



【昇腾大规模专家并行技术解码】PD分离,让推理性能再提速30%!
发表于: 2025/04/23
随着大语言模型(LLM)的快速发展,提升用户体验、增加吞吐和并发成为关键。昇腾推出大规模专家并行推理方案,通过优化专家分布、通信计算加速,将单卡吞吐提升了3倍以上。然而,LLM的Prefill和Decode阶段“混合部署”在吞吐和时延上仍存在瓶颈,针对这一问题,昇腾使用PD分离技术,进一步将吞吐量提升了30%以上,取得性能&效率的双提升。
大模型推理的趋势和挑战
生成式人工智能的核心 —— 大规模语言模型推理,其推理过程通常分为两个阶段:Prefill阶段和Decode阶段。Prefill阶段负责处理用户的输入生成初始KV缓存,并生成第一个Token(字),而Decode阶段则负责后续Token的生成。如下图:

文本经过Prefill计算和Decode解码
一方面,随着AI大模型的发展,数百GB模型权重文件、千亿参数模型更加常见。在“尝鲜”时,数百GB的MoE模型加载使推理效率降低,因此,通过集群化部署,将MoE模型专家拆分到多张NPU卡上进行专家并行(EP)成为趋势。
另一方面,在传统部署方案中,Prefill和Decode这两个阶段往往运行在同一个计算节点上,导致传统部署方案存在如下问题:
1.PD时延互相干扰:Prefill和Decode阶段互相等待,用户需要增加等待时延,为了保证用户体验(时延小于100ms),必须牺牲并发,降低吞吐率。
2.计算与访存冲突:Prefill阶段是计算密集型任务,Decode阶段是访存密集型任务,混合在同一节点上的运行,会导致算力和显存资源的竞争冲突。
3.资源利用不足:两阶段硬件需求差异较大,为保证效果需要算力、显存资源过配置,混合部署难以充分利用资源,存在资源利用不足的问题。
昇腾大规模专家并行+PD分离结合方案
1. 昇腾大规模专家并行方案
本方案是将数百个专家(Expert)离散地分布到更多的卡上。

大规模专家并行专家分配示意图
这个方案可以做到:
1.权重加载更快:每张卡只需要加载部分专家权重,整体时延降低;
2.并行路数更多:单卡专家少,空闲显存更多,显著提升并行的路数;
3.资源利用率更高:专家可以充分利用单卡上的资源,整体提高效率;
因此,大规模专家并行方案可以实现更大的吞吐和更低的时延。
2. 昇腾PD实例分离方案
结合大规模专家并行方案,昇腾进一步通过MindIE推理引擎的调度,将Prefill和Decode阶段分别部署到不同的服务器上,分别作为P实例和D实例:

将服务器做PD实例分离示意图
通过PD分离,可以达到:
1.消除PD间时延干扰:Decode可以使用更大的BatchSize,计算效率更高。
2.PD灵活配比调节:可以根据PD需要的计算资源,独立地调整资源的比例,资源利用更充分。
3.PD资源解耦: P实例和D实例使用不同的硬件资源,避免资源的冲突。
快速部署
1. 环境准备
I 硬件需求:
以16台昇腾服务器为例,8台组成4个P实例,8台作为1个D实例。服务器需具备高算力和大显存(推荐使用昇腾Atlas 800系列)。同时,确保服务器之间网络带宽充足(建议200Gbps或以上)。
I 软件环境:
1.安装k8s环境;
2.集群节点安装MindCluster调度组件;
3.安装MindIE镜像,支持大规模专家并行调度、PD分离功能。
I 准备权重:
可从“魔乐社区”准备DeepSeek-R1 INT8量化版模型权重文件。
2.配置和启动服务
I 准备配置文件
从“昇腾社区”获取最新版本的MindIE软件包文件Ascend-mindie_2.0.RC1_linux-aarch64.run,拷贝到Linux本地,并执行如下命令:
chmod +x Ascend-mindie_2.0.RC1_linux-aarch64.run./Ascend-mindie_2.0.RC1_linux-aarch64.run --extract=mindie/mindie/Ascend-mindie-service_2.0.RC1_py311_linux-aarch64.run--extract=mindie-servicecd mindie-service/examples/kubernetes_deploy_scriptscp ../../conf/config.json ./conf/config_p.jsoncp ../../conf/config.json ./conf/config_d.jsoncp ../../conf/http_client_ctl.json ./confcp ../../conf/ms_controller.json ./confcp ../../conf/ms_coordinator.json ./conf
根据业务需求,执行命令修改当前目录下的配置文件“user_config.json”
vim user_config.jsonI PD分离部署参数配置:
设置 Prefill 和 Decode 阶段的实例数量 ,保持两者处理速度匹配,如下配置为4个Prefill实例,每个实例2台服务器,1个Decode实例,每个实例8台服务器。
"p_instances_num": 4, // 配置4个Prefill实例"d_instances_num": 1, // 配置2个Decode实例"single_p_instance_pod_num": 2, // 单个Prefill实例使用2个服务器"single_d_instance_pod_num": 8, // 单个Decode实例使用8个服务器
可根据实际业务负载,调整实例数量和实例服务器配置。
I 大规模专家并行部署配置:
将模型拆分为多个 Expert 实例,分别部署到不同的 NPU卡上。
"moe_ep": 4, // Prefill实例或Decode实例的MOE EP配置"moe_tp": 4, // Prefill实例或Decode实例的MOE 配置
I 调度与资源管理:
使用 MindIE 的调度器协调Prefill和Decode阶段的任务分配。根据负载变化自动调整批处理大小(Batch Size),提升吞吐量。
"maxPrefillBatchSize": 4, // Prefill实例一个batch中包含请求个数的上限"maxPrefillTokens": 4096, // Prefill实例一个batch中包含input token总数的上限
I 拉起服务:
在当前目录执行如下命令拉起服务。观察服务日志 。
python3 deploy_ac_job.pybash log.sh

当MS Coordinator中出现“MindIE-MS coordinator is ready!!!”时,表示服务拉起成功。
3.性能监控与优化
使用 MindIE 的性能分析组件,实时监控各节点的负载、时延和吞吐量。
benchmark --DatasetPath $dataset_path--ModelName dsv3_w8a8 --ModelPath $weight_path --TestType openai --Http http://$ip:$port--Tokenizer True --MaxOutputLen 2048 --DatasetType gsm8k --WarmupSize 0--RequestRate 12 --Concurrency 2048 --SamplingParams'{"ignore_eos":true}' --WorkersNum 4 --TaskKind text --WarmupSize 0
可观察到如下的回显:
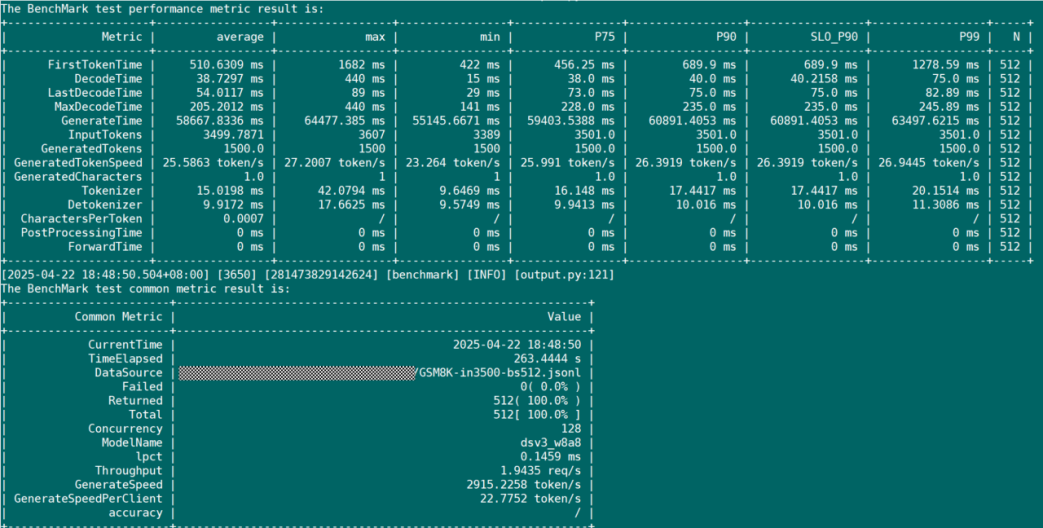
结语
昇腾PD分离技术通过对LLM推理过程中的计算密集型和访存密集型任务进行解耦,结合大规模专家并行方案,显著提升了系统性能和资源利用率,为用户实实在在地节约了成本,提升了业务的质量。这一技术不仅为大规模语言模型的高效推理提供了新的解决方案,也为AI算力的高效利用开辟了新方向。
未来,随着昇腾处理器在更多场景中的应用,PD分离技术将进一步释放LLM的潜力,为各行业带来更智能化、高效的AI体验。