



【CANN全新升级】CANN创新MLAPO算子,DeepSeek模型推理效率倍增
发表于: 2025/05/26
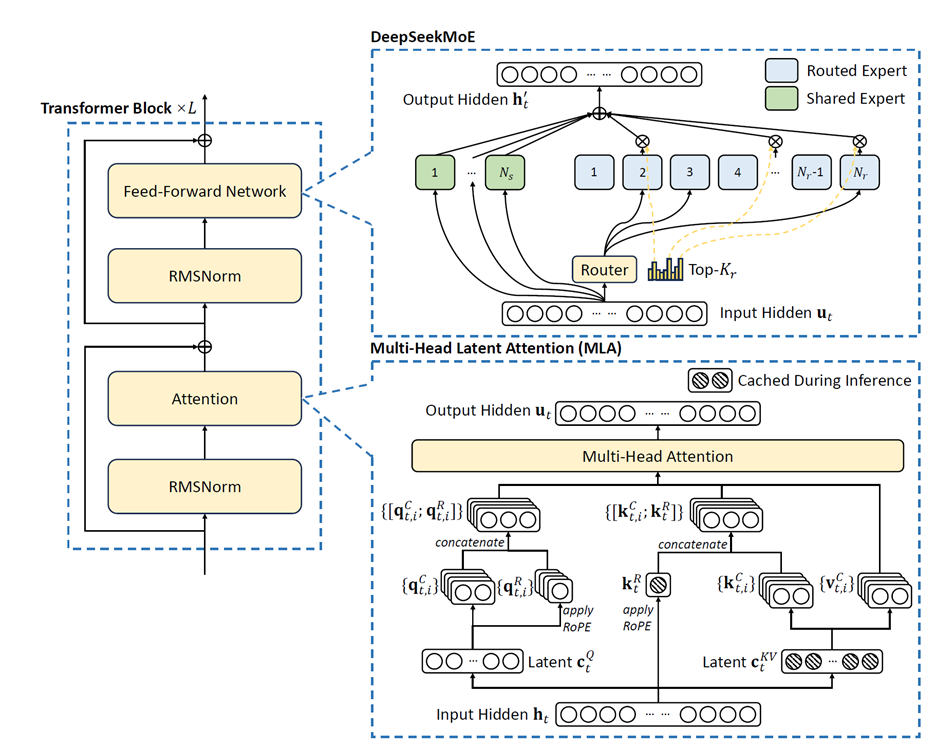
MoE模型中的MLA架构
DeepSeek系列模型凭借其创新性的MLA(Multi-Head Latent Attention)架构,替代了传统的MHA(Multi Head Attention),显著降低了推理时的KV Cache开销,大幅提升了推理效率,使其能够更好地适应长上下文任务并提高推理准确性。MLA的成功应用不仅推动了DeepSeek系列模型自身的技术突破,其低成本和高效率的特点也为AI行业的普及和转型提供了重要支持。
创新MLAPO算子,加速MLA前处理,提升DeepSeek系列模型性能
早在2024年5月DeepSeekV2发布时,昇腾CANN针对MLA架构进行了深度适配优化,经过2个月的开发,率先完成PagedAttention算子对DeepSeek系列模型的适配,实现了高效支持。随着DeepSeek系列模型的持续演进,昇腾也在不断探索推理预处理阶段中MLA的计算加速技术,通过VV融合(多个Vector算子融合),进一步提升MLA预处理阶段的计算效率。
MLA的预处理阶段,以DeepSeekV3-671B为例,其模型结构如下图所示:
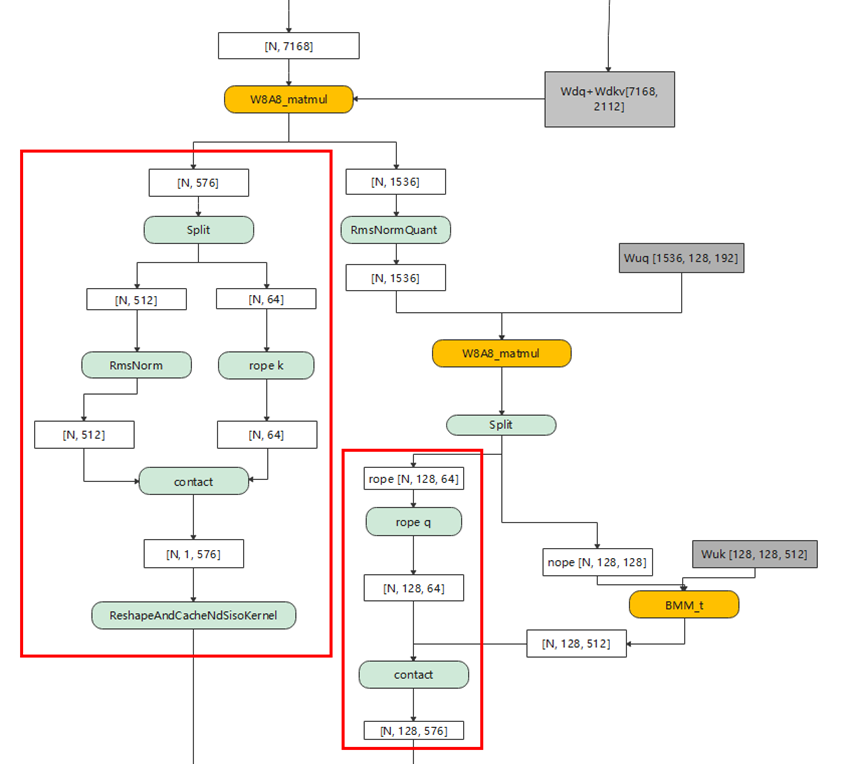
初始token的HiddenSize为7K,首先Q和KV会经由两个降维矩阵分别完成降维,降维后Q的HiddenSize为1536,KV为576。Q在经过RmsNorm后,进入Q升维矩阵做矩阵乘,升维后每个token变为128个Head,每个Head的HeadDim为192。
接下来,Q与KV会分别将每个Head切分成64+128和64+512,其中64均进入Rope,K的另一半进入RmsNorm,Q的另一半则进入K升维矩阵做矩阵乘。最后,Q和KV分别把各自的Head合并,输出结果给MLA使用。
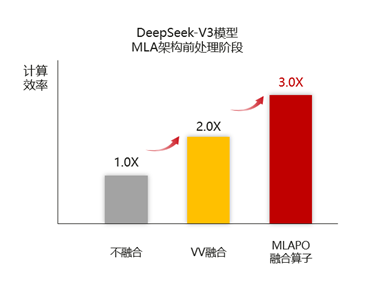
在融合算子技术设计中,VV融合是最为高效快捷的融合开发方式。如上图红框所示,通过将MLA预处理两部分计算流分别融合成2个融合算子,可以实现融合算子性能直接翻倍。将这两个融合预处理小算子实现后,当前在DeepSeekV3整网中已取得了5%+的计算性能提升。
而为了针对DeepSeekV3模型场景进一步提升性能,昇腾CANN选择将前处理过程中的13个小算子直接融合成一个超级大算子MLAPO(MlaPreprocessOperation)。
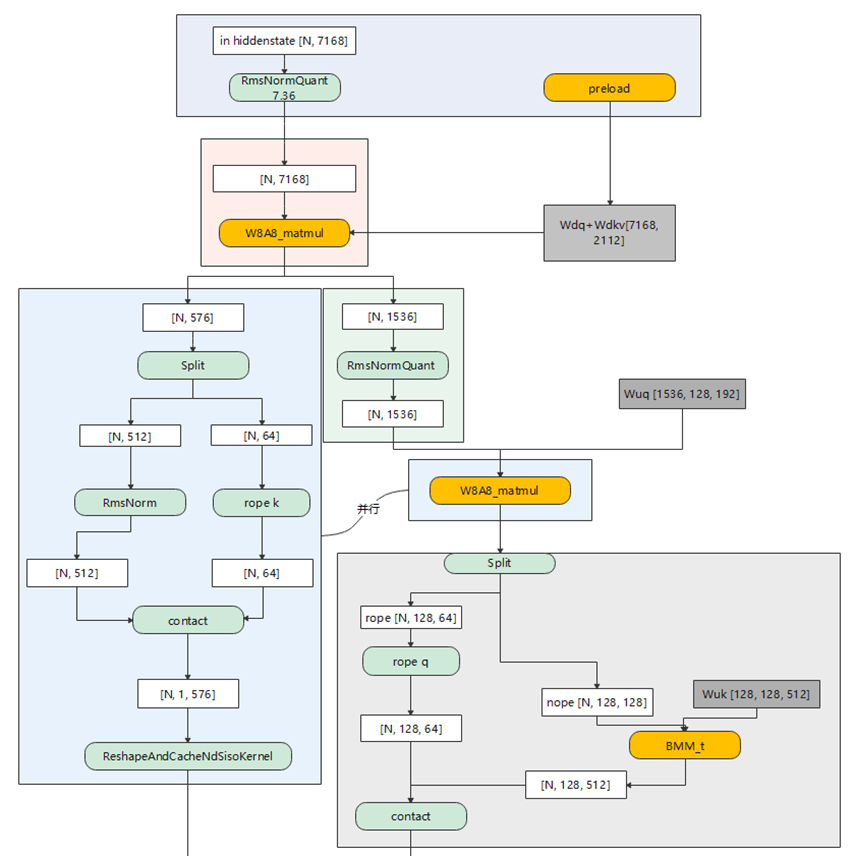
MLAPO算子的完整流程可以分为以下几个步骤:
1. RmsNorm/Preload并行
2. Q+KV的降维Matmul
3. Q的RmsNorm
4. Q的升维Matmul/KV Rope&RmsNorm&ReshapeandCache并行
5. K的升维Matmul/Q Rope并行
在计算时,通过对Vector和Cube计算单元的并行处理及流水优化,基本可以将用时较短的Vector耗时完全掩盖,进一步缩短MLA前处理的时延。实现MLA预处理算子MLAPO融合后,小算子的头开销和下发开销基本可以消除。这种大融合算子能够在VV融合的基础上,实现算子性能的再次翻倍。当前在大参数DeepSeekV3模型的量化场景下,MLAPO算子的实现将计算耗时从109us缩减为45us,带来整网性能提升20%+。
DeepSeekV3火爆全球的同时,针对DeepSeek系列模型的计算优化思路也在不断探索泛化中,从小融合到大融合,多流水并行以及未来更高自由度的量化方式,昇腾也将持续探索更多可能,以工程创新释放更强算力。
MLAPO算子使能指南
以上优化特性已在昇腾CANN最新版本中实现,CANN包安装过程可参考社区文档:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/81RC1alpha001/softwareinst/instg/instg_0000.html?Mode=PmIns&OS=Ubuntu&Software=cannToolKit
./Ascend-cann-toolkit_<version>_linux-<arch>.run --installsource ${HOME}/Ascend/ascend-toolkit/set_env.sh
CANN包安装并通过环境变量使能后,可以通过调用MlaPreprocessOperation算子接口使能MLAPO算子,参考示例见下。
int main(int argc, char **argv)
{
std::string dtypeStr;
int tokenNum = 4;
int headNum = 128;
aclDataType dtype = ACL_FLOAT16;
if (argc == 4) {
dtypeStr = argv[1];
tokenNum = std::stoi(argv[2]);
headNum = std::stoi(argv[3]);
}
if (dtypeStr == "bf16") {
dtype = ACL_BF16;
}
// 设置卡号、创建context、设置stream
atb::Context *context = nullptr;
void *stream = nullptr;
CHECK_STATUS(aclInit(nullptr));
CHECK_STATUS(aclrtSetDevice(DEVICE_ID));
CHECK_STATUS(atb::CreateContext(&context));
CHECK_STATUS(aclrtCreateStream(&stream));
context->SetExecuteStream(stream);
// 创建op
atb::Operation *mlaPreprocessOp = CreateMlaPreprocessOperation();
// 准备输入tensor
atb::VariantPack variantPack;
variantPack.inTensors = PrepareInTensor(context, stream, dtype, tokenNum, headNum); // 放入输入tensor
// 准备输出tensor
atb::Tensor qOut0 = CreateTensor(ACL_INT8, aclFormat::ACL_FORMAT_ND, {tokenNum,headNum,512});
atb::Tensor &kvCacheOut0 = variantPack.inTensors.at(19);
atb::Tensor qOut1 = CreateTensor(dtype, aclFormat::ACL_FORMAT_ND, {tokenNum,headNum,64});
atb::Tensor &kvCacheOut1 = variantPack.inTensors.at(20);
variantPack.outTensors = {qOut0, kvCacheOut0, qOut1, kvCacheOut1}; // 放入输出tensor
uint64_t workspaceSize = 0;
// 计算workspaceSize大小
CHECK_STATUS(mlaPreprocessOp->Setup(variantPack, workspaceSize, context));
uint8_t *workspacePtr = nullptr;
if (workspaceSize > 0) {
CHECK_STATUS(aclrtMalloc((void **)(&workspacePtr), workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST));
}
for (size_t i = 0; i < 10; i++){
std::cout << "tokenNum: " << tokenNum << " headNum: " << headNum << " loop: " << i << std::endl;
// mlaPreprocess执行
mlaPreprocessOp->Execute(variantPack, workspacePtr, workspaceSize, context);
CHECK_STATUS(aclrtSynchronizeStream(stream)); // 流同步,等待device侧任务计算完成
}
// 释放资源
for (atb::Tensor &inTensor : variantPack.inTensors) {
CHECK_STATUS(aclrtFree(inTensor.deviceData));
for (atb::Tensor &outTensor : variantPack.outTensors) {
if (outTensor.deviceData == inTensor.deviceData) {
outTensor.deviceData = nullptr;
}
}
inTensor.deviceData = nullptr;
}
for (atb::Tensor &outTensor : variantPack.outTensors) {
if (outTensor.deviceData == nullptr) continue;
CHECK_STATUS(aclrtFree(outTensor.deviceData));
}
if (workspaceSize > 0) {
CHECK_STATUS(aclrtFree(workspacePtr));
}
CHECK_STATUS(atb::DestroyOperation(mlaPreprocessOp)); // operation,对象概念,先释放
CHECK_STATUS(aclrtDestroyStream(stream));
CHECK_STATUS(DestroyContext(context)); // context,全局资源,后释放
CHECK_STATUS(aclFinalize());
std::cout << "MlaPreprocess demo success!" << std::endl;
return 0;
}更多学习内容,可参考ATB算子代码开源仓:
https://gitcode.com/cann/ascend-transformer-boost