



【昇腾热点算子大解密】消除冗余计算,释放硬件潜力,FlashAttention如何在大模型训练提速30%
发表于: 2025/06/25
面向MLA架构的FlashAttention优化挑战
在当下大模型技术的前沿探索中,多头潜在注意力(Multi-Head Latent Attention, MLA)架构凭借其卓越的算效优势和经济性效益,已逐步跻身基座模型设计的标杆方案,这一点在Pangu Ultra MoE-718B以及DeepSeekV3-671B模型的成功实践中得到了有力印证。
为充分发挥MLA架构的潜能,我们对该架构中的关键算子FlashAttention(FA)进行了亲和优化,创新性地提出了Redundancy-Eliminated Cache Tiling FA(RECT-FA)优化策略,从冗余计算消除和流水排布优化两个层面,提升大模型预训练阶段的吞吐性能。
Redundancy-Eliminated Cache Tiling FA(RECT-FA):结合大模型架构特性和昇腾微架构的FA算子优化
基于MLA架构与昇腾硬件特性的深度协同优化,我们创新性地提出了RECT-FA优化方案,在Flash Attention(FA)算子上实现了三项突破性优化技术。如下图所示,该方案能够完全消除原始MLA架构中冗余的Pad、Slice和Concat算子(图中标红部分),从而显著提升计算效率。
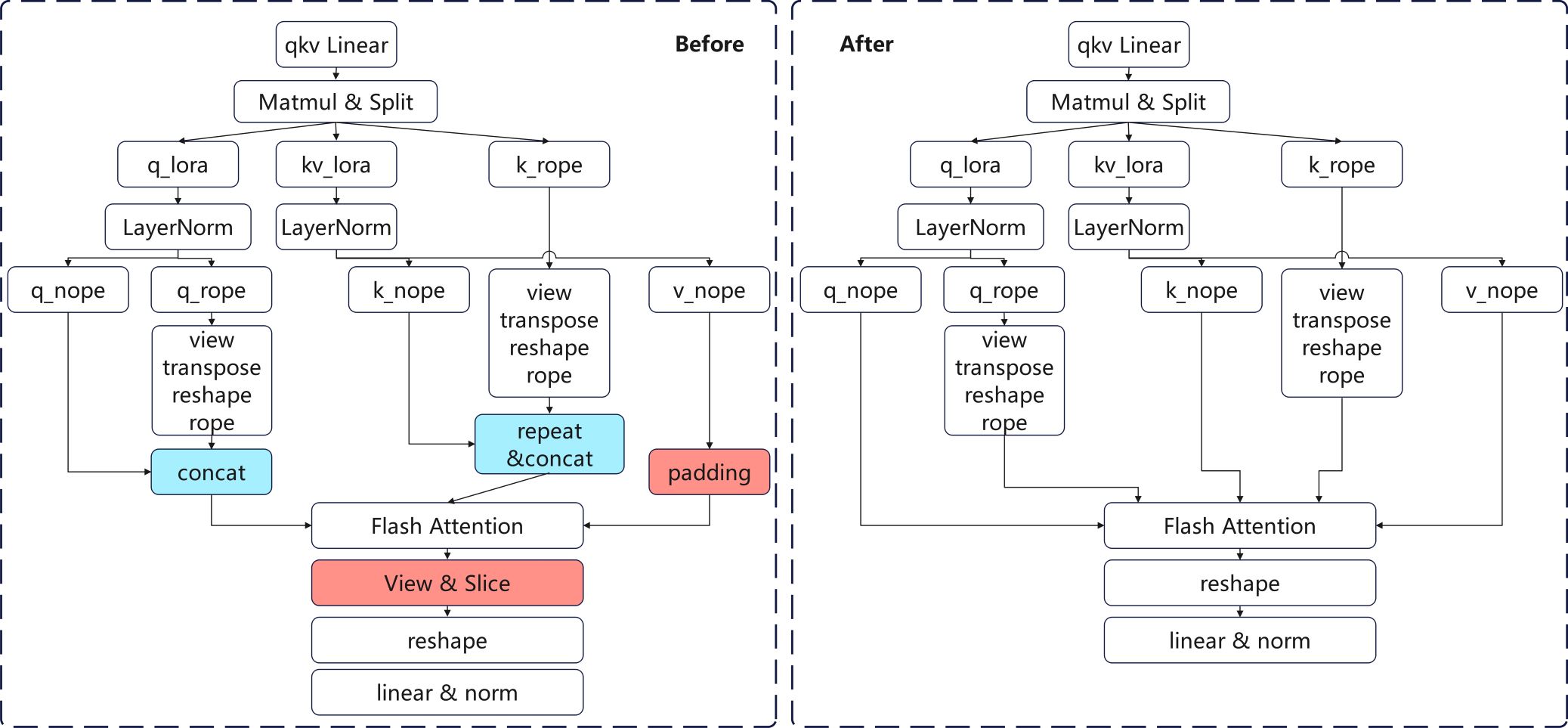
适配昇腾硬件特性,实现MLA架构非对齐计算
首先,FA的标准计算形式可表述为如下公式。其中,d表示注意力头的特征维度(head dim),attention_mask用于表征稀疏注意力掩码,pse、Dropout则分别代表位置编码偏置和随机丢弃两种不同的掩码机制,这些掩码机制在这套优化方案中暂不涉及。
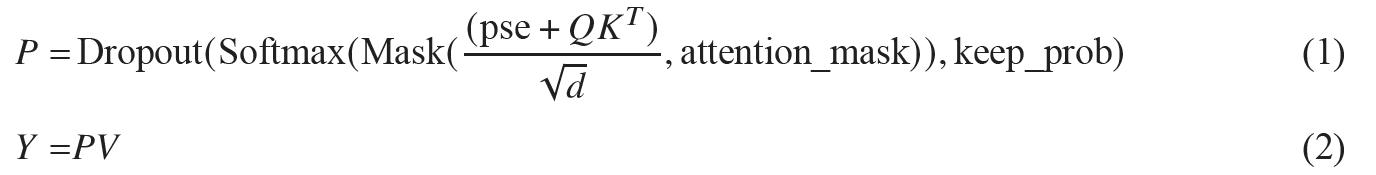
典型的MLA架构中,查询(Q)和键(K)矩阵的头维度统一为D1 = 192,而值(V)矩阵的头维度则为D2 = 128。传统的FA算子要求Q、K、V的头维度必须相等,因此,一种主流的适配方式是显式填充(Padding)的规整化操作,将V的头维度强制扩展至与Q、K对齐(例如将V的head dim从128填充至192),并在完成FA计算后通过切片(Slice)操作截取有效结果区域。这种方法虽然保持了传统FA前反向计算过程的维度规整性,却不可避免地引入了计算开销以及额外的显存占用。
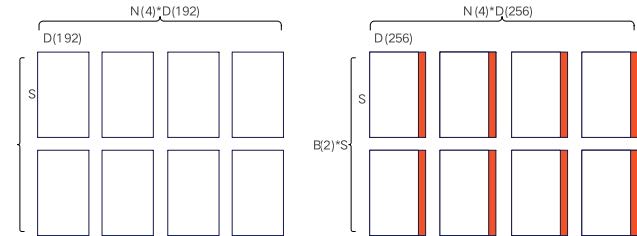
然而,在模型上实际测试发现,这两部分的填充与切片时间很难被有效掩盖。其根本原因在于,大规模的模型计算场景下,FA前反向算子本身的计算负载已经极其庞大,难以通过内存流水排布来掩盖额外操作引入的计算开销。同时,其带来的额外内存占用也不容小觑。
进一步分析FA的计算流程,Q、K的shape分别是(B, N, S1, D1)和(B, N, S2, D1),其中B代表micro batchsize,N代表注意力头数,S1、S2代表序列长度。通过公式(1)可以推导出,中间矩阵P = QK^T的shape为(B, N, S1, S2),而V的shape是(B, N, S2, D2)。结合公式(2),PV矩阵乘本质上并不依赖D1与D2的完全相等,即理论上可以支持D维度非对齐。
基于这一发现,我们重构了FA算子内核,消除填充带来的冗余计算,创新性地实现了对非对齐维度的直接支持。相比之下,在当前昇腾硬件架构中,128一值恰好与缓存行完美对齐,使得数据搬运效率进一步提升。基于这一硬件特性,直接采用V的原始维度D2 = 128进行非对齐计算,相比传统的规整化填充方案能展现出明显的性能优势,也直接降低了内存访问开销。
实际测试数据表明,在Pangu Ultra MoE-718B模型中,该优化方案使FA融合算子的前向计算性能提升达30%,反向性能亦提升20%,非对齐计算策略的有效性得到了充分验证。在DeepSeekV3-671B模型中,在昇腾A3服务器上整网验证更是直接带来了4.8%的性能提升,优化约4G的动态内存开销。
启用Matmul原位累加,消除RoPE/NoPE拼接开销
FA算法本身缺乏对输入序列顺序的感知能力,因此需要借助位置编码(Positional Encoding)来注入位置信息。如前述的MLA架构示意图所示,该架构在处理旋转位置编码(RoPE)时采用了创新性的解耦式设计,巧妙实现了低秩压缩与位置感知的兼容。这一独特设计虽然带来了显著的计算效率提升,但也不可避免地引入了对位置编码的拼接(Concat)操作,因此成为架构优化中的关键一环。
通过对大模型中算子计算耗时的采样分析,我们观察到Concat操作计算耗时显著。以Pangu Ultra MoE-718B模型为例,MLA模块的整体计算时间为5.2ms,而其中仅Concat操作就消耗了0.7ms,占比整整13.5%。若能消除这一拼接步骤,将为模型性能带来相当可观的优化收益。
在MLA架构的实际实现中,QK^T矩阵乘可以被分解为两个部分,QnopeKnope^T与QropeKrope^T。而Concat这一步做的就是,将Qnope、Qrope拼接为Q,以及将Knope、Krope拼接为K。那么如果直接把Qnope、Qrope、Knope、Krope共同作为FA的输入参数,在FA算子内部进行运算,就无需在外部做Concat操作。不过,这样也会引入新的挑战,当原本的单一矩阵乘被拆分为两个矩阵乘运算,就意味着会需要同时存储两个相同大小的中间结果矩阵,从而不可避免地导致额外的内存开销。
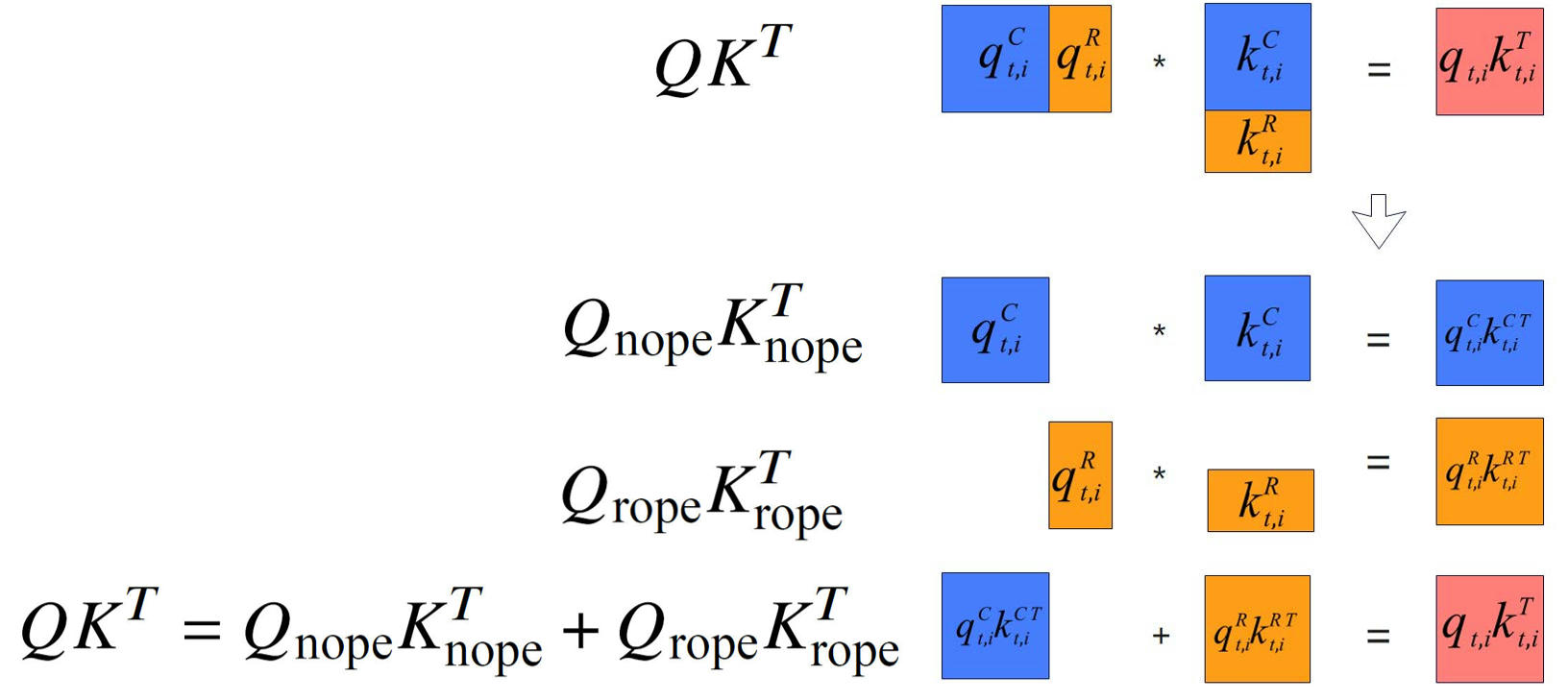
因此,在进行第二次矩阵乘操作QropeKrope^T时,我们巧妙启用了Matmul高阶API的原位累加特性,这样QropeKrope^T的结果就可以直接累加到QnopeKnope^T上,实现了内存空间的高效复用。针对Pangu Ultra MoE-718B的模型场景,在昇腾A2服务器上FA单算子的性能提升了20.5%。
自主管理L1缓存,优化计算流水排布
Cube核的MTE2搬运单元负责GM到L1缓存的数据传输。分析FA算子流水图发现,当前MTE2搬运存在等待间隙,必须等Cube计算单元完成当前计算才能进行下一轮MTE2搬运。其根本原因是,现有实现中,MTE2搬运完全依赖矩阵运算高阶API IterateAll()内部处理,算子代码中并没有额外对MTE2搬运环节进行干预。
由此,为最大化计算并行度,我们在FA算子中创新性地实现了MTE2自主搬运机制,与原有IterateAll()的MTE1搬运功能协同运作,构建了“自主MTE2搬运+高阶API MTE1搬运”的混合架构。这一优化方案有效减少了MTE2搬运环节的等待间隙,在部分计算场景下甚至能完全消除间隙阻塞,显著提升了整体计算效率。
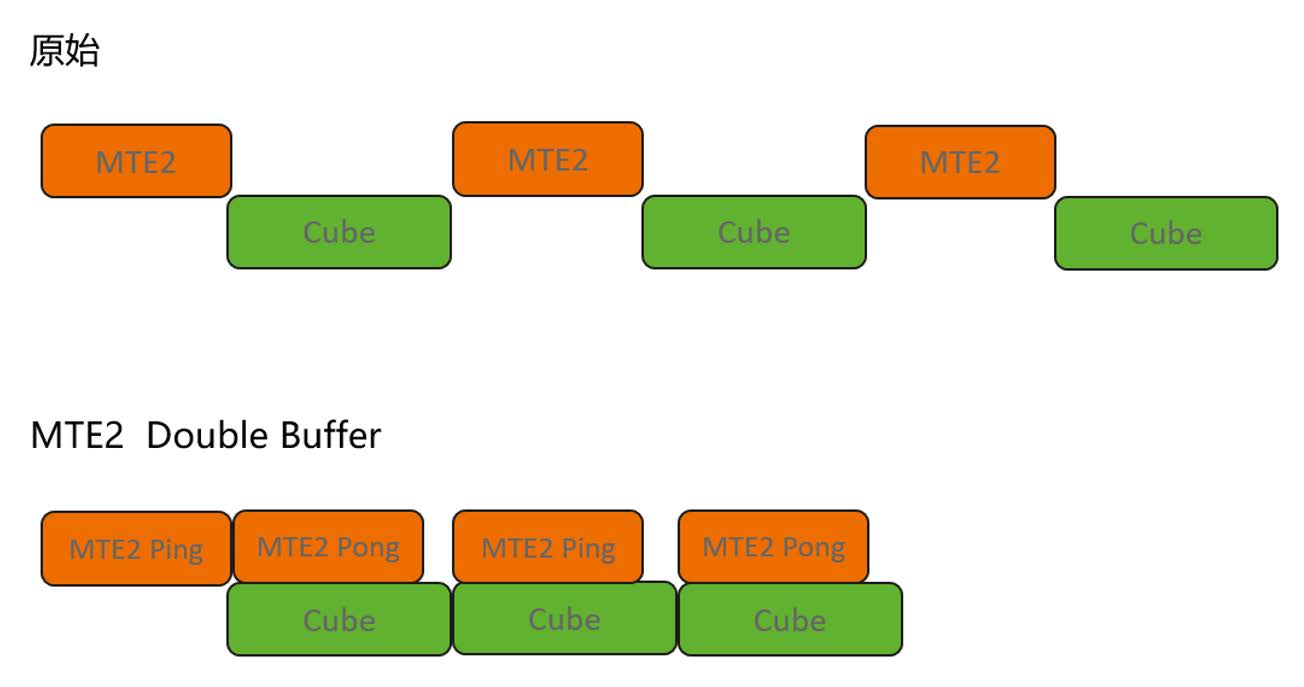
然而,仅仅实现MTE2自主搬运还是无法完全消除计算间隙。为进一步压缩间隙阻塞,我们采用了双缓存架构,在L1缓存中为Matmul计算的A/B矩阵块分别配置了双存储区域,即图中的Ping和Pong。通过两块存储区域的交替使能,系统在执行当前Cube运算的同时,MTE2单元可并行将下一轮计算数据预载入另一块备用缓存区。这种双缓冲设计实现了计算与数据搬运的完全并行化,使MTE2流水线效率进一步提升。
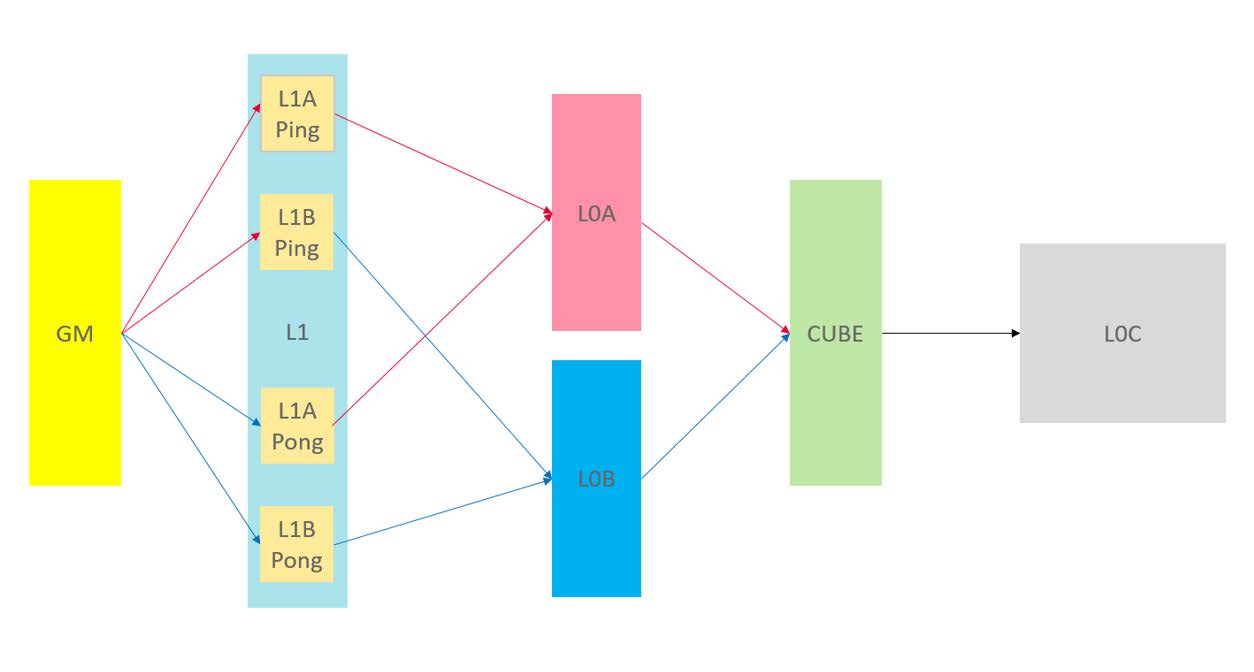
优化后的流水线成功消除了MTE2搬运间隙,有效降低了数据阻塞。基于Pangu Ultra MoE-718B模型实测,该方案使FA算子执行耗时平均减少8%,大幅提升了计算吞吐量。
结语
随着大模型规模持续扩大与应用场景不断深化,计算效率的提升已逐步成为推动AI发展的关键引擎。RECT-FA在MLA架构上的成功实践,不仅验证了软硬件协同优化的巨大潜力,更展现了一条通过算子级创新突破系统瓶颈的技术路径。
FlashAttention算子功能通过CANN软件包使能,社区版资源下载地址:
https://www.hiascend.com/developer/download/community/result?module=cann
算子接口定义为:
aclnnStatus aclnnFlashAttentionScoreGetWorkspaceSize(const aclTensor *query, const aclTensor *key, const aclTensor *value,
const aclTensor *realShiftOptional, const aclTensor *dropMaskOptional, const aclTensor *paddingMaskOptional,
const aclTensor *attenMaskOptional, const aclIntArray *prefixOptional, double scaleValue, double keepProb,
int64_t preTokens, int64_t nextTokens, int64_t headNum, char *inputLayout, int64_t innerPrecise, int64_t sparseMode,
const aclTensor *softmaxMaxOut, const aclTensor *softmaxSumOut, const aclTensor *softmaxOutOut, const aclTensor *attentionOutOut,
uint64_t *workspaceSize, aclOpExecutor **executor)
aclnnStatus aclnnFlashAttentionScore(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, const aclrtStream stream)详细接口文档可参考昇腾社区API描述: