Pipeline Parallel)的权重切分。
# 根据实际情况修改 ascend-toolkit 路径
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 9B
mm-convert GlmConverter hf_to_mm \
--cfg.mm_dir "pretrained/GLM4.1V-9B" \
--cfg.hf_config.hf_dir "raw_ckpt/GLM4.1V-9B" \
--cfg.parallel_config.llm_pp_layers [[7, 11, 11, 11]] \
--cfg.parallel_config.vit_pp_layers [[24,0,0,0]] \
--cfg.trust_remote_code True
# 其中:
# mm_dir: 转换后保存目录
# hf_dir: huggingface权重目录
# llm_pp_layers: llm在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# vit_pp_layers: vit在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# trust_remote_code: 为保证代码安全,配置trust_remote_code默认为False,用户需要设置为True,并且确保自己下载的模型和数据的安全性
【数据集准备及处理】
数据集下载:
用户需自行获取并解压GLM4.1V-Finetune数据集到dataset/playground目录下,以数据集ai2d为例,解压后的数据结构如下:
$playground
├── data
├── ai2d
├── abc_images
├── images
├── opensource
├── ai2d_train_12k.jsonl
【微调】
(1) 由于当前官仓还未开源微调代码和脚本,正式版的微调功能后续跟进上线;
(2)用户想尝鲜微调功能,可参考GLM-4.1V-Thinking的微调实践(https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/examples/glm4.1v/README.md)
【推理】
1.准备工作
配置脚本前需要完成前置准备工作,包括:环境安装、权重下载及转换,详情可查看对应章节。(当前支持9B单卡推理)
推理权重转换命令如下:
# 根据实际情况修改 ascend-toolkit 路径
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 9B
mm-convert GlmConverter hf_to_mm \
--cfg.mm_dir "pretrained/GLM4.1V-9B \
--cfg.hf_config.hf_dir "raw_ckpt/GLM4.1V-9B \
--cfg.parallel_config.llm_pp_layers [[40]] \
--cfg.parallel_config.vit_pp_layers [[24]] \
--cfg.trust_remote_code True
2.配置参数
参数配置:
修改inference_glm4.1v_9b.json文件,包括infer_data_type、file_path、prompts、from_pretrained以及tokenizer的from_pretrained等字段。
单图推理:
以GLM4.1V-9B为例,按实际情况修改inference_ glm4.1v_9b.json对应参数,注意tokenizer_config的权重路径为转换前的权重路径。
{
"image_path": "./examples/glm4.1v/view.jpg", # 按实际情况输入图片路径
"prompts": "Please describe the image shortly.", # 按实际情况输入提示词(支持中英文)
"pipeline_class": " GlmPipeline",
...
"tokenizer":{
...
"autotokenizer_name": "AutoTokenizer",
"from_pretrained": "raw_ckpt/GLM4.1V-9B",
...
},
...
}
视频推理:
以GLM4.1V-9B为例,按实际情况修改inference_ glm4.1v_9b.json对应参数,注意tokenizer_config的权重路径为转换前的权重路径。(推理demo视频下载red-panda)
{
"video_path": "examples/glm4.1v/red-panda.mp4", # 按实际情况输入视频路径
"prompts": "Please describe the video shortly.", # 按实际情况输入提示词(支持中英文)
"pipeline_class": " GlmPipeline",
...
"tokenizer":{
...
"autotokenizer_name": "AutoTokenizer",
"from_pretrained": "raw_ckpt/GLM4.1V-9B",
...
},
...
}
修改启动脚本:
按实际情况修改inference_glm4.1v_9b.sh脚本。
# 根据实际情况修改 ascend-toolkit 路径
source /usr/local/Ascend/ascend-toolkit/set_env.sh
...
MM_MODEL="./examples/glm4.1v/inference_ glm4.1v_9b.json"
3.启动推理
bash examples/glm4.1v/inference_glm4.1v_9b.sh【更多参数见MindSpeed MM仓库】
准备工作和参数说明见MindSpeed MM开源代码仓链接:
https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/examples/glm4.1v/README.md
5、结语
MindSpeed MM是面向大规模分布式训练的昇腾多模态大模型套件,同时支持多模态生成及多模态理解,旨在为昇腾硬件提供端到端的多模态训练解决方案, 包含预置业界主流模型,数据工程,分布式训练及加速,预训练、微调、在线推理任务等特性。
由于当前GLM-4.1V-Thinking系列模型的代码和训练微调功能等未完全发布开源,后续基于MindSpeed MM,GLM-4.1V-Thinking模型将同步上线更加丰富的特性,敬请期待。
欢迎关注MindSpeed MM:https://gitee.com/ascend/MindSpeed-MM