



verl支持昇腾,加速大模型RL后训练创新
发表于: 2025/06/28
现如今,深度思考能力已成为模型的必备能力,强化学习已成为激活大模型深度思考的必经之路,昇腾积极拥抱主流生态,支持开源RL训练库verl,包括主流RL算法(如GRPO)和训练推理后端(如FSDP/vLLM)。未来,昇腾将持续发挥其基础软硬件能力优势,进一步扩展对多种主流训练后端、训练加速特性、RL算法及主流模型的适配支持,致力于为用户提供基于昇腾NPU的强大verl强化学习后训练平台,赋能大模型后训练高效开发。
verl支持昇腾特性进展速览
verl已支持昇腾特性
| 推理后端 | vLLM |
| 训练后端 | FSDP |
| 训练算法 | GRPO |
verl支持昇腾运行的模型
| 训练算法 | 支持模型 |
| GRPO | Qwen2.5-0.5B-Instruct Qwen2.5-7B-Instruct Qwen2.5-32B-Instruct Qwen2.5-VL-3B-Instruct Qwen2.5-VL-7B-Instruct Qwen2.5-VL-32B-Instruct |
规划中的特性
| 训练后端 | FSDP2、Megatron-LM对接MindSpeed |
| 训练特性 | 图模式、AsyncVLLM、Multi-Turn Rollout、Split-Train等 |
| 训练算法 | DAPO、PPO等 |
| 模型支持 | Qwen3-8B、Qwen3-32B、Qwen3-30B-A3B、Qwen3-235B-A22B等 |
知识热身——GRPO算法简介
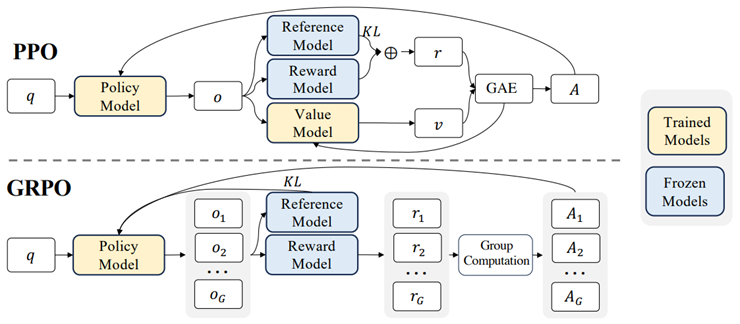
图片来源:https://arxiv.org/pdf/2402.03300
GRPO(Generalized Reinforcement Learning with Policy Optimization)是一种基于策略优化的强化学习算法,相对于PPO(Proximal Policy Optimization)算法,GRPO算法移除了对价值模型(Value Model)作为价值函数近似的依赖,通过奖励模型的一组输出直接计算优势函数,这一过程将参与强化学习训练的Policy Model和Value Model两个模型,减少至Policy Model一个,有效降低了计算和内存的负担。此外还有奖励值的计算逻辑优化,以及KL散度约束方式的优化。该算法随DeepSeek V3的推出而迅速流行。
快速上手——基于verl在昇腾NPU上进行Qwen2.5-0.5B-Instruct GRPO训练
verl现已实现GRPO算法在vLLM+FSDP训推后端在昇腾设备的支持,为了快速体验GRPO强化学习训练,以下展示以Qwen2.5-0.5B-Instruct模型为例的GRPO训练完整操作流程。
环境安装
1、基础环境准备
| 软件名称 | 软件版本 |
| Python | == 3.10 |
| CANN | == 8.1.RC1 |
| torch | == 2.5.1 |
| torch_npu | == 2.5.1.RC1 |
| transformers | >= v4.52.4 |
2、安装vllm
根据不同的设备平台类型(x86/ARM),需要执行不同的安装指令
git clone -b v0.7.3 --depth 1 https://github.com/vllm-project/vllm.git
cd vllm
pip install -r requirements-build.txt# 面向x86平台,执行以下语句
VLLM_TARGET_DEVICE=empty pip install -e . --extra-index https://download.pytorch.org/whl/cpu/# 面向ARM平台,执行以下语句
VLLM_TARGET_DEVICE=empty pip install -e .3、安装vllm-ascend
git clone -b v0.7.3.post1 --depth 1 https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
export COMPILE_CUSTOM_KERNELS=1
python setup.py install3.1.4 安装verl
git clone https://github.com/volcengine/verl.git
cd verl
pip install -r requirements-npu.txt
pip install -e .训练数据准备
以使用开源数据集gsm8k为例,需要先使用verl内置的数据预处理脚本,将其预处理为parquet格式,其中包含GRPO训练所需的必要字段,执行命令如下:
python3 examples/data_preprocess/gsm8k.py --local_dir ~/data/gsm8k开始训练
执行以下脚本启动GRPO算法训练:
set -x
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=$HOME/data/gsm8k/train.parquet \
data.val_files=$HOME/data/gsm8k/test.parquet \
data.train_batch_size=128 \
data.max_prompt_length=512 \
data.max_response_length=128 \
data.filter_overlong_prompts=True \
data.truncation='error' \
actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \
actor_rollout_ref.actor.optim.lr=5e-7 \
actor_rollout_ref.model.use_remove_padding=False \
actor_rollout_ref.actor.entropy_coeff=0.001 \
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=20 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=40 \
actor_rollout_ref.rollout.enable_chunked_prefill=False \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.name=vllm \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=40 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.critic_warmup=0 \
trainer.logger=['console'] \
trainer.project_name='verl_grpo_example_gsm8k' \
trainer.experiment_name='qwen2_7b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=-1 \
trainer.test_freq=5 \
trainer.total_epochs=1 \
trainer.device=npu $@训练效果
可以通过观察训练过程中的reward值曲线趋势来评估训练效果,reward值上升说明强化学习起到了正向作用,可以让模型推理结果更符合目标预期。以下是以Qwen2.5-32B-Instruct模型为例的GRPO强化学习训练的reward曲线,其中蓝色是在昇腾NPU上实验的结果,两者接近表明在昇腾NPU上的训练效果持平业界。
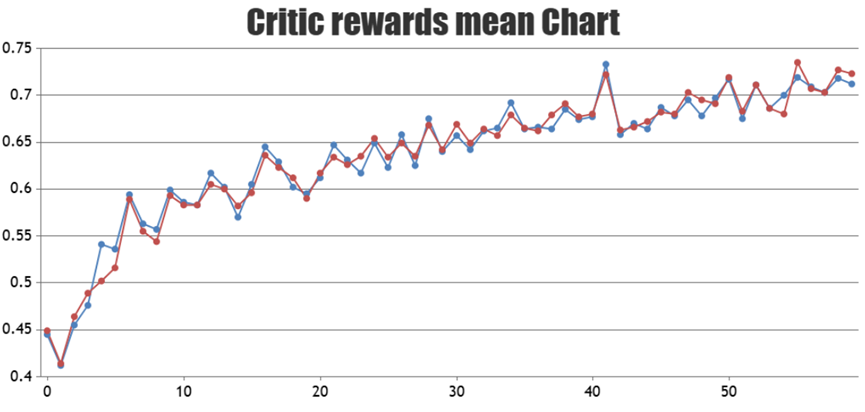
Qwen2.5-32B-Instruct模型的GRPO强化学习训练reward曲线
结语
昇腾团队当前已在verl中实现GRPO算法在vLLM+FSDP训推后端在昇腾设备进行强化学习后训练,欢迎大家快速体验。昇腾将持续推进verl在昇腾设备上支持使用FSDP2、Megatron-LM后端等竞争力特性,欢迎更多开发者一同参与verl支持昇腾能力的构建。
verl官方社区地址:https://github.com/volcengine/verl
verl支持昇腾NPU讨论区:https://github.com/volcengine/verl/discussions/900
verl昇腾快速上手文档:https://github.com/volcengine/verl/blob/main/docs/ascend_tutorial/ascend_quick_start.rst
verl中GRPO RL训练参考脚本(以_npu.sh后缀的文件可在昇腾NPU上使用):https://github.com/volcengine/verl/tree/main/examples/grpo_trainer