



昇腾CANN 7.0 黑科技:大模型训练性能优化之道
发表于: 2023/10/20
Open AI研究表明:大模型表现好坏强烈依赖于模型规模,弱依赖于架构;模型表现随着计算量、数据量和参数量提升;模型表现随着训练数据量和参数量的提升是可预测的。总体来讲,大参数量、大数据量、大计算量已经成为大模型表现好的主要因素。
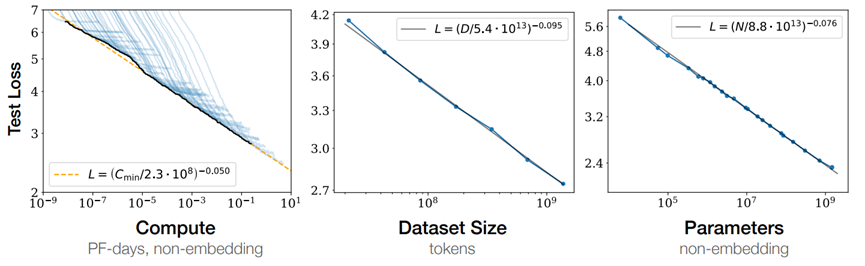
来源:OpenAI Scaling laws for neural language models
这样的趋势给大模型训练带来什么挑战呢?
首先是算力问题。1750亿参数量的GPT-3训练3000亿token,需要算力3.14e11 TFLOPs,千卡A100集群训练时长需要22天左右(算力利用率约为50%);1.8万亿参数的GPT-4模型,训练13万亿token,需要算力2.15e13TFLOPs,2.5万卡A100训练时长达到90~100天(算力利用率32%~36%)。
其次是显存容量问题。1750亿参数量的GPT-3预训练大约需要3TB内存,大模型训练在短序列长度时,模型参数是内存占用的主要部分,在长序列长度时,激活内存是主要部分。总体来说,随着序列增长,需要的内存越来越大。
最后是通信开销问题。大模型预训练的高算力和大内存诉求往往通过分布式集群scale out的方式应对,但这将带来相当大的通信开销。具体包括模型并行通信开销、数据并行通信拖尾开销、流水并行的通信开销,另外还有流水并行引入的bubble。通常情况下,通信耗时约占E2E耗时的10%~30%,当存在更大通信域时,通信占比会更大。
因此,大模型预训练需要解决三个核心问题:大模型可部署,在内存受限的AI加速卡[L1] 上放得下;充分发挥算力,提升计算效率,让训练流程更快;提升通信性能,降低通信开销,让计算更专注。
为了释放昇腾硬件算力,昇腾AI异构计算架构CANN发布更开放、更易用的CANN 7.0版本,全面兼容业界的AI框架、加速库和主流大模型,同时通过大颗粒算子深度融合、Kernel调度策略优化、通信并发流水等技术手段,解决大模型训练核心问题,使能大模型性能深度优化。
1 支持分布式切分策略+内存优化策略,让大模型放得下
学术界和工业界发明了很多大模型计算加速策略,包括最为经典的3D并行、序列并行、重计算、ZeRO系列的内存优化策略等等。通过这些并行策略,解决大模型放得下、训的快问题。基于昇腾AI处理器的多样算力和丰富的内存资源,异构计算架构CANN提供完备的技术栈功能,支持各种并行策略部署,也有很好的扩展能力,能支持新的并行算法和策略。下面来列举下在大模型训练中常用的计算加速策略:
- 3D并行(TP/PP/DP)

- 序列并行
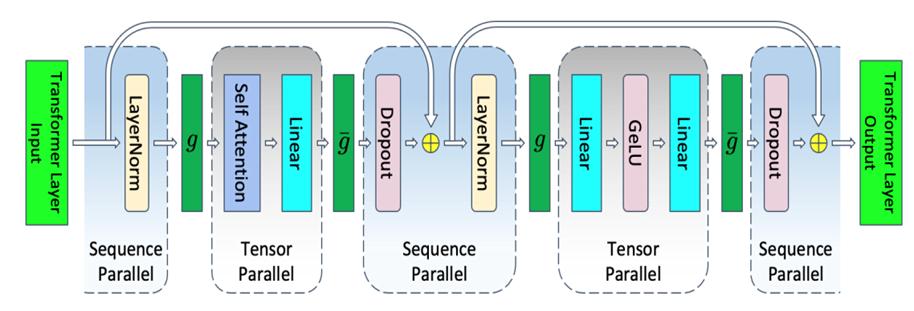
来源:Reducing Activation Recomputation in Large Transformer Models
- Checkpoint完全重计算
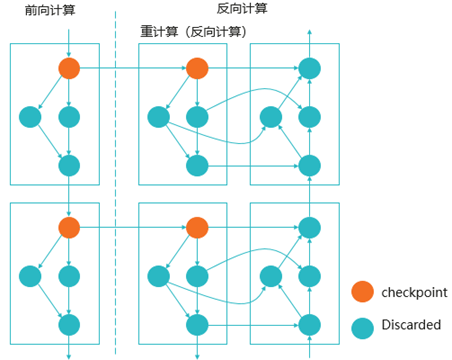
- 选择性重计算
Self-attention中的softmax和dropout算子计算结果占用内存大,但计算量相对少,不保留正向计算结果到反向,在反向计算流程可以重新计算softmax和dropout的结果。
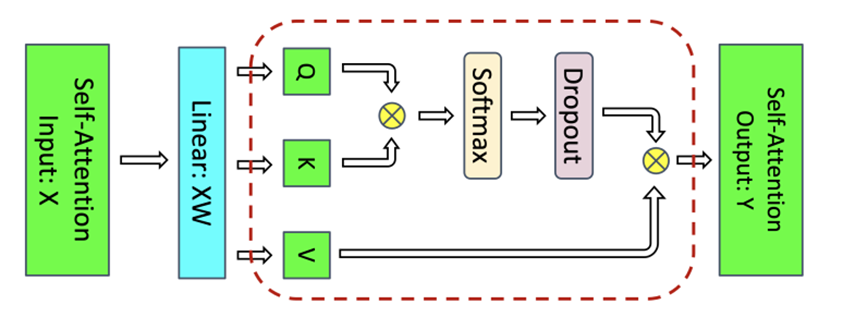
来源:Reducing Activation Recomputation in Large Transformer Models
- 内存优化:ZeRO1/2/3
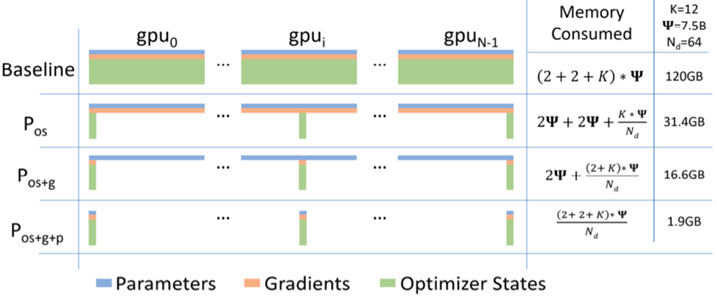
来源:ZeRO Memory
Optimizations Toward Training Trillion Parameter Models
2 充分发挥昇腾算力,提升计算效率,让模型跑得更快
在大模型计算优化方面,CANN通过高频算子优化、大颗粒算子融合、构建Transformer加速库等提升大模型计算效率。在调度方面,CANN通过执行器优化、算子Kernel重构等有效减少或避免host bound,提升算子在Host侧的下发性能。
1、高频算子优化,充分利用L1/L2 cache,发挥cube大算力
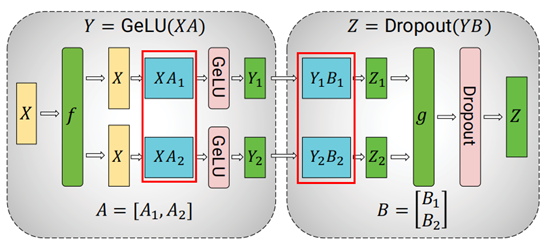
来源:Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
矩阵乘MatMul算子是大模型的高频算子,在GPT-3模型中,占60%以上的计算量。CANN通过算子tiling优化合理切分数据,通过算子流水优化使得数据搬运与计算流水并行,同时,通过cube与vector算子融合,减少内存使用,最终MatMul算子Cube利用率提升显著,性能达到业界先进水平。
2、Flash/Sparse Attention大颗粒算子融合,减少显存耗用,提升计算性能
CANN基于Ascend C编程语言开发了Flash/Sparse Attention算子,支持fp16、bf16、fp32多种数据类型计算,并支持8K及以上的长序列,在bloom、llama、gpt-3等大模型有很好的应用。相对稠密模型,CANN还针对MOE稀疏模型进行了重要的优化,通过MOE融合算子优化内存占用,并实现All-to-All通信与计算并发流水,大幅度提升性能。
3、构筑Transformer加速库提升核心Kernel性能,助力模型加速
基于Transformer,业界已经诞生了很多大模型,CANN针对这些模型进行泛化性分析,构筑Transformer加速库,主要包括FlashAttention、MOE FFN、Norm类等等,加速库为大模型训练保证了高性能下界,客户基于此可以快速改造写出性能更优的算子。

Transformer高性能库构建策略
4、高性能Kernel动态调度和下发,有效减少或避免host bound
大模型训练不仅要提升AI Core上算子的计算性能,也需提升算子在host侧的下发性能。若host侧下发算子不及时,可能会导致AI Core空闲等待,算力利用率降低(即host bound现象)。为此,CANN通过重构runtime执行框架,包括优化执行图,提供多种策略调度器,可根据模型结构特点选择最优调度策略,重构算子的Shape推导、tiling策略实现高性能Kernel,采用用户态直通device、Host2Device快速拷贝技术实现高性能kernel launch,多措并举使能Tiling和Launch性能倍增,有效减少或避免host bound。
3 降低通信开销,让计算更专注
大模型训练随着集群规模和通信域的增大,通信耗时占比升高,逐渐成为主要性能矛盾。提升通信性能、降低通信开销显得愈发重要。学术界和工业界发明了很多高性能通信算法,在此不一一介绍。下面介绍两个充分利用通信带宽的优化点 :
- 跨server all-reduce场景:SDMA&RDMA通信流水化
跨server实现all reduce一般分为四个阶段:server内reduce scatter、server间reduce scatter、server间all-gather,server内reduce
scatter,在同一时刻,server间链路和server内链路只有一个在工作,由此会造成带宽的浪费。将通信数据切片排布成流水,使server内和server间的链路并发利用起来,通过小步快跑方式节省通信耗时。
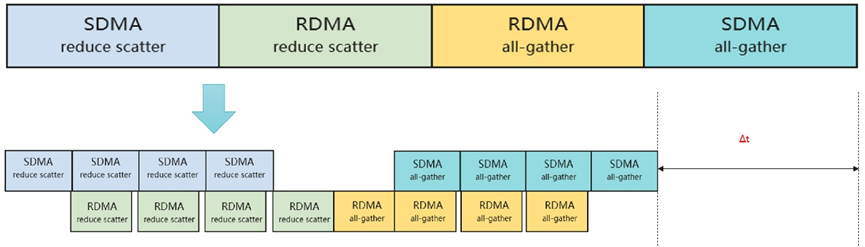
跨server all-reduce场景:SDMA&RDMA通信流水化
- 单server内all-reduce场景:TP通信复用RDMA带宽
单server内SDMA通信(比如all-reduce)时,server间的RDMA通信链路通常是空闲的。此时将数据按照一定比例切分,分别由server内SDMA通信、server间的RDMA通信同时传输,从而充分利用server内和server间的通信链路并发,提升通信性能。
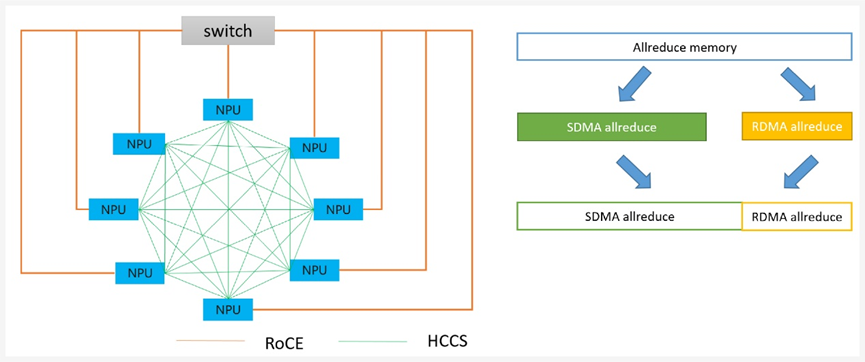
单server内all-reduce场景:TP通信复用RDMA带宽
4 总结
昇腾CANN借助根技术创新对大模型训练过程进行了系统级的优化加速,通过合理的分布式切分策略和内存优化策略,使大模型放得下;通过计算层、调度层和通信域的优化,使大模型跑得快,未来CANN也将持续研究、不断突破,以大模型赋能应用,加速千行万业智能化转型。