



昇腾多模态SDK视频总结问答应用开发实践
发表于: 2025/05/16
1 简介
多模态SDK视频总结问答应用基于多模态SDK和推理微服务所构建。使用昇腾丰富的微服务及其快速部署能力,我们可以快速便捷地部署不同模型的微服务来处理视频、文本等内容,避免了以往复杂的依赖安装和性能调优,并且可以通过模型镜像来快速替换微服务。通过优化配置可实现高吞吐量、低延迟及默认性能模式的灵活切换,确保在不同应用场景下都能达到最佳性能表现。从昇腾社区镜像仓库下载相应的推理微服务镜像,即可快速部署推理微服务。
本应用基于Atlas 800I A2推理产品硬件平台,使用3个模型推理微服务(视图分析与理解推理微服务、文本总结与对话推理微服务、数据向量化推理微服务),加上多模态视频总结问答应用微服务,实现了总结问答应用的demo。其中,多模态视频总结问答应用微服务集成了多模态SDK、RAG SDK,其中也包含了预置的网页应用文件,实现了一站式部署。
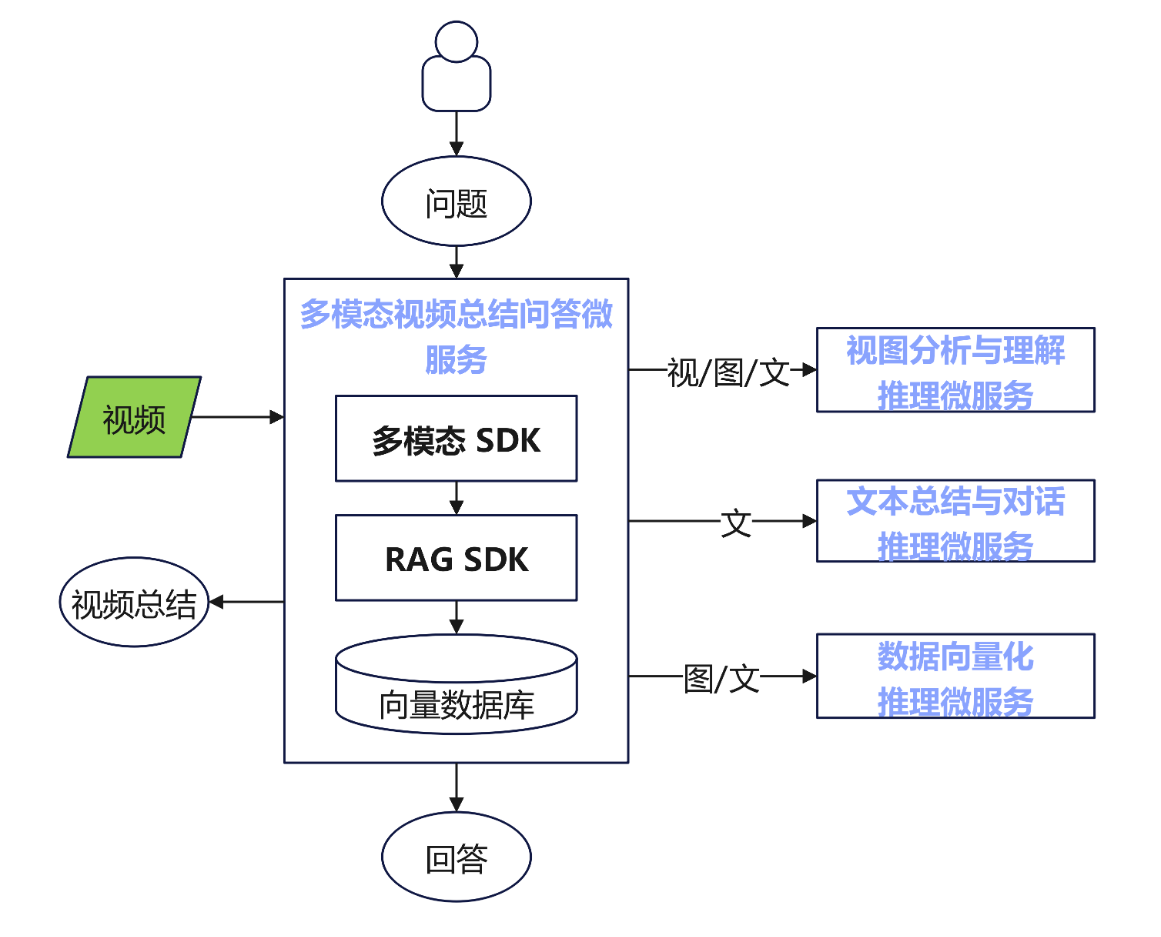
多模态视频总结问答应用框架图
| 微服务名 | 功能简介 |
|---|---|
| 多模态视频总结问答应用微服务 | 应用微服务内包含了多模态SDK、RAG SDK、以及网页端服务脚本;多模态SDK是多模态视频总结问答应用的核心组件,它提供了智能分块、关键帧抽取、特征压缩等原子能力以剔除冗余数据,并提供了昇腾亲和的硬件解码、视频预处理等加速能力,使得开发者构建出性能更优的多模态应用。RAG SDK提供的知识检索召回加速能力用于高效、准确的提取高相似度的知识片段,便于后续进行问答对话。网页端服务脚本调用了这些能力。 |
| 视图分析与理解推理微服务 | 视图分析与理解的智能服务。为开发者提供RESTful API接口以高效处理和分析视觉数据,提供精准的视图理解能力。 |
| 文本总结与对话推理微服务 | 文本总结与对话的智能服务。为开发者提供RESTful API接口以高效地处理和生成自然语言文本,提供精准的文本总结和对话能力。 |
| 数据向量化推理微服务 | 数据向量化的智能服务。为开发者提供RESTful API接口将多模态数据转换为向量表示,构建向量数据库基础。 |
2 支持的产品和版本
| 产品 | CANN 版本 | 多模态SDK版本 | RAG SDK版本 | 系统推荐 |
|---|---|---|---|---|
| Atlas 800I A2 | 8.0.0 | 7.1.T5 | 7.0.T15 | Ubuntu 20.04.6 |
3 NPU分配
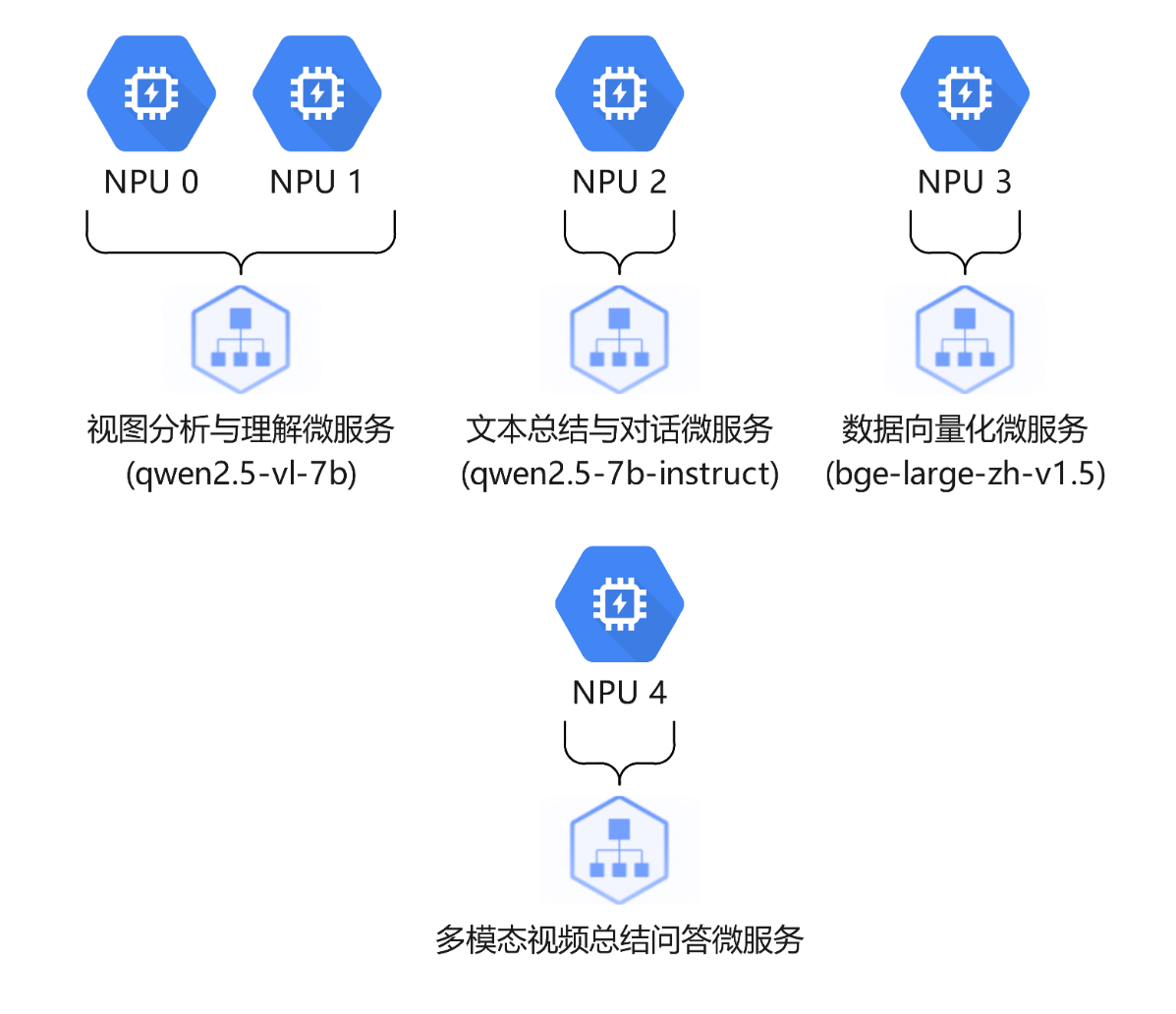
4 快速部署
步骤1:下载微服务容器镜像;
步骤2:启动推理微服务容器、多模态SDK容器;
步骤3:配置微服务API启动多模态应用,体验视频总结问答;
4.1 下载微服务镜像
推理微服务是构建多模态视频总结问答应用的关键组件。可快速便捷的部署不同模型的微服务来处理视频、文本等内容,避免了以往复杂的依赖安装和性能调优,并且可以通过模型镜像来快速替换微服务。通过优化配置可实现高吞吐量、低延迟及默认性能模式的灵活切换,确保在不同应用场景下都能达到最佳性能表现。
从昇腾社区镜像仓库下载相应的推理微服务镜像,即可快速部署推理微服务。
下载镜像列表
以下为本demo需要用到的镜像列表;打开对应昇腾社区链接,切到镜像版本,点击下载按钮后,按提示复制拉取命令,按步骤依次执行即可下载镜像。
检查镜像加载情况
docker images4.2 启动3个推理微服务容器、多模态视频总结问答应用微服务容器
推理微服务允许用户选择vLLM与MindIE推理引擎并根据性能需求(高吞吐、低时延或默认)配置推理引擎。更多详情请参考各镜像模型的镜像概述。
(1)启动视图分析与理解推理微服务
# 设置本地缓存路径
export LOCAL_CACHE_PATH=/home/models
# 设置容器名称
export CONTAINER_NAME=qwen2.5-vl-7b-instruct
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/qwen2.5-vl-7b-instruct:7.1.T2-800I-A2-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=0,1 \
-e MIS_CONFIG=atlas800ia2-2x32gb-bf16-vllm-default \
-e MIS_LIMIT_VIDEO_PER_PROMPT=1 \
-e MIS_LOG_LEVEL=CRITICAL \
-e TRANSFORMERS_VERBOSITY=error \
-e PYTHONWARNINGS=ignore \
-e TORCH_NPU_DISABLED_WARNING=1 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
-p 8000:8000 \
--shm-size 1gb \
$IMG_NAME
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}(2)启动文本总结与对话推理微服务
# 设置本地缓存路径
export LOCAL_CACHE_PATH=/home/models
# 设置容器名称
export CONTAINER_NAME=qwen2.5-7b-instruct
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/qwen2.5-7b-instruct:7.1.T2-800I-A2-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=2 \
-e MIS_CONFIG=atlas800ia2-1x32gb-bf16-vllm-default \
-e MIS_LOG_LEVEL=CRITICAL \
-e PYTHONWARNINGS=ignore \
-e TORCH_NPU_DISABLED_WARNING=1 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
-p 8001:8000 \
--shm-size 1gb \
$IMG_NAME
# 查看推理容器日志
docker logs -f ${CONTAINER_NAME}(3)启动数据向量化推理微服务
# 设置本地缓存路径
export LOCAL_CACHE_PATH=/home/models
# 设置容器IP与端口
export MIS_EMB_HOST=0.0.0.0
export MIS_EMB_PORT=8003
# 设置容器名称
export CONTAINER_NAME=bge-large-zh-v1.5
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/bge-large-zh-v1.5:7.1.T2-800I-A2-aarch64
# 启动推理微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -itd \
-p $MIS_EMB_PORT:9091 \
--name=$CONTAINER_NAME \
-e ASCEND_VISIBLE_DEVICES=3 \
-e MIS_LOG_LEVEL=CRITICAL \
-e PYTHONWARNINGS=ignore \
-e TORCH_NPU_DISABLED_WARNING=1 \
-v $LOCAL_CACHE_PATH:/opt/mis/.cache \
$IMG_NAME $MIS_EMB_HOST 9091
docker logs -f $CONTAINER_NAME确认推理微服务启动状态
执行启动命令后,在对应的微服务启动界面显示如下内容则表示启动成功:
Application startup complete(4)启动并进入多模态视频总结问答应用微服务容器
# 设置容器名称
export CONTAINER_NAME=multimodalsdk
# 选择镜像
export IMG_NAME=swr.cn-south-1.myhuaweicloud.com/ascendhub/multimodalsdk:7.1.T5-800I-A2-aarch64
# 启动应用微服务,使用ASCEND_VISIBLE_DEVICES选择卡号,范围[0,7]
docker run -it --network=host -u HwHiAiUser --name=$CONTAINER_NAME -e ASCEND_VISIBLE_DEVICES=4 $IMG_NAME bash如需关闭对应的推理微服务,执行如下命令即可:
docker stop $CONTAINER_NAME4.3 配置微服务API启动多模态应用,体验视频总结问答
运行如下命令配置微服务API,并启动多模态应用:
# llm_url、embed_url和vlm_url 对应上述启动的3个推理微服务
mx_video_sqa \
--port ${APP_PORT} \
--mis_enable True \
--llm_url http://${LLM_MIRCO_SERVICE_IP}:8001/openai/v1/chat/completions \
--embed_url http://${EMB_MIRCO_SERVICE_IP}:8003/embed \
--vlm_url http://${VLM_MIRCO_SERVICE_IP}:8000/openai/v1| 参数 | 参数含义 |
|---|---|
| mis_enable | 使用推理微服务功能,需默认开启 |
| APP_PORT | 应用的启动端口 |
| LLM_MIRCO_SERVICE_IP | 文本总结与对话微服务的机器IP |
| EMB_MIRCO_SERVICE_IP | 数据向量化微服务的机器IP |
| VLM_MIRCO_SERVICE_IP | 视图分析与理解微服务的机器IP |
确认应用启动状态
执行启动命令后,启动界面显示如下内容则表示服务启动成功:
Multimodal application Server is loading.
Running on local URL: http://0.0.0.0:${APP_PORT}使用基于Gradio的UI界面体验视频总结问答应用
1 打开网页,输入启动应用的服务器IP和端口号的组合
http://${MULTIMODAL_VIDEO_SQA_APP_IP}:${APP_PORT}| 参数 | 参数含义 |
|---|---|
| MULTIMODAL_VIDEO_SQA_APP_IP | 多模态视频总结问答应用微服务的机器IP |
即可看到如下页面:
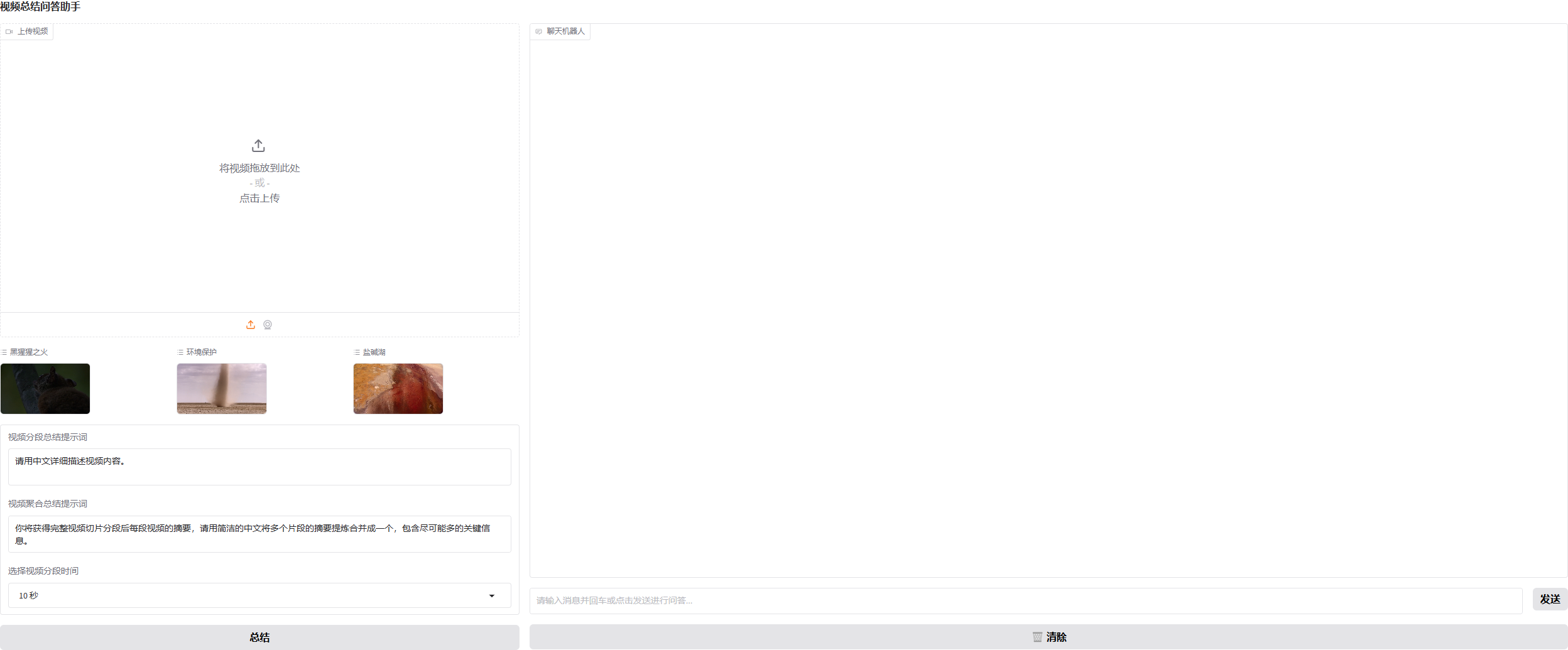
2 点击左上角上传视频框上传待处理视频/点击预置视频
3 根据具体应用场景修改视频分段总结、聚合总结提示词,选择合适的视频分段时间
4 点击"总结“按钮,右侧总结问答界面会输出分段后每一段视频的总结内容,并最终会对分段内容进行聚合总结
5 当出现"本轮总结已结束,请继续进行问答或新的总结!"表示当前总结已完成
6 待视频总结完成后,可输入相关问题对话,以进一步深入理解视频,并提供一定的指导、预测、警示价值。