



【昇腾热点算子大解密】CANN创新MoE融合算子,巧用排序算法优化,计算性能实现近4倍提升
发表于: 2025/07/02
MoE架构带来的专家负载均衡与通信优化挑战
在MoE模型中,每个输入(Token)会通过路由门控动态选择Top-K个专家对其进行处理。单一Token会被分配给少数专家,而不同专家接收到的Token数可能存在差异,导致部分专家过载而其他专家闲置。这种负载不均会引发两个关键问题:一方面,过载专家将成为计算瓶颈,降低整体训练效率;另一方面,闲置专家的算力无法被充分利用,也会造成计算资源浪费。除此以外,在分布式训练场景下,专家通常分布在不同的计算卡上,需根据路由结果AllToAll通信,将Token分发至专家所在的目标设备。若Token未按专家ID排序,通信时需为每个Token单独传输目标设备信息,这会导致通信效率大幅降低。
亲和昇腾微架构特性,创新优化排序算法
为应对上述挑战,我们会需要对Token进行重排(Permute)与反重排(Unpermute)的排序处理:首先将输入Token按专家ID进行重排操作,使得属于同一专家的Token在内存中连续存储;待专家计算完成后,再执行反重排操作,将计算结果还原至原始顺序并累加输出。
在专家并行的分层通信架构中,会涉及分别在外层和内层进行重排/反重排的排序操作。其中,外层处理跨专家组的Token排序,主要负责由专家编号区间构成的专家组之间的数据交互,处理跨机的分发与通信;内层处理单个专家组内部的Token排序,优化机内多卡间的分发与通信。值得注意的是,外层操作涉及将切片处理后的重排序列作为输出/输入,而内层操作则无需切片处理。基于这种设计差异,内层操作实质上可以看作是外层操作的特例,因此在性能优化时,我们只需重点考虑更具普适性的外层优化策略即可。
基于传统的排序算法,结合昇腾微架构特性,我们通过优化算法逻辑,以及将多个细粒度小算子融合,创新了具备重排与反重排功能的融合算子MoeTokenPermuteWithEP与MoeTokenUnpermuteWithEP,显著降低了内存搬运带来的性能损耗。新算法不仅简化了计算流程,也大幅提升了整体运算效率。这一优化方案通过算子融合有效减少了数据交互开销,充分发挥了硬件的并行计算能力,实现了端到端的性能跃升。
重排融合算子MoeTokenPermuteWithEP
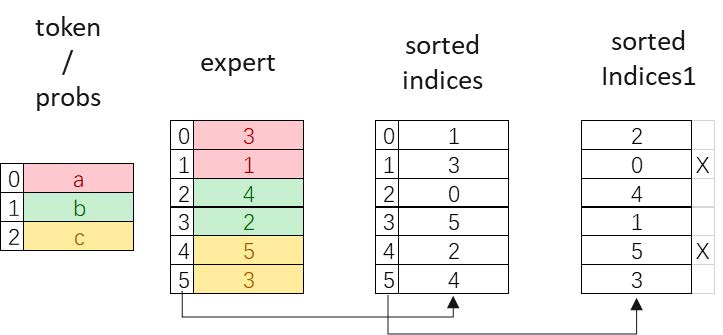
在MoE模型的路由分发机制中,每个输入Token会被动态分配到K个不同的专家进行处理。比如以Token a、b、c为例:a被路由至专家3和1,b分配给专家4和2,c被分发至专家5和3。为优化计算效率,我们会将路由到同一专家的Token排序后聚合重组来降低通信开销。在本示例中,Token a和c都被分发到了专家3,因此需要将它们重新排序至相邻位置。
在传统实现方案中,重排操作采用小算子串行调用的处理逻辑:首先对专家索引通过Sort进行排序,随后根据专家组的起始索引进行Slice切片划分,接着通过FloorDiv将专家索引映射到对应的Token,最终按照排序后的Token索引通过Gather完成数据重排。然而,这种方案存在明显的性能瓶颈,由于FloorDiv算子必须在相对低效的AICPU上执行,严重制约了整体训练吞吐。
为此,我们对传统的重排实现方案进行了深度优化,创新性地提出了一种功能等价但性能更优的新方案。MoeTokenPermuteWithEP融合算子通过三大创新突破性能瓶颈:
(1) 双重排序机制:首轮排序专家序列(如[3, 1, 4, 2, 5, 3]→[1, 2, 3, 3, 4, 5]),获得位置索引sorted_indices = [1, 3, 0, 5, 2, 4];次轮对sorted_indices再排序得到sorted_indices1 = [2, 0, 4, 1, 5, 3],指示了排序后的Token位置索引;
(2) 智能索引拷贝:AICore并行加载Token数据后,基于sorted_indices1执行范围检查,校验后智能写出,完全规避FloorDiv计算;
(3) 计算流重构:将原本分散的排序、切片、映射操作融合为AICore上的高效循环计算。
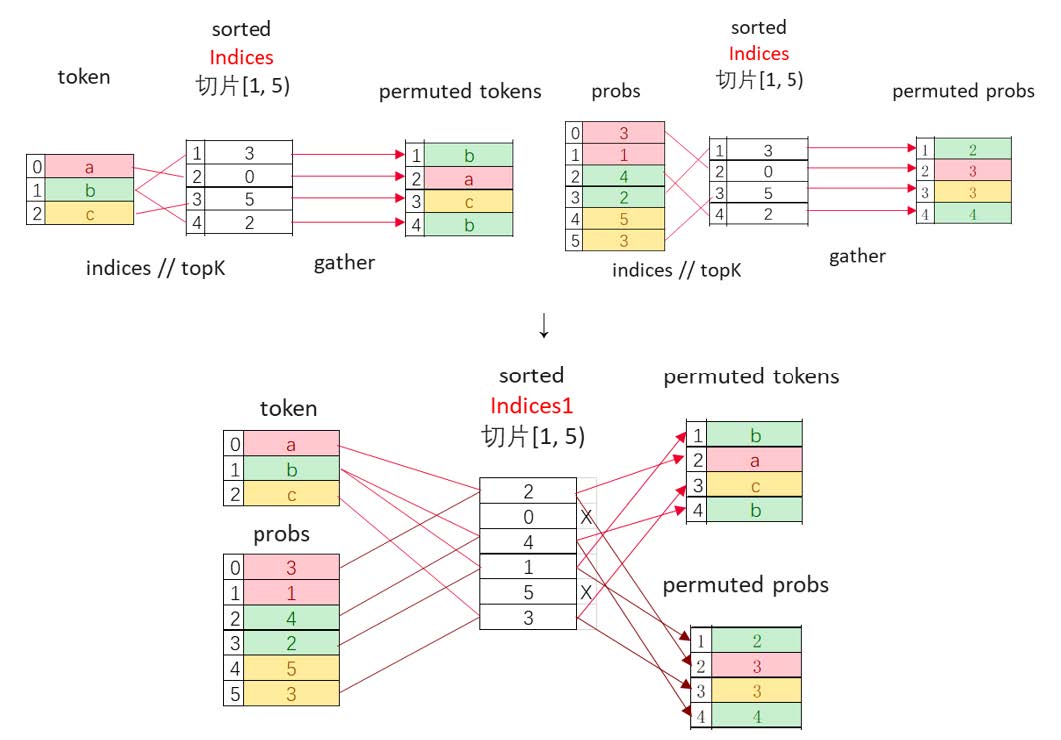
相比传统重排实现,在MoeTokenPermuteWithEP融合算子运行时,每个vector核只需处理输入Token/probs/indices1的局部数据片段,并支持对输出空间的全局访问。由于全局地址偏移信息已预编码在索引中,在实现高效内存访问的同时,完全规避了FloorDiv计算,彻底消除了AICPU计算瓶颈和数据搬运开销,实现3.5倍的性能提升。
反重排融合算子MoeTokenUnpermuteWithEP
在专家处理完Token后,为了得到最终输出结果,我们还需要将同一Token分散在不同专家上的计算结果聚合,再将Token序列恢复至原始顺序,最后基于概率权重对同一Token的多个专家输出进行加权求和。为此,我们设计了与前述重排过程相对应的反重排机制。
在反重排机制中,每个专家分配到的Token会有对应的权重(probs),其序列长度与专家序列长度一致。传统实现方案中,probs首先需要基于sorted_indices位置索引,通过Gather操作进行排序,这样可以与排序后的Token序列保持对应。随后,将probs与专家输出对位相乘的结果写出至由FloorDiv处理后的位置索引,最终得到反重排后的Token输出。我们可以发现,对AICPU计算的依赖仍是一个性能瓶颈点,同时,在全局内存的累加操作也还有优化空间。
同样的,我们对反重排计算流程也进行了深度优化,MoeTokenUnpermuteWithEP算子通过三重创新实现突破:
(1) 双重排序机制:延续重排算子的优化思路,完全规避AICPU计算;
(2) 片上累加优化:在统一缓冲区(UB)内完成Gather和累加计算,避免全局内存(GM)访问,以缓存累加替代内存累加;
(3) 智能算子融合:通过算子融合,当probs非空时,直接在UB完成乘法和写出,节省完整GM读写周期。
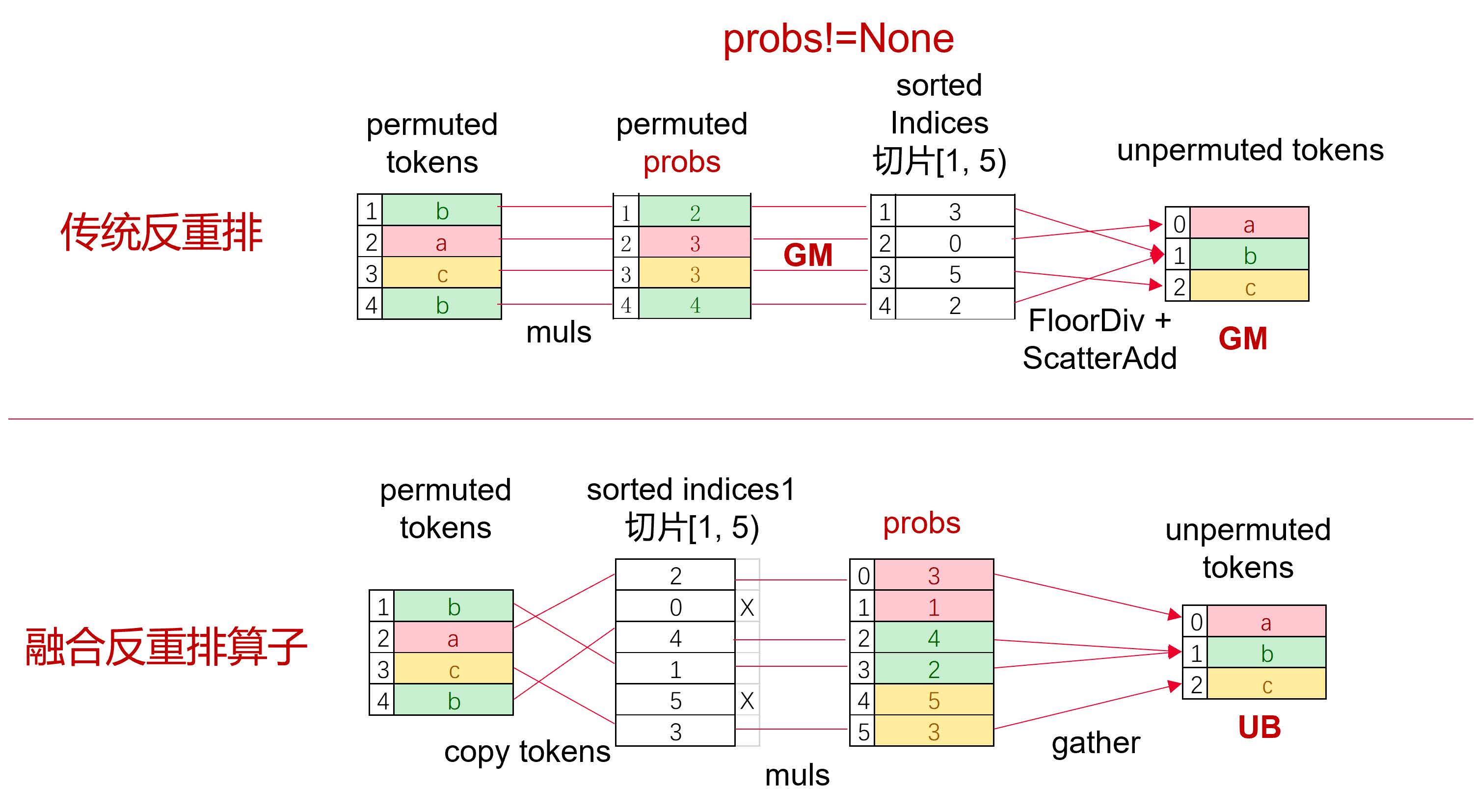
实测表明,在probs非空场景下,MoeTokenUnpermuteWithEP融合算子相较传统反重排方案可实现3.8倍的性能提升,特别是在处理大规模专家网络时优势更为显著。
总体而言,经过深度优化的排序融合算子展现出显著的性能优势:相较于传统串行调用的排序方案,其计算性能实现了近4倍的突破性提升。这一优化成果也可以直接转化到模型训练效率上,使得MoE模型的整体训练吞吐量获得了3-6%的可观提升。
结语
结合MoE架构与昇腾硬件微架构特性的排序算法优化与融合算子设计,不仅能显著提升专家模型的训练效率,更是探索出了稀疏计算与分布式通信领域一条高效可行的技术路径,为MoE模型的规模化训练提供了坚实的技术支撑。
MoeTokenPermuteWithEP及MoeTokenUnpermuteWithEP算子功能通过CANN软件包使能,社区版资源下载地址:
https://www.hiascend.com/developer/download/community/result?module=cann
算子接口定义为:
aclnnStatus aclnnMoeTokenPermuteWithEpGetWorkspaceSize(const aclTensor *tokens, const aclTensor *indices,
const aclTensor *probsOptional, const aclIntArray *rangeOptional, int64_t numOutTokens, bool paddedMode,
const aclTensor *permuteTokensOut, const aclTensor *sortedIndicesOut, const aclTensor *permuteProbsOut,
uint64_t *workspaceSize, aclOpExecutor **executor)
aclnnStatus aclnnMoeTokenPermuteWithEp(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
aclnnStatus aclnnMoeTokenUnpermuteWithEpGetWorkspaceSize(const aclTensor *permutedTokens, const aclTensor *sortedIndices,
const aclTensor *probsOptional, int64_t numTopK, const aclIntArray *rangeOptional, bool paddedMode,
const aclIntArray *restoreShapeOptional, const aclTensor *out, uint64_t *workspaceSize, aclOpExecutor **executor)
aclnnStatus aclnnMoeTokenUnpermuteWithEp(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)详细融合算子接口文档可参考昇腾社区API描述: