



一键抠除路人甲,昇腾CANN带你识破神秘的“AI消除术”
发表于: 2022/02/23
引语
旅途归来,重温美好却被秀丽河山前的路人甲搅乱了心情;街拍打卡,造型已凹竟被不远处几个垃圾桶抢占了C位;自拍臭美,表情到位但无奈于嘴角的痘痘太强势太出境…
此时,你心急如焚,多希望能一键抠去照片中的多余部分,不留痕迹。
救兵已来,接下来便是见证奇迹的时刻:https://www.hiascend.com/zh/developer/mindx-sdk/imageInpainting

都说人工智能改变了生活,你感觉到了么?AI的魔力就在你抠去路人甲的一瞬间来到了你身边。今天就跟大家聊聊——神秘的“AI消除术”。
基于昇腾CANN的图像消除应用
CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构,以提升用户开发效率和释放昇腾AI处理器澎湃算力为目标,凭借全场景、低门槛、高性能的优势,可满足用户全方位的人工智能诉求。
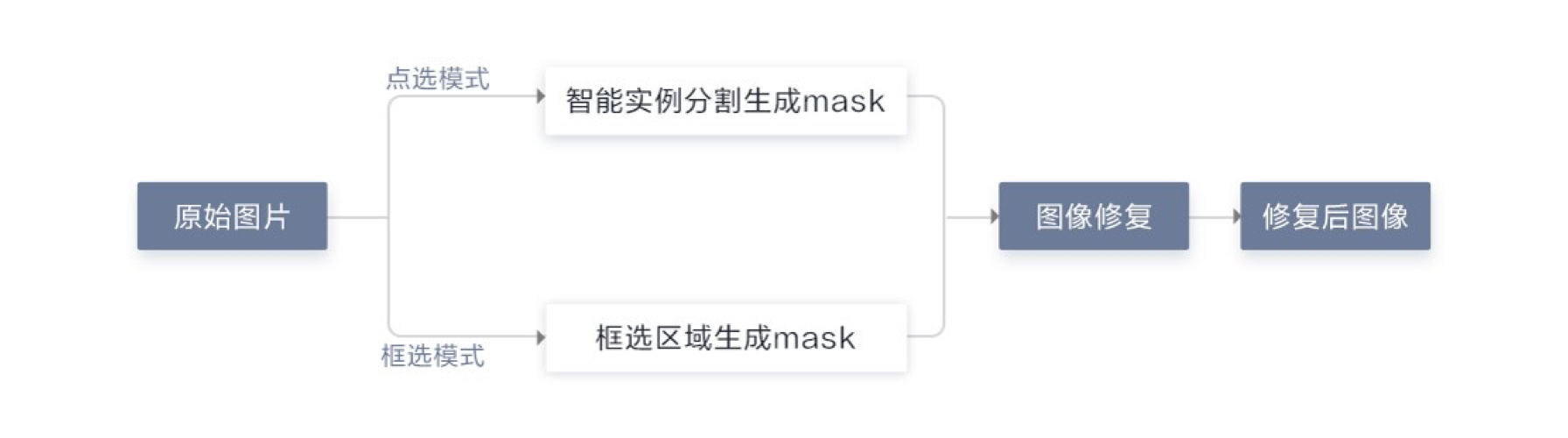
基于CANN开发图像消除应用更是轻而易举,这个应用中,我们实现了两种消除功能。
点选模式下,系统会对图像中进行自动识别和分割,用户直接选择待去除的目标:
<v:shape>
<v:imagedata>
</v:imagedata></v:shape> 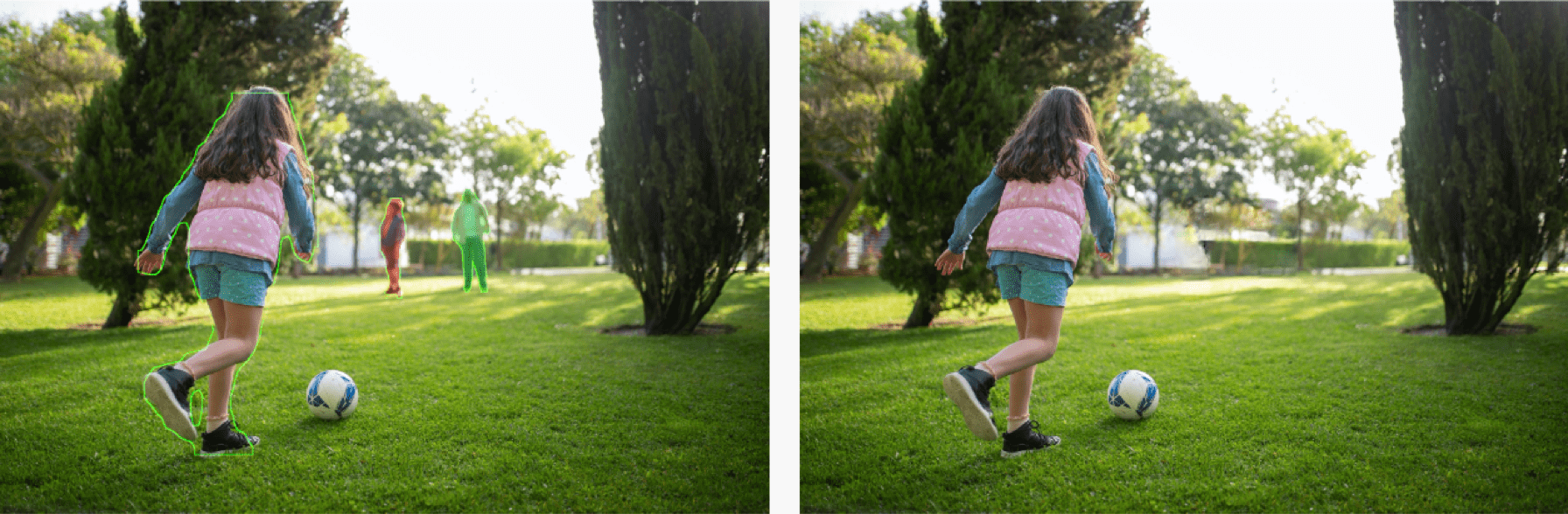
框选模式下,由用户手工框选待去除的目标:<v:shape> <v:imagedata> </v:imagedata></v:shape>

无论哪种模式,需要对相应区域进行图片修复,使整体看上去自然美观,因此整体逻辑结构如下所示:
<v:shape> <v:imagedata> </v:imagedata></v:shape>
智能实例分割,自动画出物体轮廓
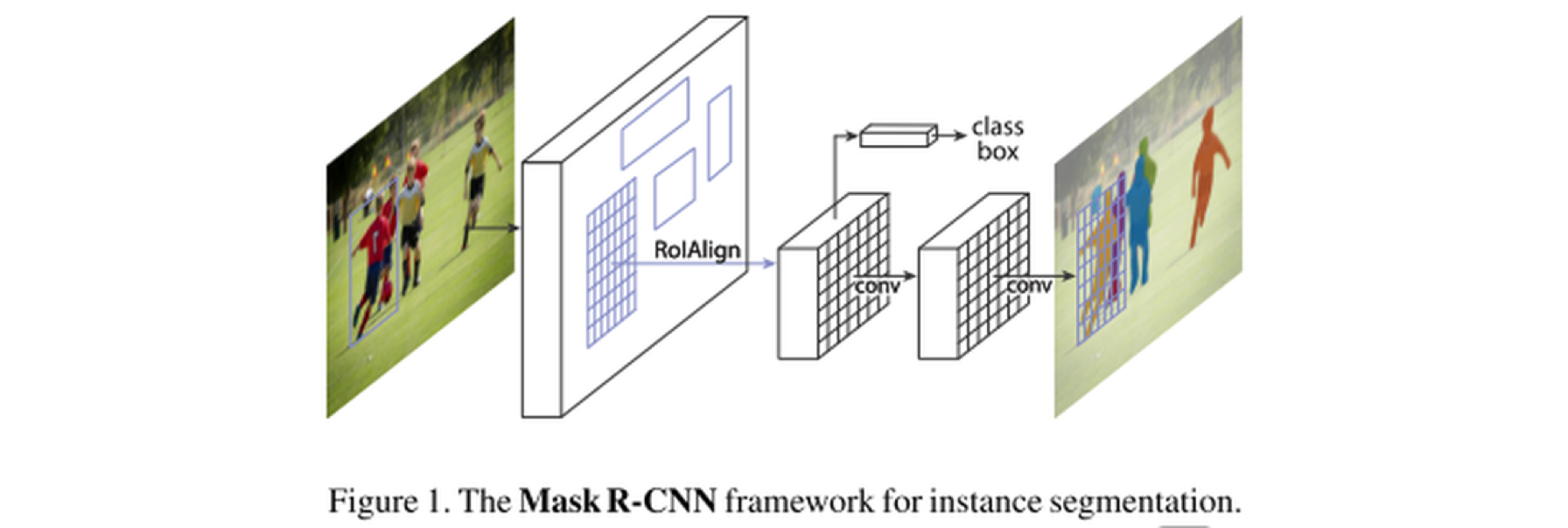
点选模式下,消除路人甲的关键是如何智能地将原图进行实例分割,借助实例分割算法MaskRCNN便能自动确定图片中各个目标的位置和类别,并且标识出目标物体的像素位置,画出物体轮廓(即mask区域)。

<v:shape> <v:imagedata> </v:imagedata></v:shape>
MaskRCNN是一种概念简单、灵活、通用的目标实例分割框架,在检测出图像中目标的同时,还为每一个实例生成高质量mask分割图。它其实是一个两级目标检测网络,第一部分扫描并提取图片特征并生成目标的建议区(即可能包含一个目标的区域);第二部分,在FasterRCNN模型基础上进行扩展,不仅能够预测种类,还可进行像素级分割,生成mask分割图。
<v:shape> <v:imagedata> </v:imagedata></v:shape>
图片出自https://arxiv.org/pdf/1703.06870.pdf
MaskRCNN模型使用的是COCO数据集训练的,所以支持80类物体的检测,本应用中主要针对人物进行消除,因此对识别目标做了选择,仅保留人物目标。感兴趣的小伙伴们也可以自己动手,根据想要识别的目标进行调整。
填补消除区域,使修复后的图像更自然
指定好待消除的mask区域后,还需要根据背景对消除的区域进行填充,最终生成自然清晰的图片。

<v:shape> <v:imagedata> </v:imagedata></v:shape>
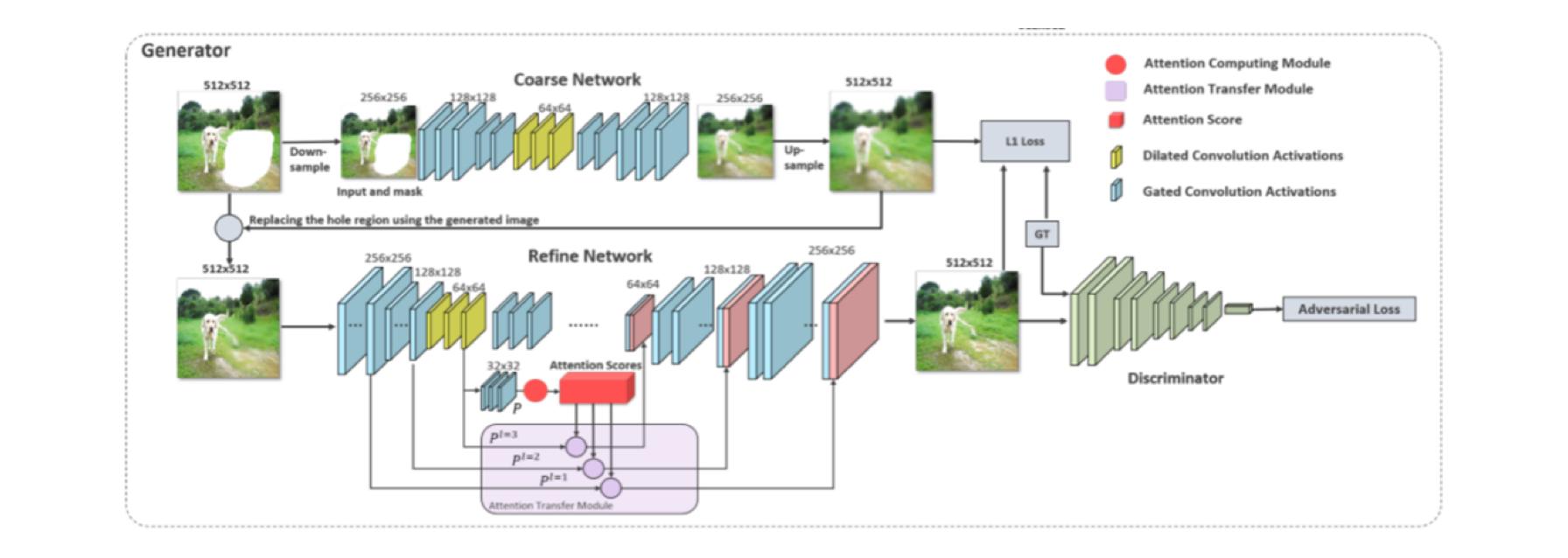
基于GAN模型的修复框架包括粗(Coarse network)和精(Refine network)两个自编码器网络架构。
<v:shape> <v:imagedata> </v:imagedata></v:shape>
上方部分是一个粗修自编码器,用来生成待修复部分的图像的大体轮廓,自编码器在训练时记录了大量的图像信息,即使图像部分缺失,也具有重建图像的能力。但自编码器生成的图像会模糊,这是自编码器的固有缺陷,因此需要再将该图像送入到第二阶的精修自编码器进行修复质量提升。
下方部分是一个精修自编码器,会对上面生成的Mask内的图像进行精细加工,使该区域图像变得清晰。该阶自编码器的原理是将图像切成一定数量的Patch(比如图中对大小为512*512的原始图像切成32*32个相同大小的Patch,那么每个Patch大小是16*16),并生成可以记录patch间相似度的注意力矩阵,注意力矩阵记录了图片中两两patch的相似度,修复mask内的图像其实就是利用注意力矩阵,将待修复的patch与mask外patch相似度作为权重,将mask外所有patch的特征与对应相似度加权求和之后的结果作为待修复的patch的特征,经过这样的操作后待修补的mask内的图像就能通过使用mask外的上下文信息得到精修,生成更清晰的图像。
在这个基础上,还可以对图片进行一步增强,使之更接近于真实图像。上述的两阶自编码器可作为GAN的生成器对图片进行清晰度增强,而判别器则尽可能地区分真实样本与生成样本,生成器和判别器在相互博弈的过程中不断提升自己,最终生成器能够生成真实清晰的图像。
借助CRA算法实现高清修复
以往由于内存限制,基于GAN模型数据驱动的图像修复方法通常只能处理小于1k(1920*1080)的低分辨率输入,而目前主流相机拍照几乎都已经超过了4k,单纯对低分辨率修复后的结果进行上采样,只会产生较大但是模糊的结果,根本无法达到高清修复的效果。
Qiang Tang等人提出借助CRA算法(Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting)实现高清修复。首先由GAN的生成器得到低分辨率的修复好的图像,然后通过残差聚合模块先得到高频残差即图片的细节,再对图片修复区域的细节进行增强,最后将增强的细节叠加到生成器输出的图片的修复区域得到高清修复的图像,最终的效果也相当惊艳。

简单来说,就是用图像锐化的原理对图像修补的区域做进一步增强,即用平滑的模糊图像再加上图像的细节就能得到锐化后的清晰图像,主要分为如下两步:
1、 锐化处理首先需要获取图片的细节,通常图像的细节可以由原图减去经过平滑处理的模糊的图片得到,这里平滑的图片是将图片先下采样再上采样处理得到的;
2、 得到mask区域内细节图后不能直接使用,需要利用mask区域外的上下文信息再进一步增强细节图片的mask内区域图片,具体为:把细节图片分成32*32个patch,再利用上面得到的注意力矩阵,加权求和mask外的细节特征得到mask内的细节,修复后的mask内细节区域的图片再拼接到修复后图像对应的mask内的区域,得到清晰的修复区域的图片,最后再将以上处理修复后的图片mask内区域与原图mask外的区域合并组成一张完整的清晰自然的图像。
庞大的运算量,交给昇腾CANN来加速
以上过程中,我们不难发现,无论是MaskRCNN实例分割,GAN图像修复,还是CRA算法的大矩阵乘操作,都是非常耗时的运算。例如CRA算法中的矩阵乘计算,针对每个需要修复的像素,需要取32*32个patch中的对应像素值与1024个概率值乘加得到,如果图像尺寸是(3072,3072,3),那么我们可以估算一下它背后的计算量:1024 * 3072 * 3072 * 3 = 28991029248 = 0.28T!就算是只计算 mask 内的必要元素,但却需要多次判断该像素是否在 mask 内,所以在 CPU 上计算将非常慢,大家可以试一下。
借助昇腾310 AI处理器的强大的矩阵乘能力可对这部分运算进行加速。将注意力矩阵作为左矩阵(1024 * 1024);将32 * 32个patch中的每一个像素取出来作为一列,因为每个patch是96行96列(3072 / 32=96)3通道,所以总共是96 * 96 * 3=27648列,所以最终是27648列的一个矩阵作为右矩阵(1024 x 27648)参与计算,通过numpy的reshape和transpose等操作就可以实现从3072 x 3072 x 3到1024 x 27648的转换。。
同时,通过异构计算架构CANN的软硬件协同优化,能进一步释放昇腾AI处理器的澎湃算力,提升整个处理效率。CANN对上支持多种AI框架,对下服务AI处理器和编程,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台。通过CANN软件栈对硬件资源的充分调度,可实现对网络模型进行图级和算子级的编译优化、自动调优等功能,快速完成任意mask形状的高清图像修复功能,即使对于4K图像也能达到秒级修复。
高效易用的编程接口,助力开发者快速构建AI应用
CANN不仅能充分释放昇腾AI处理器澎湃算力,带给用户“飞”一般的极致性能体验,还针对多样化应用场景,提供了高效易用的AscendCL编程接口,屏蔽底层处理器差异,让开发者无需关心计算资源优化的问题,便能轻松开发深度神经网络推理应用,从而快速构建基于昇腾平台的AI应用和业务。
我们借助AscendCL编程接口,采用下图所示的模块化设计,通过各模块之间的协调配合完成图片修复工作,下图是本应用在昇腾310上部署的主要流程。
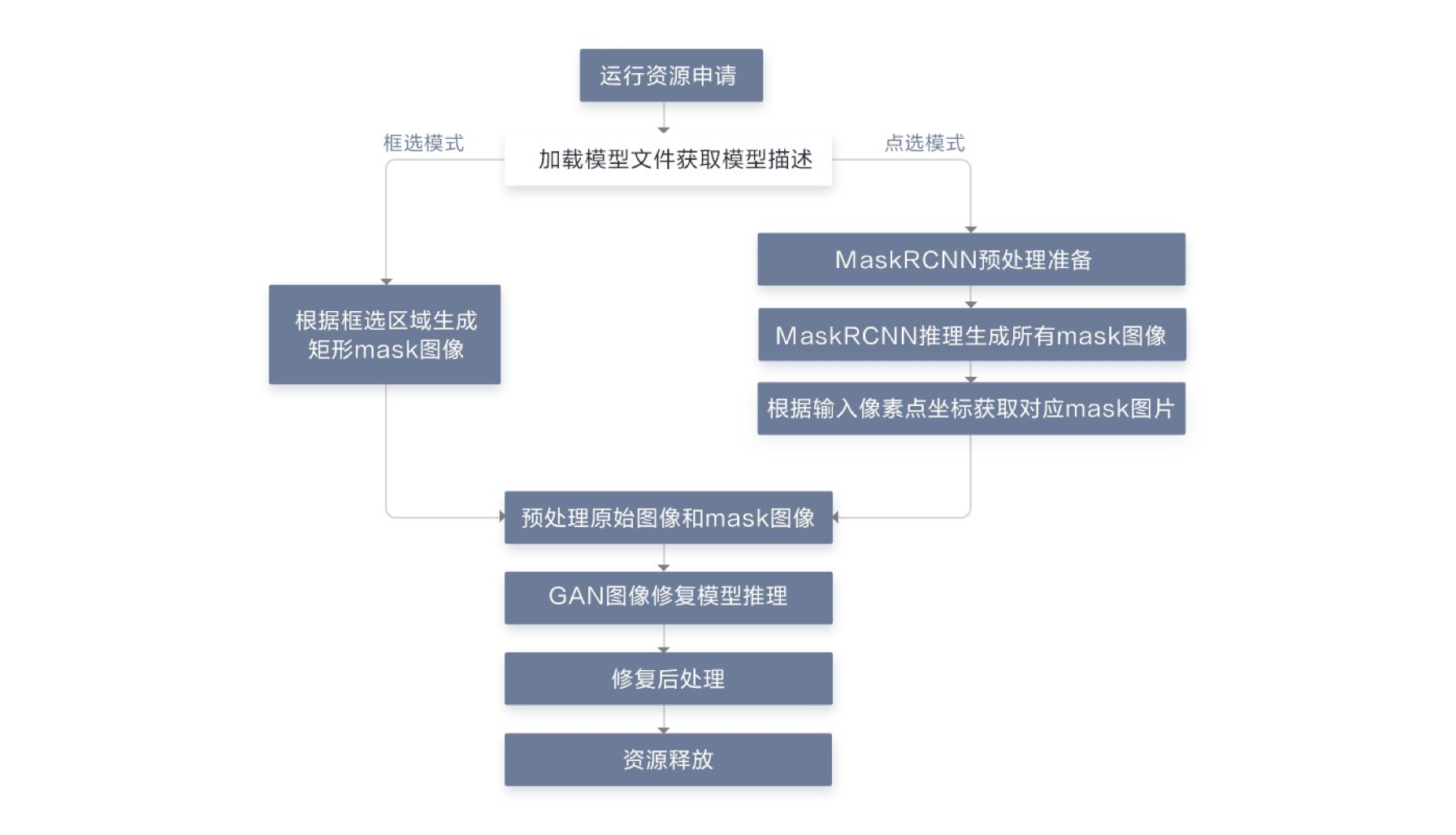
<v:shape> <v:imagedata> </v:imagedata></v:shape>
其中各个模块的主要功能点:
1. 运行管理资源申请。
2. 加载模型文件,构建模型输出内存。
3. 如果是框选模式,通过标记框获取要进行推理的原始图像和Mask图像;如果是点选模式,需要先进行MaskRCNN图像预处理(缩放),然后经过MaskRCNN推理生成目标mask,接着根据输出像素点坐标获取对应区域的mask数据。
4. GAN图像修复之前,需要对输入图像进行预处理操作。
5. GAN图像修复模型推理,将数据输入到模型进行推理得到修复后的图像。
6. 得到经过GAN模型修复后的图像和注意力矩阵后,进行修复后处理,使修复区域图像更清晰。
7. 运行管理资源释放。
具体实现时,AI图像修复预处理部分首先使用OpenCV读取原图和Mask图,将原图和Mask图进行大小缩放,缩放至3072*3072大小,之后再将原图像和Mask图像缩小到512*512用于送入模型进行推理,之所以将图片缩小后送入模型推理是为了节省算力和内存空间,加速推理时间;将读取到的图像数据拷贝至设备侧申请的内存空间中,为接下来构建模型输入数据做好准备。最后分别得到3072*3072和512*512的图片和Mask图。
而后处理部分比较复杂,主要是对模型生成器修复的图像做进一步增强,增强方式是采用了图像锐化的原理,首先利用注意力矩阵对细节图片的修复区域内做进一步加工,使得细节图片包含更丰富的信息,再将此细节图片叠加到模型输出的图片上,最后再将以上处理修复后的图片mask内区域与原图mask外的区域合并组成一张完整的清晰自然的图像。
在线体验
源码就不详细解析了,登陆昇腾社区,通过以下三步曲可以完成深度体验甚至是二次开发。
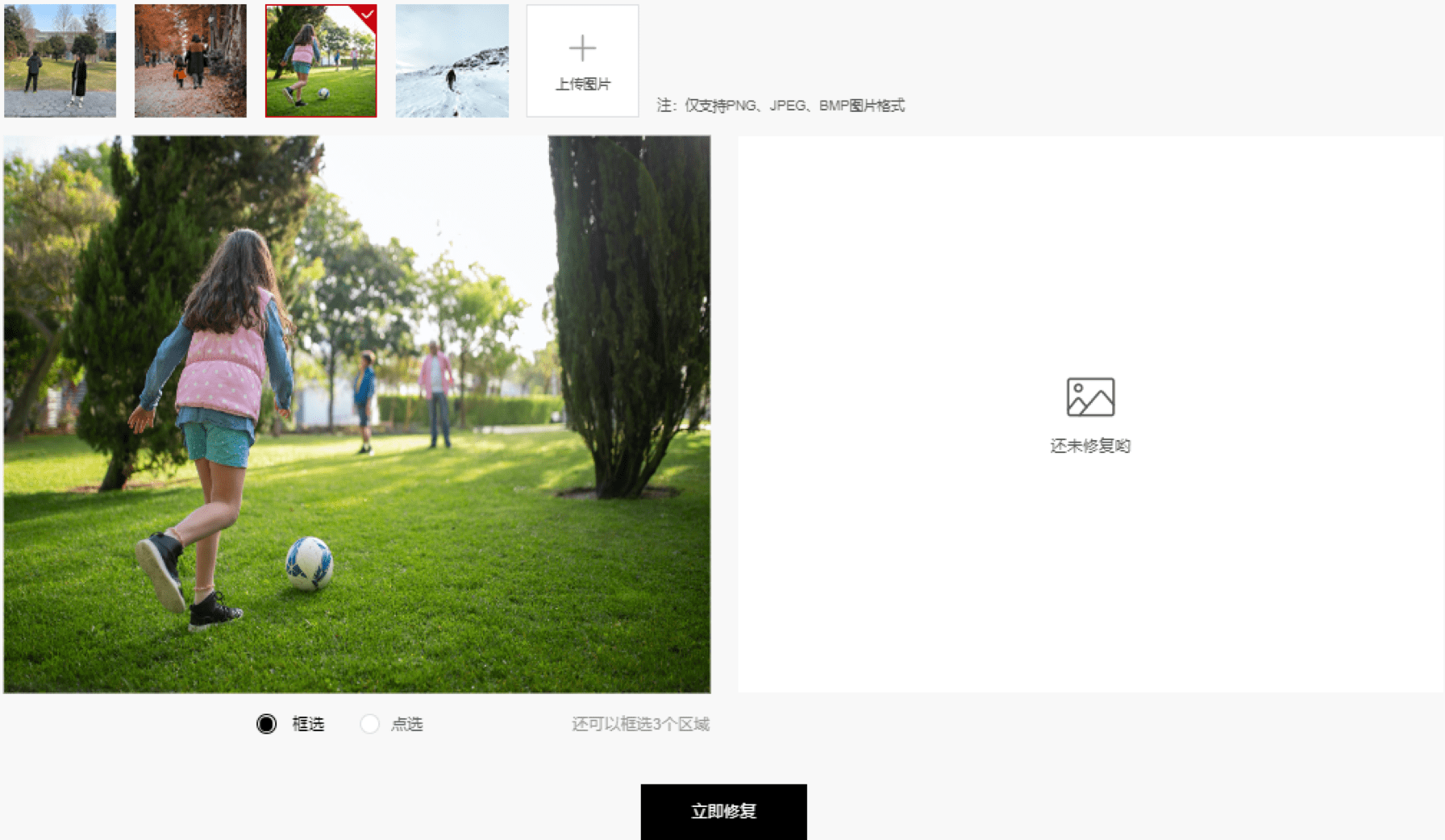
第一步:点击“立即修改”在线体验效果
https://www.hiascend.com/zh/developer/mindx-sdk/imageInpainting?fromPage=1
<v:shape> <v:imagedata> </v:imagedata></v:shape>
第二步:点击“在线实验”了解整个开发流程。

<v:shape> <v:imagedata> </v:imagedata></v:shape>
第三步:点击“gitee”进入项目开源仓获取源码进行深度学习或者二次开发。
昇腾CANN“图像消消消”体验活动火热报名中,通过“玩”、“学”、“练”、“写”,可快速熟悉并掌握高清图像修复基本开发流程,完成任务还有大奖等你来拿。
<v:shape> <v:imagedata> </v:imagedata></v:shape>
相关链接:
GAN图像修复模型论文参考链接如下:
Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting
GAN图像修复原始模型部署链接如下:
Image Inpainting Project based on CVPR 2020 Oral Paper on HiFill
MaskRCNN实例分割原始模型链接如下:
https://www.hiascend.com/zh/software/modelzoo/detail/C/5b5232e55ca04b81af264d9600cc8bd3
MaskRCNN实例分割相关参考链接如下:
https://arxiv.org/pdf/1703.06870.pdf
https://blog.csdn.net/wangdongwei0/article/details/83110305/
https://blog.csdn.net/qq_37392244/article/details/88844681
相关源码可以从昇腾开源仓中获取:
应用案例可以到昇腾社区在线体验:
https://www.hiascend.com/zh/developer/mindx-sdk/imageInpainting?fromPage=1